 Español
Español English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 en todos los servicios de hosting
en todos los servicios de hostingAloja Ollama en un servidor LLM y toma el control sobre la censura de la IA
Palabras clave
Antes de comenzar la configuración, aquí se presentan los términos que probablemente confundan a los lectores en esta guía. Este breve glosario mantiene el vocabulario de Linux, GPU y modelos locales claro desde el principio.
| Palabra clave | Breve explicación |
|---|---|
| 🤖 LLM | Modelo de lenguaje grande; un modelo de IA que genera texto a partir de instrucciones. |
| 🦙 Ollama | Un ejecutor y servidor de modelos locales para descargar, servir y llamar a LLMs en tu propia máquina. |
| 🖥️ GPU | El procesador gráfico utilizado aquí para acelerar la inferencia del modelo. |
| 💾 VRAM | La memoria de la GPU; es uno de los principales límites sobre qué tan grande puede ser un modelo para caber en una tarjeta. |
| ⚡ Inferencia | El acto de ejecutar un modelo para generar una respuesta. |
| 🔄 systemd | El gestor de servicios de Linux utilizado para iniciar, detener, reiniciar y habilitar servicios como Ollama. |
| 🧩 Controlador NVIDIA | La capa de software que permite a Ubuntu comunicarse correctamente con la GPU NVIDIA para cargas de trabajo de cómputo. |
| 🚫 nouveau | Un controlador gráfico de Linux de código abierto que puede impedir una configuración de cómputo NVIDIA adecuada si se utiliza en lugar del controlador oficial de NVIDIA. |
| 📊 nvidia-smi | La herramienta de línea de comandos de NVIDIA para verificar la visibilidad de la GPU, el uso de VRAM y el estado del controlador. |
| 🔌 Endpoint de API | Una URL que las herramientas o scripts llaman para enviar instrucciones a Ollama y recibir respuestas. |
| ☁️ Capa de servicio controlada por el proveedor | La capa de API gestionada por el proveedor que puede agregar moderación, registro, aplicación de políticas u otros controles antes de que un modelo responda. |
| 🧬 Ajuste fino | Una versión modificada de un modelo base ajustada para un tono, comportamiento o tareas de propósito especial diferentes. |
| ⚖️ Pesos del modelo | Los parámetros internos aprendidos del modelo; el autoalojamiento no los cambia automáticamente. |
| 📝 Modelfile | Un archivo de Ollama utilizado para crear una variante de modelo local personalizada con tu propio mensaje del sistema y parámetros de ejecución. |
| 🪪 UUID | Un identificador de hardware estable para una GPU; a menudo es más seguro que los IDs numéricos de GPU porque el orden de los dispositivos puede cambiar. |
| 🔒 TLS | El cifrado utilizado por HTTPS y proxies inversos para asegurar el tráfico entre clientes y el servidor. |
| 🌐 Proxy inverso | Un servicio frontend que puede agregar TLS, autenticación y acceso público controlado antes de reenviar solicitudes a Ollama. |
| 🎛️ Temperatura / semilla | Configuraciones de generación; la temperatura afecta la aleatoriedad, mientras que una semilla fija ayuda a hacer que las pruebas repetidas sean más comparables. |
| 🧱 Desbordamiento a CPU / ruta mixta | Una situación en la que parte del modelo o la carga de trabajo cae fuera de la memoria de la GPU y utiliza recursos de CPU, lo que puede ralentizar la inferencia. |
| 🔧 nvidia_uvm | Un módulo del kernel de NVIDIA relacionado con la gestión de memoria de la GPU que a veces necesita recargarse durante la solución de problemas. |
Por qué vale la pena el autoalojamiento de un LLM

Si ya has hecho la parte difícil — alquilar el servidor GPU, instalar Ubuntu, aprender a manejar SSH y mantener tus propios servicios en funcionamiento — se vuelve frustrante rápidamente cuando una IA alojada todavía controla el último tramo. Puede rechazar una solicitud perfectamente ordinaria, enterrar la respuesta bajo advertencias, cambiar el estilo de respuesta sin previo aviso y mantener cada instrucción fluyendo a través de los límites de otra persona. Para muchos usuarios técnicos, esa es la verdadera frustración: no solo lo que dice el modelo, sino quién controla la capa de servicio cuando lo dice.
Esta guía trata de solucionar eso con modelos abiertos y locales, no de trucos para eludir APIs propietarias. Autoalojarás Ollama en un servidor Ubuntu con GPU, ejecutarás la inferencia localmente, verificarás que la ruta GPU es real y verás qué cambia cuando eliges una familia de modelos diferente. Un error conceptual que conviene aclarar desde el principio: autoalojado no significa automáticamente sin restricciones. Significa que controlas mucho más de la pila — y dejas de depender de una ruta de servicio controlada por el proveedor — pero el modelo que ejecutas puede seguir teniendo su propio comportamiento de alineación.
📝 Nota: Los comandos de esta guía están validados con la documentación actual de Ollama, pero las salidas de terminal que se muestran a continuación son ejemplos representativos en lugar de capturas de referencia en tiempo real. Úsalos como patrón de éxito, no como una afirmación de rendimiento.
Al final, tendrás un servicio Ollama funcional en Ubuntu, una API local verificada en 127.0.0.1:11434, prueba de que la inferencia respaldada por GPU está ocurriendo realmente, y una comparación fundamentada entre un modelo alineado convencional y una alternativa menos restringida. Este tutorial está escrito para lectores que se sienten cómodos con SSH, Ubuntu, sudo y systemd, pero que no necesitan experiencia previa con Ollama.
El servidor Ubuntu GPU exacto utilizado para esta guía

Este tutorial está anclado en una máquina Ubuntu real de una sola GPU, porque los consejos vagos del tipo “debería funcionar en la mayoría de los servidores” es como las guías de autoalojamiento se vuelven engañosas. La máquina de referencia aquí es la clase de host real utilizada para esta guía: el tipo de máquina que un individuo avanzado, laboratorio o equipo pequeño realmente alquilaría cuando desea inferencia local privada sin saltar directamente a un rack de aceleradores empresariales. También se discutirá el comportamiento multi-GPU más adelante, porque Ollama cambia una vez que un modelo supera una tarjeta, pero trata esa parte como contexto orientado al futuro en lugar de prueba de este servidor exacto.
Servidor GPU — Ryzen 9 3950X + RTX 4070 Ti Super
| Componente | Detalles |
|---|---|
| CPU | AMD Ryzen 9 3950X (16 núcleos / 32 hilos) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| Capacidad | Potente para modelos de clase 8B; los modelos más grandes se convierten en decisiones de desbordamiento o actualización |
En la práctica, esta es una configuración muy potente para los modelos de clase 8B de uso diario y sigue siendo útil para trabajo local más grande hasta el punto donde los 16GB de VRAM se convierten en la verdadera restricción. Un modelo como llama3.1:8b con aproximadamente 4,9GB cabe fácilmente en esta tarjeta. Un modelo como gpt-oss:20b con aproximadamente 14GB es el tipo de prueba de una sola GPU de gama alta que todavía tiene sentido aquí. Un modelo como qwen3:30b con aproximadamente 19GB se trata mejor como un punto de referencia para lo que cambia en un host más grande o de doble GPU que como una opción adecuada para esta máquina exacta.
Esa distinción importa porque el objetivo de este artículo no es encajar el número más grande posible en un titular. Es mostrar cómo se ve un servidor LLM autoalojado sensato cuando deseas privacidad, control local y suficiente memoria GPU para ejecutar modelos útiles sin compromisos constantes. Esta clase de hardware es donde la inferencia autoalojada se vuelve realista, no teórica.
También explica algunas elecciones que verás más adelante: mistral se usa primero porque ofrece una prueba rápida y sin fricciones de que la pila funciona, mientras que la comparación de comportamiento se mantiene en la clase 8B donde esta máquina es cómoda. qwen3:30b sigue apareciendo más adelante, pero como ejemplo teórico del tipo de modelo que puede activar la colocación multi-GPU en un host más grande en lugar de como prueba en vivo de este servidor. Con las expectativas establecidas, el siguiente paso es validar el host antes de que Ollama lo toque.
Realiza estas verificaciones previas a la instalación antes de tocar Ollama

Comienza con nvidia-smi. Si este comando no está disponible o falla, detente ahí y soluciona primero el controlador de NVIDIA. No instales Ollama todavía, porque una pila de NVIDIA defectuosa hará que cada síntoma posterior parezca un fallo de la aplicación cuando en realidad es un fallo de la plataforma.
Ejecuta primero la verificación de GPU:
nvidia-smi
❗Si Ubuntu indica que nvidia-smi no está disponible, no asumas que el servidor no tiene GPU. Un modo de fallo común en máquinas Ubuntu alquiladas es que la tarjeta está presente pero todavía vinculada a nouveau en lugar del controlador de NVIDIA. Consulta primero la sección “Solucionar el problema del controlador Nvidia en Ubuntu“.
Un resultado correcto en esta clase de servidor debería verse aproximadamente así:
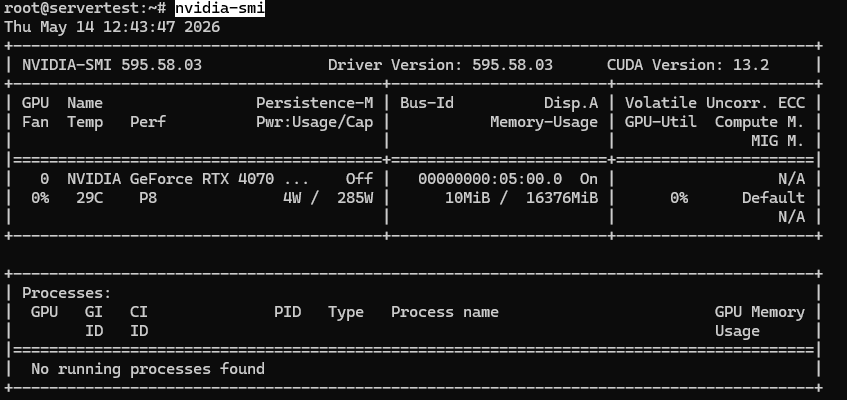
Una vez que nvidia-smi funcione y la GPU sea visible, continúa con las verificaciones a continuación.
Lo que quieres confirmar es simple: la GPU instalada es visible, reporta aproximadamente 16GB de VRAM en este host, y el controlador está cargado correctamente. Si estás en un servidor multi-GPU, el mismo comando debería listar cada tarjeta.
nvidia-smi -L

❗ Importante: La documentación actual de soporte GPU de Ollama utiliza el controlador NVIDIA 531+ como el piso real para la inferencia NVIDIA compatible. Trata 531+ como el requisito para esta guía, incluso si has visto notas antiguas de la comunidad citando versiones más bajas.
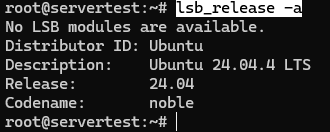
Ahora confirma que el host es realmente el entorno Ubuntu que esta guía asume:
lsb_release -a
Finalmente, verifica el espacio libre en disco antes de comenzar a descargar modelos. La instalación en sí es pequeña; los modelos no lo son. Una vez que vayas más allá de las pruebas pequeñas, una biblioteca de 20B a 30B puede consumir decenas de gigabytes rápidamente, por lo que tener más de 100GB libres es la mentalidad correcta antes de trabajar con modelos locales en serio.
df -h /

Si estas verificaciones pasan, has despejado las principales incógnitas de infraestructura: las GPUs están presentes, la línea base del controlador es correcta, Ubuntu está confirmado y el disco tiene espacio para descargas reales de modelos. Ese es el punto donde instalar Ollama se convierte en un siguiente paso limpio en lugar de una suposición.
Solucionar el problema del controlador Nvidia en Ubuntu
Sigue los pasos a continuación para solucionar problemas con el comando “nvidia-smi”.
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
Si esa salida muestra una tarjeta NVIDIA y una línea como Kernel driver in use: nouveau, instala el paquete de controlador recomendado de Ubuntu en lugar de instalar solo nvidia-utils.
Instala el paquete ubuntu-drivers-common (necesario para la gestión de controladores) y los encabezados del kernel para tu kernel en ejecución actual.
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)Analiza tu sistema y lista los controladores propietarios disponibles (por ejemplo, controladores GPU de NVIDIA) que se pueden instalar.
ubuntu-drivers devices
Luego instala el paquete de controlador recomendado. En nuestro caso fue: nvidia-driver-595-open:
apt install -y nvidia-driver-595-open
rebootDespués del reinicio, vuelve a ejecutar:
nvidia-smi
nvidia-smi -LInstalar Ollama y confirmar que el servicio está funcionando correctamente

La ruta de Ubuntu compatible es el instalador oficial de Ollama, no un flujo de tarball personalizado ni un desvío por Docker. Eso importa porque esta guía trata de obtener un servicio local confiable con valores predeterminados predecibles, integración con systemd y un comportamiento de propiedad sensato en Linux.
Ejecuta el instalador exactamente como está documentado:
curl -fsSL https://ollama.com/install.sh | sh
En un sistema saludable, el script instala el binario, crea el usuario de servicio ollama, agrega las membresías de grupo correctas cuando están disponibles, escribe la unidad de systemd e inicia el servicio vinculado a 127.0.0.1:11434.
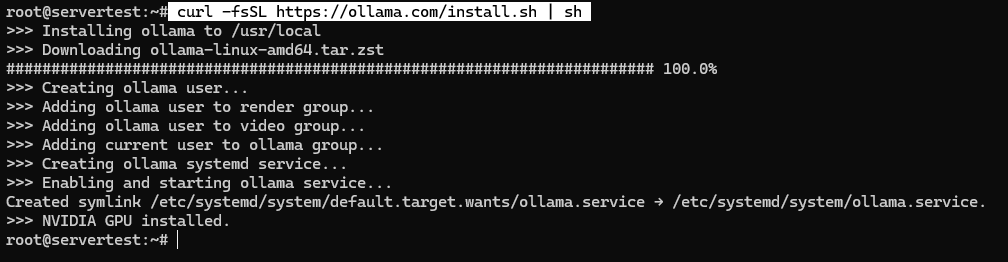
Una vez que el script finalice, valida el servicio en lugar de asumir el éxito:
sudo systemctl status ollama --no-pager
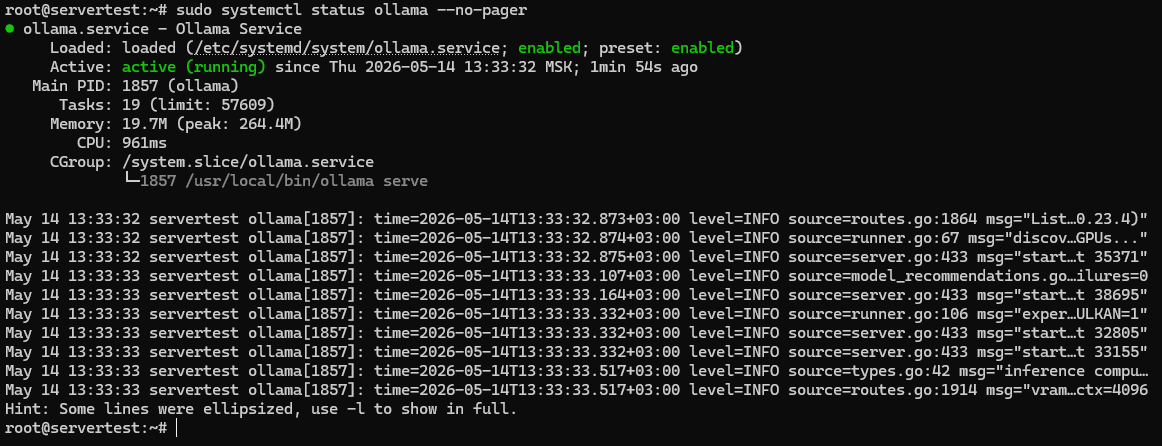
Estás buscando tres cosas aquí: el archivo de unidad está presente, el servicio está habilitado para el arranque y Active: active (running) confirma que el servidor está realmente en funcionamiento.
Primero, establece la cuenta de usuario del servicio de Linux de manera concreta, y solo después piensa en cómo y dónde se gestionará el almacenamiento del modelo.
getent passwd ollama

Esa única línea explica mucho del comportamiento futuro. Los modelos en Linux viven bajo la propiedad del servicio, y si más adelante los mueves a otro disco sin corregir los permisos para el usuario ollama, crearás tus propios problemas.
Una verificación más cierra el ciclo sobre el enlace predeterminado:
ss -tlnp | grep 11434

⚠️ Advertencia: Ollama no requiere autenticación en la API local de forma predeterminada. Eso está bien cuando está vinculado a 127.0.0.1, pero no es seguro exponer el puerto 11434 directamente a Internet como si fuera un servicio público reforzado.
Si el servicio no se inicia correctamente, ve primero a los registros en lugar de reinstalar a ciegas:
journalctl -u ollama -n 100 --no-pager
Esa es la forma más rápida de detectar problemas de permisos, errores de inicio, problemas de detección del controlador o problemas de enlace. Una vez que el servicio esté funcionando correctamente en localhost, lo siguiente que hay que entender es cómo se comporta la colocación de GPU en tiempo de ejecución.
Cómo Ollama realmente usa una o múltiples GPUs
Aunque el servidor utilizado para esta guía tiene una sola GPU, el comportamiento multi-GPU sigue valiendo la pena entenderlo porque muchos usuarios pueden estar en máquinas más grandes o pueden expandirse más adelante. Mucha confusión con dos GPUs comienza con la expectativa incorrecta: “Tengo dos tarjetas, así que ambas deberían activarse todo el tiempo.” Así no funciona Ollama. La regla práctica es mucho más simple: si un modelo cabe en una GPU, Ollama generalmente lo mantendrá en una GPU. Solo se distribuye entre múltiples GPUs cuando el modelo no cabe cómodamente en una sola tarjeta.
Usa estas dos verificaciones juntas siempre que quieras ver el rendimiento de la GPU:
ollama ps
watch -n 1 nvidia-smi
ollama ps te indica cómo se está procesando el modelo cargado. 100% GPU significa que el modelo reside completamente en la memoria GPU. 100% CPU significa que la aceleración GPU no se está utilizando. Un estado mixto indica que alguna parte de la carga de trabajo o residencia se desbordó fuera de la ruta GPU. watch -n 1 nvidia-smi complementa eso mostrando el uso de VRAM en tiempo real por tarjeta mientras el modelo está cargado.
La forma más rápida de mantener claros esos roles es esta:
| Comando | Lo que prueba | Lo que no prueba |
|---|---|---|
| ollama ps | Si el modelo se está ejecutando en GPU, CPU o una ruta mixta | Qué tarjeta o tarjetas exactas están llevando la carga |
| watch -n 1 nvidia-smi | Actividad de VRAM en tiempo real por GPU | Si el uso de doble GPU significa automáticamente una mejor elección de modelo |
📝 Nota: CUDA_VISIBLE_DEVICES es un control de visibilidad, no un interruptor de “usar ambas GPUs”. Si alguna vez necesitas restringir el acceso a la GPU, prefiere los UUIDs de nvidia-smi -L sobre los IDs numéricos porque el orden de las GPUs puede variar entre entornos y reinicios.
Ejecuta tu primer modelo local y verifica la inferencia GPU
En este punto, no necesitas un modelo gigante para probar que el servidor funciona. Necesitas un éxito rápido y honesto. mistral es una buena primera descarga porque es pequeño, rápido de descargar y fácil de cargar, aunque llama3.1:8b será la línea base posterior para la comparación de comportamiento.
Comienza descargando el modelo:
ollama pull mistral

Ahora ejecuta una instrucción pequeña para que la máquina haga algo útil, no solo administrativo. La respuesta puede tardar unos segundos.
ollama run mistral "In one sentence, explain why people self-host LLMs."

Para probar que esta es una inferencia respaldada por GPU en lugar de un retroceso a CPU, verifica el estado de ejecución:
ollama ps

Y para ver lo que ya está en disco, lista el inventario local:
ollama list

mistral es la primera prueba correcta porque te da una respuesta rápida sin convertir la validación de configuración en una larga espera. Más adelante, llama3.1:8b se vuelve más útil porque es una línea base alineada más sólida para comparar el comportamiento del modelo.
Finalmente, verifica dónde está almacenando los modelos la instalación de Linux:
sudo du -sh /usr/share/ollama/.ollama/models

Esa ruta — /usr/share/ollama/.ollama/models — es el almacén de modelos estándar de Linux documentado por Ollama.
Una vez que veas una respuesta exitosa, 100% GPU en ollama ps y el uso de disco aumentando en la ubicación esperada, tienes la primera prueba significativa de que la pila local funciona.
Demuestra que es un servidor, no solo un contenedor CLI

Una instrucción en línea de comandos está bien, pero la razón para autoalojar Ollama no es solo chatear dentro de una terminal. Es ejecutar un servidor de inferencia local que otras herramientas, scripts y aplicaciones puedan llamar sin enviar instrucciones a través del límite de API de otra persona. La prueba más rápida es una solicitud HTTP limpia al endpoint nativo de Ollama.
Envía una solicitud de generación local con el streaming desactivado para que la primera respuesta sea fácil de inspeccionar:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'Una respuesta exitosa debería volver como JSON y verse aproximadamente así:
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
La lista de verificación de éxito es sencilla: la solicitud HTTP funciona localmente, el JSON válido regresa, done: true está presente y la respuesta del modelo está en response. Ese es el punto donde Ollama deja de ser “un CLI que descarga modelos” y se convierte en infraestructura que puedes integrar realmente en herramientas locales y automatización.
Si quieres compatibilidad con software que espera una forma de solicitud al estilo OpenAI, Ollama también expone endpoints /v1 localmente:
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 Nota: Esa etiqueta “compatible con OpenAI” es fácil de malinterpretar. No significa que estés hablando con OpenAI, y no cambia el hecho de que el servidor sigue siendo local. Solo significa que la forma de la solicitud es lo suficientemente familiar para herramientas y SDKs construidos alrededor del patrón de API de OpenAI. La URL base sigue siendo http://localhost:11434/v1/, y cualquier clave API de marcador de posición en la que insistan algunas bibliotecas cliente puede ignorarse para el uso local de Ollama.
De dónde vienen realmente las restricciones del modelo

Esta es la parte que generalmente se simplifica en una sola idea vaga de “censura”, pero técnicamente hay tres capas diferentes involucradas: la capa de servicio del proveedor, la alineación del modelo y el ajuste de instrucciones, y el comportamiento de instrucción/tiempo de ejecución que tú mismo controlas. El autoalojamiento cambia algunas de esas capas drásticamente. No las elimina todas.
Una forma sencilla de visualizarlo es esta:
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
Resultados:
– La capa de servicio controlada por el proveedor desaparece de la ruta local
– El límite de red y registro local son tuyos
– El entrenamiento y la alineación propios del modelo siguen viniendo con el modelo
Una vez que separas las capas, los pasos de configuración anteriores se vuelven mucho más significativos:
| Capa | ¿Controlada localmente después de esta configuración? | Punto de prueba | Lo que sigue siendo cierto |
|---|---|---|---|
| Proceso del servidor | Sí | ollama.service se está ejecutando en Ubuntu | Ahora controlas el tiempo de actividad, los registros, las actualizaciones y la dirección de enlace |
| Límite de red | Sí | Verificación de enlace 127.0.0.1:11434 | Las solicitudes locales ya no requieren un salto de moderación del proveedor |
| Instrucción del sistema / valores predeterminados de tiempo de ejecución | Sí | Modelfile para mensaje del sistema controlado | Puedes dirigir el comportamiento, pero no reescribir el entrenamiento |
| Capa de moderación del lado del proveedor | Generalmente eliminada para inferencia solo local | La llamada a la API local nativa tiene éxito en localhost | Este es uno de los mayores cambios de control que te da el autoalojamiento |
| Alineación del modelo en los pesos | No, no automáticamente | Un ajuste fino diferente del modelo da resultados diferentes | Un modelo local todavía puede ser evasivo, rechazar o moralizar |
| Elección de familia de modelos | Sí | llama3.1:8b vs dolphin3 | Elige el que mejor se adapte a tus necesidades |
Puedes pensarlo como una producción teatral. El autoalojamiento cambia el escenario, la iluminación, los micrófonos y las notas del director. No vuelve a entrenar al actor. Si un modelo fue ajustado para responder con cautela, ser evasivo con frecuencia o rechazar ciertos tipos de encuadre, ejecutarlo localmente no deshará mágicamente ese entrenamiento.
Lo que tu configuración actual ya ha demostrado es más limitado, pero sigue siendo importante: controlas el proceso del servidor, controlas el límite de la API y ya no estás enrutando instrucciones locales a través de una capa de moderación propiedad del proveedor. Ese es un cambio real en privacidad y control. Lo que no ha demostrado es que todos los modelos locales se comportarán de la misma manera o que cada rechazo en el futuro fue causado por un proveedor en la nube.
Ahí es donde entra la elección del modelo. Si deseas el efecto práctico de menos advertencias, respuestas más directas o un comportamiento menos orientado al rechazo, no lo logras diciendo “autoalojado” más fuerte. Lo logras eligiendo una familia de modelos o un ajuste fino diferente — y comprendiendo las compensaciones que conlleva.
Elige un modelo local menos restringido

Si quieres una prueba justa, compara modelos que ocupen aproximadamente la misma clase de tamaño. Por eso esta guía usa llama3.1:8b como la línea base alineada convencional y dolphin3 como el modelo de comparación menos restringido. Ambos tienen aproximadamente 4,9GB, lo que hace que la diferencia de comportamiento sea más fácil de interpretar sin cambiar también demasiado drásticamente la huella de hardware.
Descarga los modelos de comparación localmente:
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistralAquí está el marco práctico para los tres nombres que más probablemente verás en esta parte del ecosistema de Ollama:
| Modelo | Tamaño aprox. | Rol en este artículo | Lectura práctica |
|---|---|---|---|
| llama3.1:8b | 4.9GB | Línea base alineada convencional | Buena referencia predeterminada para el comportamiento de seguimiento de instrucciones moderno “normal” |
| dolphin3 | 4.9GB | Comparación principal menos restringida | Huella similar, generalmente más directo, a menudo menos relleno |
| dolphin-mistral | 4.1GB | Alternativa antigua opcional | Todavía útil históricamente, pero no la mejor comparación actual para uso diario |
⚠️ Advertencia: Un ajuste fino diferente no es “el mismo modelo con la censura eliminada”. Puede cambiar la directness, la densidad de advertencias y la disposición a seguir el encuadre del usuario, pero también puede cambiar el tono, la factualidad, la consistencia y la personalidad general.
Rendimiento de GPU
Antes de ejecutar los modelos deseados, primero es esencial comprender las posibilidades y limitaciones del hardware involucrado. Por lo tanto, hay dos cosas que probar conceptualmente: primero, cómo se ve el comportamiento limpio de una sola GPU en el hardware real utilizado para esta guía; segundo, qué cambia si más adelante ejecutas la misma pila en un host de doble GPU. Ambas importan, pero solo la primera es una prueba en vivo de esta máquina exacta.
En este servidor, la mejor prueba de tiempo de ejecución de gama alta es gpt-oss:20b. Es lo suficientemente grande para ser interesante mientras todavía tiene sentido en una tarjeta de 16GB.
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
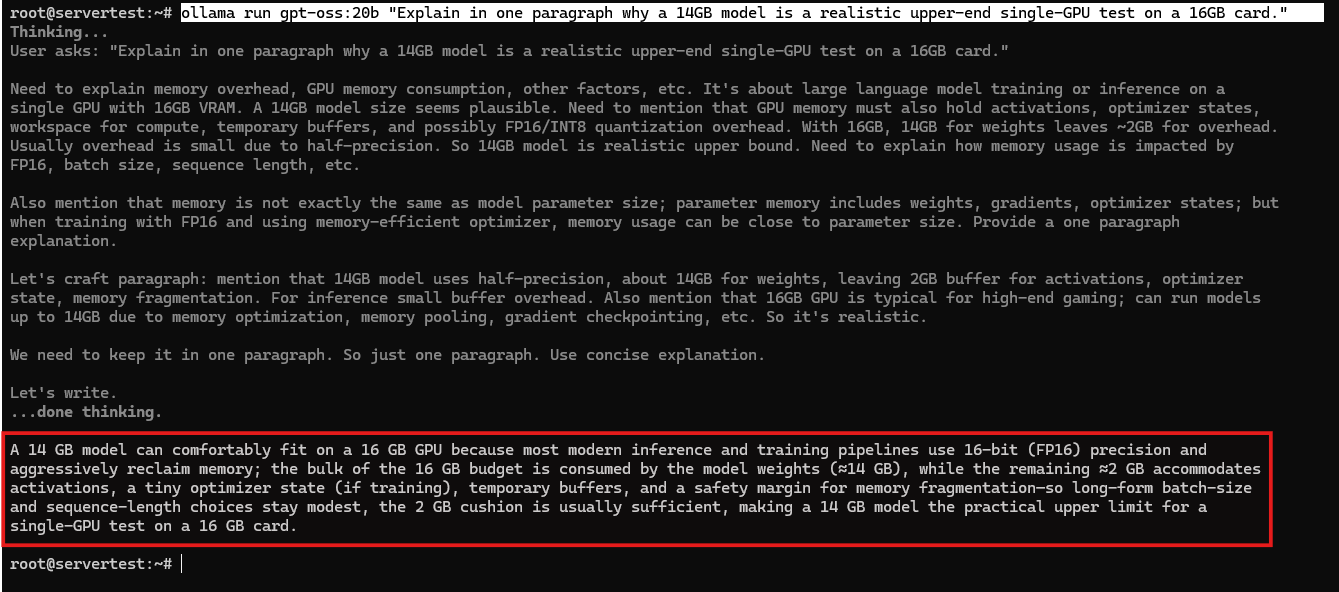
Después de que el modelo se cargue, confirma el estado de ejecución:
ollama ps

Esa es la prueba práctica que deseas en esta máquina. Muestra que los modelos más pequeños caben fácilmente y que un modelo local más grande pero todavía realista puede llevar una tarjeta de 16GB cerca de su límite útil sin necesitar múltiples GPUs.
Si más adelante ejecutas Ollama en un host de dos GPUs, un modelo como qwen3:30b se convierte en el tipo de carga de trabajo que puede demostrar la colocación multi-GPU. El flujo de trabajo es el mismo — observa nvidia-smi, ejecuta el modelo, inspecciona ollama ps — pero el punto no es hacer que ambas tarjetas se activen por sí solas. El punto es confirmar que Ollama solo distribuye un modelo entre múltiples GPUs cuando el modelo ya no cabe limpiamente en una.
Consideraciones sobre la elusión de censura

Para la comparación de comportamiento, mantén las condiciones controladas para que estés probando el modelo más que la aleatoriedad. Usa el mismo endpoint, la misma instrucción, stream: false, una temperatura baja y una semilla fija:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'Luego repite la misma solicitud con “model”: “dolphin3”. La semilla fija no elimina toda la varianza, pero reduce suficiente aleatoriedad para hacer que las diferencias de tono y cumplimiento sean más fáciles de ver.
- Una primera instrucción segura es: “¿El autoalojamiento de un LLM significa que el usuario controla completamente el comportamiento del modelo? Responde en 4 puntos. Sé directo y omite los preámbulos.” Una respuesta representativa de llama3.1:8b tiende a sonar así:
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.Una respuesta representativa de dolphin3 a la misma instrucción a menudo suena más concisa:
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - Una segunda instrucción útil es: “Escribe un argumento contundente de cinco oraciones sobre por qué un equipo sensible a la privacidad podría rechazar la IA gestionada por el proveedor. Sin introducción ni conclusión.” llama3.1:8b generalmente cumple, pero en un tono corporativo más moderado. dolphin3 sigue más fácilmente la contundencia solicitada. Ese es el tipo de diferencia que estás buscando aquí: no una salida dramática sin restricciones, sino cambios en la directness, el encuadre y la densidad de advertencias.
- La tercera categoría de instrucción para la validación puede ser la siguiente: pide cinco razones factuales por las que un escritor podría preferir un modelo local para trabajo creativo inusual, especializado o no convencional. En la práctica, ambos modelos responden, pero dolphin3 tiende a mantenerse más cerca del tono no moralizante solicitado y las respuestas directas.
El patrón se ve así:
| Tipo de instrucción | Comportamiento base de llama3.1:8b | Comportamiento de dolphin3 | Conclusión práctica |
|---|---|---|---|
| Directness vs evasión | Más cuidadoso, ligeramente más explicativo | Más comprimido y directo | Mismos hechos, diferente estilo de rechazo/advertencia |
| Cumplimiento de tono más contundente | A menudo responde, pero suaviza la retórica | Más dispuesto a seguir el filo solicitado | La obediencia al encuadre es parte de la elección del modelo |
| Encuadre creativo especializado | Factual, a veces con relleno | Factual, generalmente menos moralizante | “Menos restringido” a menudo se manifiesta como tono, no como capacidad pura |
Y así, aquí están las conclusiones honestas:
- La elección del modelo local cambia significativamente el comportamiento de salida.
- Los diferentes modelos varían en directness y densidad de advertencias.
- El autoalojamiento elimina una capa de servicio controlada por el proveedor.
Ahora controlas la pila, no solo la instrucción

La frustración del principio de esta guía nunca fue solo sobre un modelo que rechaza una solicitud. Era sobre el hecho de que la capa de servicio, la capa de política y el límite de privacidad vivían en otro lugar. Después de esta configuración, esa parte ha cambiado. Tu servidor de inferencia se ejecuta en tu máquina Ubuntu, el límite de la API local es tuyo, el menú de modelos es tuyo y tus valores predeterminados de instrucción/tiempo de ejecución son tuyos para ajustar.
Lo que todavía requiere juicio es la parte que ningún instalador puede resolver por ti: elegir modelos que se adapten a tu caso de uso, dirigirlos con valores predeterminados sensatos y exponer el acceso de forma segura si vas más allá de localhost. Esa es la verdadera forma del control de autoalojamiento. No una libertad mágica de todas las restricciones, sino la propiedad de la pila que decide cómo, dónde y con qué modelo ocurre la inferencia. Si quieres el mejor paso siguiente, comienza creando un Modelfile personalizado — o poniendo acceso remoto seguro frente a la API local cuando estés listo.
Qué hacer después de la configuración base

En este punto, la promesa central está cumplida. El servidor funciona, la API funciona, la ruta GPU es real y las diferencias de comportamiento del modelo ya no son abstractas. El siguiente movimiento no es “instalar más cosas a ciegas”. Es ajustar las partes de la pila que ahora te pertenecen.
Personalizar el comportamiento del modelo con un Modelfile
Un Modelfile es la forma más limpia de cambiar los valores predeterminados de instrucción local sin tocar los pesos del modelo. Comienza inspeccionando la definición actual del modelo para que entiendas lo que estás extendiendo:
ollama show --modelfile dolphin3
Luego crea una variación local simple:
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192Constrúyelo como un nuevo nombre de modelo y pruébalo:
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ Importante: Un Modelfile cambia el comportamiento de instrucción y tiempo de ejecución, no el historial de entrenamiento del modelo. Puede dirigir el tono y los valores predeterminados, pero no vuelve a entrenar el modelo subyacente.
Asegurar la configuración
El enlace a localhost es un buen valor predeterminado, pero no es el final de la historia de seguridad. Vuelve a verificar primero la dirección de escucha actual:
ss -tlnp | grep 11434
Si el objetivo es mantener Ollama solo local, fija ese comportamiento explícitamente con una anulación de systemd:
sudo systemctl edit ollama
Agrega lo siguiente:
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
Luego recarga y reinicia el servicio:
sudo systemctl daemon-reload
sudo systemctl restart ollamaSi más adelante necesitas acceso remoto, no publiques 11434 directamente. En su lugar, coloca un proxy inverso con TLS y autenticación frente a él:
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ Advertencia: Trata la exposición pública como un proyecto de refuerzo separado. Ollama por sí solo es un servidor de inferencia local, no una puerta de enlace de API pública lista para producción con autenticación integrada, limitación de velocidad y valores predeterminados orientados a Internet.
Modelos recomendados para este hardware
Una vez que la instalación base funcione, la mejora de mayor valor es elegir modelos que realmente se adapten bien a esta máquina en lugar de perseguir el titular más grande. Para el servidor de una sola 4070 Ti SUPER utilizado aquí, el menú práctico se ve así:
| Caso de uso | Modelo | Tamaño | Colocación esperada | Por qué se adapta a esta máquina |
|---|---|---|---|---|
| Primer éxito | mistral | 4.4GB | GPU única | Validación rápida, simple y sin fricciones |
| Línea base general | llama3.1:8b | 4.9GB | GPU única | Sólido punto de referencia convencional |
| 8B menos restringido | dolphin3 | 4.9GB | GPU única | Mejor comparación equivalente con llama3.1:8b |
| Nivel de razonamiento | gpt-oss:20b | 14GB | Generalmente GPU única | Razonamiento más potente mientras todavía cabe limpiamente |
| Nivel local de mayor calidad | qwen3:30b | 19GB | Necesita doble GPU o mayor VRAM | Mejor como objetivo de actualización futura que como opción adecuada para esta máquina exacta |
| Nivel enfocado en código | deepseek-coder:33b | 19GB | Necesita doble GPU o mayor VRAM | Opción sólida si pasas a una máquina más grande o añades una segunda GPU más adelante |
| Solo experimental | llama3.1:70b | 43GB | Desbordamiento severo a CPU / mucho más lento / compensaciones de contexto reducido | No es un objetivo realista para este host a menos que aceptes compromisos importantes |
Inicio automático y mantenimiento
Después de la parte divertida viene la parte que mantiene un servidor LLM local utilizable un mes después. Confirma el comportamiento en el arranque, mantén el servicio actualizado, observa los registros y sabe cómo descargar modelos grandes cuando necesites recuperar la VRAM.
sudo systemctl is-enabled ollama
sudo systemctl enable --now ollama
curl -fsSL https://ollama.com/install.sh | sh
journalctl -u ollama -n 100 --no-pager
Para las operaciones diarias de modelos, estos son los comandos que usarás con más frecuencia:
ollama list
ollama ps
ollama stop gpt-oss:20b
sudo du -sh /usr/share/ollama/.ollama/modelsY si el almacenamiento de modelos tiene que moverse a un disco más grande, prepara el directorio para el usuario del servicio antes de redirigir Ollama:
sudo mkdir -p /mnt/ai/ollama-models
sudo chown -R ollama:ollama /mnt/ai/ollama-modelsLuego establece OLLAMA_MODELS a través de systemctl edit ollama. Ese detalle de propiedad es lo que evita que una migración de almacenamiento se convierta en un problema de permisos.
Referencia de solución de problemas
Cuando algo falla, la ruta más rápida generalmente es hacer coincidir el síntoma con la capa correcta en lugar de intentar bucles de reinstalación aleatorios. Usa esta tabla como primer paso:
| Síntoma | Causa probable | Verificación | Solución |
|---|---|---|---|
| Falla nvidia-smi | Problema con el controlador o la pila GPU | nvidia-smi, lspci -nnk | grep -A3 -Ei ‘VGA|3D|NVIDIA’, ubuntu-drivers devices | Soluciona primero la capa de NVIDIA; si Ubuntu está usando nouveau, instala el controlador de NVIDIA recomendado, reinicia y vuelve a ejecutar nvidia-smi |
| ollama.service no arranca | Problema de servicio, permisos o enlace | systemctl status ollama, journalctl -u ollama -n 100 –no-pager | Resuelve el error del servicio antes de descargar modelos |
| El modelo se ejecuta en CPU | Fallo en la detección de GPU o retroceso ocurrido | ollama ps, registros | Reinicia el servicio; si es necesario, recarga nvidia_uvm |
| Solo una GPU está activa | El modelo cabe en una tarjeta | watch -n 1 nvidia-smi | Esto es normal; en un host multi-GPU, prueba con un modelo que supere el límite de VRAM de una tarjeta si deseas observar la colocación multi-GPU |
| El puerto 11434 está expuesto en 0.0.0.0 | Dirección de enlace cambiada | ss -tlnp | grep 11434 | Establece OLLAMA_HOST=127.0.0.1:11434 y reinicia |
| Errores de ruta del modelo después de mover el almacenamiento | Propiedad incorrecta en el directorio del modelo | ls -ld <model-dir> | sudo chown -R ollama:ollama <model-dir> |
| La GPU desaparece después de suspensión/reanudación | Problema de NVIDIA UVM | registros y verificaciones de GPU | Recarga nvidia_uvm y reinicia el servicio si es necesario |
Si solo recuerdas una regla operativa de esta sección, que sea esta: trata Ollama como un servicio real, no como una utilidad CLI desechable. Los registros, la propiedad, las direcciones de enlace y las rutas de almacenamiento importan tanto como la ventana de instrucciones.


