 Indonesia
Indonesia English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  中文 (中国)
中文 (中国) 




 untuk semua layanan hosting
untuk semua layanan hostingSelf-Host Ollama di Server LLM dan Kendalikan Sensor AI
Kata Kunci
Sebelum masuk ke pengaturan, berikut adalah istilah-istilah yang paling mungkin membingungkan pembaca dalam panduan ini. Glosarium singkat ini menjaga kosakata Linux, GPU, dan model lokal tetap jelas sejak awal.
| Kata Kunci | Penjelasan singkat |
|---|---|
| 🤖 LLM | Large Language Model; model AI yang menghasilkan teks dari prompt. |
| 🦙 Ollama | Runner dan server model lokal untuk mengunduh, melayani, dan memanggil LLM di mesin Anda sendiri. |
| 🖥️ GPU | Prosesor grafis yang digunakan di sini untuk mempercepat inferensi model. |
| 💾 VRAM | Memori pada GPU; ini adalah salah satu batasan utama seberapa besar model yang dapat dimuat pada sebuah kartu. |
| ⚡ Inferensi | Tindakan menjalankan model untuk menghasilkan jawaban. |
| 🔄 systemd | Manajer layanan Linux yang digunakan untuk memulai, menghentikan, me-restart, dan mengaktifkan layanan seperti Ollama. |
| 🧩 Driver NVIDIA | Lapisan perangkat lunak yang memungkinkan Ubuntu berkomunikasi dengan GPU NVIDIA secara benar untuk beban kerja komputasi. |
| 🚫 nouveau | Driver grafis Linux sumber terbuka yang dapat mencegah pengaturan komputasi NVIDIA yang tepat jika digunakan sebagai pengganti driver resmi NVIDIA. |
| 📊 nvidia-smi | Alat baris perintah NVIDIA untuk memeriksa visibilitas GPU, penggunaan VRAM, dan kesehatan driver. |
| 🔌 API endpoint | URL yang dipanggil oleh alat atau skrip untuk mengirim prompt ke Ollama dan menerima respons. |
| ☁️ Lapisan penyajian yang dikendalikan vendor | Lapisan API yang dikelola penyedia yang dapat menambahkan moderasi, pencatatan, penegakan kebijakan, atau kontrol lainnya sebelum model merespons. |
| 🧬 Fine-tune | Versi modifikasi dari model dasar yang disetel untuk nada, perilaku, atau tugas tujuan khusus yang berbeda. |
| ⚖️ Bobot model | Parameter internal model yang telah dipelajari; self-hosting tidak secara otomatis mengubahnya. |
| 📝 Modelfile | File Ollama yang digunakan untuk membuat varian model lokal kustom dengan prompt sistem dan parameter runtime Anda sendiri. |
| 🪪 UUID | Pengenal perangkat keras yang stabil untuk GPU; ini sering lebih aman daripada ID GPU numerik karena urutan perangkat dapat berubah. |
| 🔒 TLS | Enkripsi yang digunakan oleh HTTPS dan reverse proxy untuk mengamankan lalu lintas antara klien dan server. |
| 🌐 Reverse proxy | Layanan front-end yang dapat menambahkan TLS, autentikasi, dan akses publik terkontrol sebelum meneruskan permintaan ke Ollama. |
| 🎛️ Temperature / seed | Pengaturan generasi; temperature memengaruhi keacakan, sementara seed tetap membantu membuat pengujian berulang lebih mudah dibandingkan. |
| 🧱 CPU spill / mixed path | Situasi di mana sebagian model atau beban kerja jatuh di luar memori GPU dan menggunakan sumber daya CPU, yang dapat memperlambat inferensi. |
| 🔧 nvidia_uvm | Modul kernel NVIDIA yang terkait dengan manajemen memori GPU yang terkadang perlu dimuat ulang selama pemecahan masalah. |
Mengapa Self-Hosting LLM Layak Dilakukan

Jika Anda sudah melakukan bagian yang sulit — menyewa server GPU, menginstal Ubuntu, mempelajari cara bekerja dengan SSH, dan menjaga layanan Anda sendiri tetap berjalan — maka akan cepat terasa frustrasi ketika AI yang di-hosting masih mengendalikan bagian terakhir. AI tersebut dapat menolak permintaan yang sepenuhnya biasa, mengubur jawaban di bawah penafian, mengubah gaya respons tanpa peringatan, dan menjaga setiap prompt mengalir melalui batasan orang lain. Bagi banyak pengguna teknis, itulah frustrasi yang sesungguhnya: bukan hanya apa yang dikatakan model, tetapi siapa yang mengendalikan lapisan penyajian ketika model tersebut mengatakannya.
Panduan ini membahas cara memperbaiki hal tersebut dengan model terbuka dan lokal, bukan tentang trik bypass untuk API milik pihak ketiga. Anda akan melakukan self-host Ollama di server GPU Ubuntu, menjalankan inferensi secara lokal, memverifikasi bahwa jalur GPU nyata, dan melihat apa yang berubah ketika Anda memilih keluarga model yang berbeda. Satu kesalahpahaman yang perlu diluruskan sejak awal: self-hosted tidak secara otomatis berarti tidak terbatas. Ini berarti Anda mengendalikan lebih banyak bagian dari tumpukan — dan Anda berhenti bergantung pada jalur penyajian yang dikendalikan vendor — tetapi model yang Anda jalankan masih dapat membawa perilaku alignment-nya sendiri.
📝 Catatan: Perintah-perintah dalam panduan ini divalidasi terhadap dokumentasi Ollama saat ini, tetapi output terminal yang ditampilkan di bawah ini adalah contoh representatif daripada hasil tangkapan benchmark langsung. Gunakan sebagai pola keberhasilan, bukan sebagai klaim performa.
Pada akhirnya, Anda akan memiliki layanan Ollama yang berfungsi di Ubuntu, API lokal yang terverifikasi di 127.0.0.1:11434, bukti bahwa inferensi berbasis GPU benar-benar terjadi, dan perbandingan yang berdasar antara model aligned mainstream dan alternatif yang kurang dibatasi. Tutorial ini ditulis untuk pembaca yang nyaman dengan SSH, Ubuntu, sudo, dan systemd, tetapi tidak memerlukan pengalaman Ollama sebelumnya.
Server GPU Ubuntu yang Digunakan untuk Panduan Ini

Panduan ini didasarkan pada mesin Ubuntu GPU tunggal yang nyata, karena saran samar “seharusnya berfungsi di sebagian besar server” adalah cara panduan self-hosting menjadi menyesatkan. Mesin referensi di sini adalah kelas host yang sebenarnya digunakan untuk panduan ini: jenis mesin yang akan disewa oleh individu tingkat lanjut, lab, atau tim kecil ketika mereka menginginkan inferensi lokal yang privat tanpa langsung beralih ke rak akselerator enterprise. Panduan ini masih akan membahas perilaku multi-GPU nanti, karena Ollama memang berubah setelah model melebihi kapasitas satu kartu, tetapi anggap bagian tersebut sebagai konteks yang berorientasi ke masa depan daripada bukti dari server yang tepat ini.
Server GPU — Ryzen 9 3950X + RTX 4070 Ti Super
| Komponen | Detail |
|---|---|
| CPU | AMD Ryzen 9 3950X (16 core / 32 thread) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| Kemampuan | Kuat untuk model kelas 8B; model yang lebih besar menjadi keputusan spill-atau-upgrade |
Dalam praktiknya, ini adalah pengaturan yang sangat kuat untuk model kelas 8B sehari-hari dan masih berguna untuk pekerjaan lokal yang lebih besar hingga titik di mana 16GB VRAM menjadi batasan nyata. Model seperti llama3.1:8b dengan ukuran sekitar 4.9GB dengan mudah masuk ke kartu ini. Model seperti gpt-oss:20b dengan ukuran sekitar 14GB adalah jenis pengujian GPU tunggal kelas atas yang masih masuk akal di sini. Model seperti qwen3:30b dengan ukuran sekitar 19GB lebih baik diperlakukan sebagai titik referensi tentang apa yang berubah pada host yang lebih besar atau dual-GPU daripada sebagai kesesuaian bersih untuk mesin yang tepat ini.
Perbedaan ini penting karena tujuan artikel ini bukan untuk memasukkan angka terbesar yang mungkin ke dalam judul. Ini adalah untuk menunjukkan seperti apa server LLM yang di-host sendiri dengan bijak ketika Anda menginginkan privasi, kontrol lokal, dan memori GPU yang cukup untuk menjalankan model yang berguna tanpa kompromi yang terus-menerus. Kelas perangkat keras ini adalah di mana inferensi yang di-host sendiri menjadi realistis, bukan teoretis.
Ini juga menjelaskan beberapa pilihan yang akan Anda lihat nanti: mistral digunakan pertama karena memberikan bukti cepat dan minim hambatan bahwa tumpukan berfungsi, sementara perbandingan perilaku tetap berada di kelas 8B di mana mesin ini nyaman. qwen3:30b masih muncul nanti, tetapi sebagai contoh teoretis dari jenis model yang dapat memicu penempatan multi-GPU pada host yang lebih besar daripada sebagai bukti langsung dari server ini. Dengan ekspektasi yang telah ditetapkan, langkah berikutnya adalah memvalidasi host sebelum Ollama menyentuhnya.
Jalankan Pemeriksaan Pra-Instalasi Ini Sebelum Menyentuh Ollama

Mulai dengan nvidia-smi. Jika perintah ini hilang atau gagal, hentikan di sana dan perbaiki driver NVIDIA terlebih dahulu. Jangan instal Ollama dulu, karena tumpukan NVIDIA yang rusak akan membuat setiap gejala selanjutnya terlihat seperti kegagalan aplikasi padahal sebenarnya adalah kegagalan platform.
Jalankan pemeriksaan GPU terlebih dahulu:
nvidia-smi
❗Jika Ubuntu mengatakan nvidia-smi tidak ditemukan, jangan berasumsi bahwa server tidak memiliki GPU. Mode kegagalan umum pada kotak Ubuntu yang disewa adalah kartu tersebut ada tetapi masih terikat ke nouveau alih-alih driver NVIDIA. Periksa bagian “Perbaiki Masalah Driver Nvidia di Ubuntu” terlebih dahulu.
Hasil yang sehat pada kelas server ini seharusnya terlihat kira-kira seperti ini:
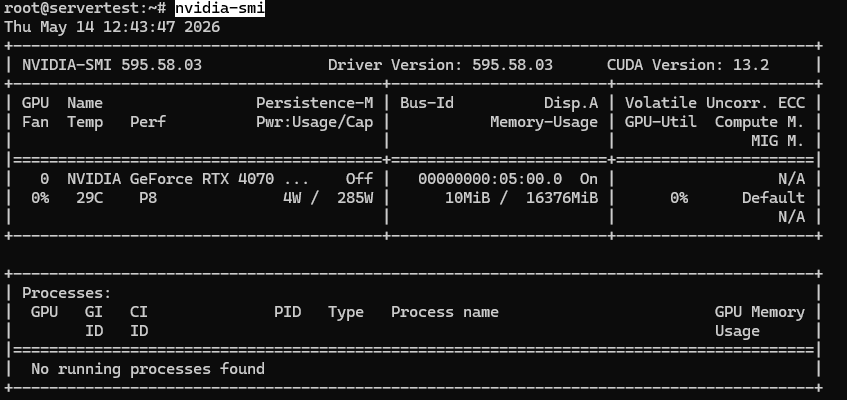
Setelah nvidia-smi berfungsi dan GPU terlihat, lanjutkan dengan pemeriksaan di bawah ini.
Yang ingin Anda konfirmasi adalah sederhana: GPU yang terpasang terlihat, melaporkan sekitar 16GB VRAM pada host ini, dan driver dimuat dengan bersih. Jika Anda menggunakan server multi-GPU, perintah yang sama seharusnya mencantumkan setiap kartu.
nvidia-smi -L

❗ Penting: Dokumentasi dukungan GPU Ollama saat ini menggunakan driver NVIDIA 531+ sebagai batas nyata untuk inferensi NVIDIA yang didukung. Perlakukan 531+ sebagai persyaratan untuk panduan ini, meskipun Anda pernah melihat catatan komunitas lama yang menyebutkan versi yang lebih rendah.
Sekarang konfirmasi bahwa host benar-benar merupakan lingkungan Ubuntu yang diasumsikan panduan ini:
lsb_release -a
Terakhir, periksa ruang disk kosong sebelum Anda mulai mengunduh model. Instalasi itu sendiri kecil; modelnya tidak. Setelah Anda melewati pengujian kecil, pustaka 20B-30B dapat menghabiskan puluhan gigabyte dengan cepat, jadi 100GB+ bebas adalah pola pikir yang tepat sebelum pekerjaan model lokal yang serius.
df -h /

Jika pemeriksaan ini lulus, Anda telah membersihkan ketidakpastian infrastruktur utama: GPU ada, dasar driver sudah wajar, Ubuntu dikonfirmasi, dan disk memiliki ruang untuk penarikan model yang nyata. Itulah titik di mana menginstal Ollama menjadi langkah berikutnya yang bersih daripada sebuah tebakan.
Perbaiki Masalah Driver Nvidia di Ubuntu
Ikuti langkah-langkah di bawah ini untuk memperbaiki masalah dengan perintah “nvidia-smi”.
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
Jika output tersebut menunjukkan kartu NVIDIA dan baris seperti Kernel driver in use: nouveau, instal paket driver Ubuntu yang direkomendasikan alih-alih menginstal nvidia-utils saja.
Instal paket ubuntu-drivers-common (diperlukan untuk manajemen driver) dan header kernel untuk kernel yang sedang berjalan.
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)Pindai sistem Anda dan daftarkan driver proprietary yang tersedia (misalnya, driver GPU NVIDIA) yang dapat diinstal.
ubuntu-drivers devices
Kemudian instal paket driver yang direkomendasikan. Dalam kasus kami adalah: nvidia-driver-595-open:
apt install -y nvidia-driver-595-open
rebootSetelah reboot, jalankan kembali:
nvidia-smi
nvidia-smi -LInstal Ollama dan Konfirmasi Layanan dalam Kondisi Baik

Jalur Ubuntu yang didukung adalah penginstal Ollama resmi, bukan alur tarball kustom dan bukan melalui Docker. Hal ini penting karena panduan ini adalah tentang mendapatkan layanan lokal yang andal dengan default yang dapat diprediksi, integrasi systemd, dan perilaku kepemilikan yang wajar di Linux.
Jalankan penginstal persis seperti yang didokumentasikan:
curl -fsSL https://ollama.com/install.sh | sh
Pada sistem yang sehat, skrip menginstal biner, membuat pengguna layanan ollama, menambahkan keanggotaan grup yang tepat jika tersedia, menulis unit systemd, dan memulai layanan yang terikat ke 127.0.0.1:11434.
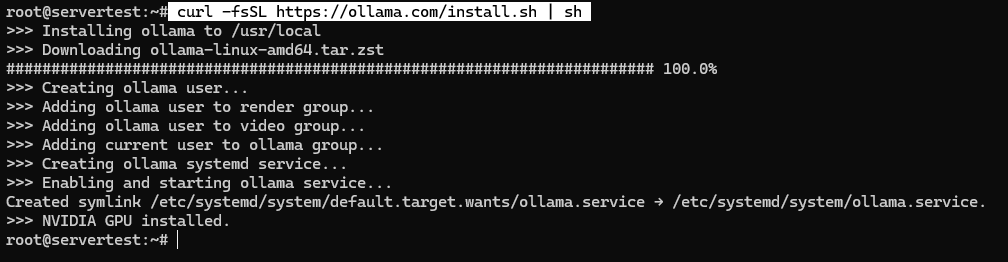
Setelah skrip selesai, validasi layanan alih-alih mengasumsikan keberhasilan:
sudo systemctl status ollama --no-pager
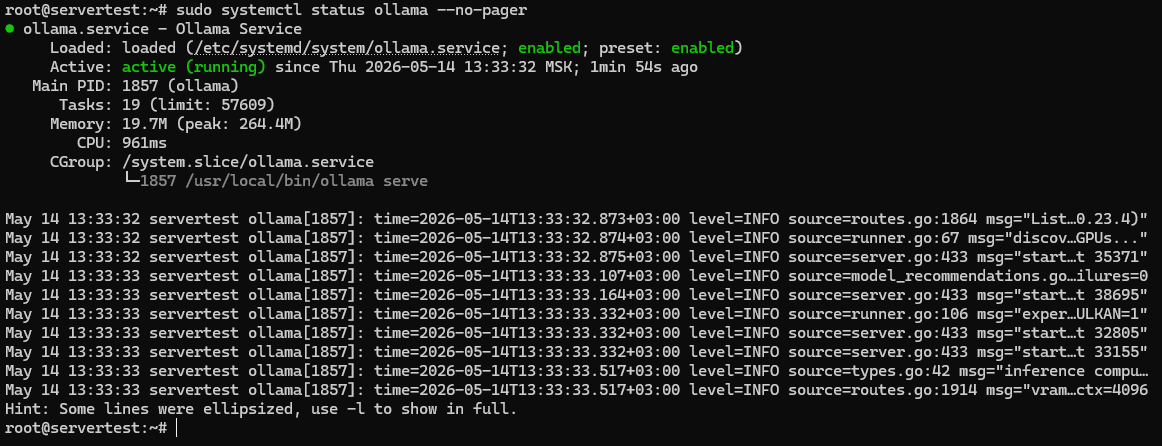
Anda mencari tiga hal di sini: file unit ada, layanan diaktifkan untuk boot, dan Active: active (running) mengonfirmasi bahwa server benar-benar aktif.
Pertama, tetapkan akun pengguna layanan Linux secara konkret, dan baru setelah itu pikirkan bagaimana dan di mana penyimpanan model akan ditangani.
getent passwd ollama

Satu baris tersebut menjelaskan banyak perilaku di masa mendatang. Model di Linux berada di bawah kepemilikan layanan, dan jika Anda kemudian memindahkannya ke disk lain tanpa memperbaiki izin untuk pengguna ollama, Anda menciptakan kerusakan sendiri.
Satu pemeriksaan lagi menutup loop pada ikatan default:
ss -tlnp | grep 11434

⚠️ Peringatan: Ollama tidak memerlukan autentikasi pada API lokal secara default. Itu tidak masalah ketika terikat ke 127.0.0.1, tetapi tidak aman untuk mengekspos port 11434 langsung ke internet seolah-olah itu adalah layanan publik yang diperkuat.
Jika layanan tidak berjalan dengan bersih, pergi ke log terlebih dahulu alih-alih menginstal ulang secara membabi buta:
journalctl -u ollama -n 100 --no-pager
Itulah cara tercepat untuk menangkap masalah izin, kesalahan startup, masalah deteksi driver, atau masalah bind. Setelah layanan sehat di localhost, hal berikutnya yang perlu dipahami adalah bagaimana perilaku penempatan GPU saat runtime.
Cara Ollama Sebenarnya Menggunakan Satu atau Beberapa GPU
Meskipun server yang digunakan untuk panduan ini memiliki satu GPU, perilaku multi-GPU tetap layak dipahami karena banyak pengguna mungkin menggunakan kotak yang lebih besar atau mungkin berkembang kemudian. Banyak kebingungan dua-GPU dimulai dengan ekspektasi yang salah: “Saya memiliki dua kartu, jadi keduanya harus menyala sepanjang waktu.” Begitulah cara Ollama bekerja. Aturan praktisnya jauh lebih sederhana: jika sebuah model muat di satu GPU, Ollama biasanya akan menyimpannya di satu GPU. Ini hanya menyebar ke beberapa GPU ketika model tidak muat dengan nyaman di satu kartu.
Gunakan dua pemeriksaan ini bersama-sama kapan pun Anda ingin melihat performa GPU:
ollama ps
watch -n 1 nvidia-smi
ollama ps memberi tahu Anda bagaimana model yang dimuat sedang diproses. 100% GPU berarti model sepenuhnya berada di memori GPU. 100% CPU berarti akselerasi GPU tidak digunakan. Status campuran memberi tahu Anda bahwa sebagian beban kerja atau residensi tumpah di luar jalur GPU. watch -n 1 nvidia-smi melengkapi itu dengan menampilkan penggunaan VRAM langsung per kartu saat model dimuat.
Cara tercepat untuk menjaga peran-peran tersebut tetap jelas adalah ini:
| Perintah | Apa yang dibuktikannya | Apa yang tidak dibuktikannya |
|---|---|---|
| ollama ps | Apakah model berjalan di GPU, CPU, atau jalur campuran | Kartu mana atau kartu-kartu mana yang menanggung beban |
| watch -n 1 nvidia-smi | Aktivitas VRAM real-time per GPU | Apakah penggunaan dual-GPU secara otomatis berarti pilihan model yang lebih baik |
📝 Catatan: CUDA_VISIBLE_DEVICES adalah kontrol visibilitas, bukan sakelar “gunakan kedua GPU”. Jika Anda perlu membatasi akses GPU, lebih baik gunakan UUID dari nvidia-smi -L daripada ID numerik karena urutan GPU dapat bervariasi antar lingkungan dan reboot.
Jalankan Model Lokal Pertama Anda dan Verifikasi Inferensi GPU
Pada titik ini, Anda tidak memerlukan model besar untuk membuktikan bahwa server berfungsi. Anda membutuhkan keberhasilan yang cepat dan jujur. mistral adalah pilihan pertama yang baik karena kecil, cepat diunduh, dan mudah dimuat, meskipun llama3.1:8b akan menjadi baseline selanjutnya untuk perbandingan perilaku.
Mulai dengan menarik model:
ollama pull mistral

Sekarang jalankan prompt kecil melaluinya sehingga mesin melakukan sesuatu yang berguna, bukan hanya administratif. Respons mungkin memerlukan beberapa detik.
ollama run mistral "In one sentence, explain why people self-host LLMs."

Untuk membuktikan bahwa ini adalah inferensi berbasis GPU daripada fallback CPU, periksa status runtime:
ollama ps

Dan untuk melihat apa yang sudah ada di disk, daftarkan inventaris lokal:
ollama list

mistral adalah bukti pertama yang tepat karena memberikan jawaban cepat tanpa mengubah validasi pengaturan menjadi penantian yang lama. Kemudian, llama3.1:8b menjadi lebih berguna karena merupakan baseline aligned yang lebih kuat untuk membandingkan perilaku model.
Terakhir, periksa di mana instalasi Linux menyimpan model:
sudo du -sh /usr/share/ollama/.ollama/models

Jalur tersebut — /usr/share/ollama/.ollama/models — adalah toko model Linux standar yang didokumentasikan oleh Ollama.
Setelah Anda melihat respons yang berhasil, 100% GPU di ollama ps, dan penggunaan disk yang meningkat di lokasi yang diharapkan, Anda memiliki bukti pertama yang bermakna bahwa tumpukan lokal berfungsi.
Buktikan Ini adalah Server, Bukan Hanya Pembungkus CLI

Prompt baris perintah memang bagus, tetapi alasan untuk melakukan self-host Ollama bukan hanya untuk mengobrol di dalam terminal. Ini adalah untuk menjalankan server inferensi lokal yang dapat dipanggil oleh alat, skrip, dan aplikasi lain tanpa mengirim prompt melalui batas API orang lain. Bukti tercepat adalah satu permintaan HTTP bersih ke endpoint Ollama native.
Kirim permintaan generate lokal dengan streaming dinonaktifkan sehingga respons pertama mudah diperiksa:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'Balasan yang berhasil seharusnya kembali sebagai JSON dan terlihat kira-kira seperti ini:
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
Daftar periksa keberhasilan sudah jelas: permintaan HTTP berfungsi secara lokal, JSON yang valid dikembalikan, done: true ada, dan jawaban model ada di response. Itulah titik di mana Ollama berhenti menjadi “CLI yang kebetulan mengunduh model” dan menjadi infrastruktur yang benar-benar dapat Anda integrasikan ke dalam alat lokal dan otomasi.
Jika Anda menginginkan kompatibilitas dengan perangkat lunak yang mengharapkan bentuk permintaan bergaya OpenAI, Ollama juga mengekspos endpoint /v1 secara lokal:
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 Catatan: Label “kompatibel dengan OpenAI” itu mudah disalahartikan. Ini tidak berarti Anda berbicara dengan OpenAI, dan tidak mengubah fakta bahwa server masih lokal. Ini hanya berarti bentuk permintaan cukup familiar untuk alat dan SDK yang dibangun di sekitar pola OpenAI API. URL dasar tetap http://localhost:11434/v1/, dan kunci API placeholder yang diharuskan oleh beberapa library klien dapat diabaikan untuk penggunaan Ollama lokal.
Dari Mana Pembatasan Model Sebenarnya Berasal

Ini adalah bagian yang biasanya dipadatkan menjadi satu ide samar tentang “sensor”, tetapi secara teknis ada tiga lapisan berbeda yang terlibat: lapisan penyajian vendor, alignment dan instruction tuning model, serta perilaku prompt/runtime yang Anda kendalikan sendiri. Self-hosting mengubah beberapa lapisan tersebut secara dramatis. Ini tidak menghapus semuanya.
Cara sederhana untuk membayangkannya adalah ini:
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
Hasilnya:
– Lapisan penyajian yang dikendalikan vendor menghilang dari jalur lokal
– Batas jaringan dan pencatatan lokal menjadi milik Anda
– Training dan alignment model itu sendiri masih ikut bersama model
Setelah Anda memisahkan lapisan-lapisan tersebut, langkah-langkah pengaturan sebelumnya menjadi jauh lebih bermakna:
| Lapisan | Dikendalikan secara lokal setelah pengaturan ini? | Titik bukti | Apa yang masih tetap benar |
|---|---|---|---|
| Proses server | Ya | ollama.service berjalan di Ubuntu | Anda sekarang mengendalikan uptime, log, pembaruan, dan alamat bind |
| Batas jaringan | Ya | Pemeriksaan bind 127.0.0.1:11434 | Permintaan lokal tidak lagi memerlukan lompatan moderasi vendor |
| System prompt / default runtime | Ya | Modelfile untuk pesan sistem yang terkontrol | Anda dapat mengarahkan perilaku, tetapi tidak menulis ulang training |
| Lapisan moderasi sisi vendor | Biasanya dihapus untuk inferensi hanya-lokal | Panggilan API lokal native berhasil di localhost | Ini adalah salah satu pergeseran kontrol terbesar yang diberikan self-hosting kepada Anda |
| Alignment model dalam bobot | Tidak, tidak secara otomatis | Tuning model berbeda, memberikan hasil berbeda | Model lokal masih dapat memberikan jawaban tidak pasti, menolak, atau bermoralisasi |
| Pilihan keluarga model | Ya | llama3.1:8b vs dolphin3 | Pilih yang paling sesuai dengan kebutuhan Anda |
Anda dapat memikirkannya seperti produksi teater. Self-hosting mengubah panggung, pencahayaan, mikrofon, dan catatan sutradara. Ini tidak melatih ulang aktor. Jika sebuah model disetel untuk menjawab dengan hati-hati, sering memberikan jawaban tidak pasti, atau menolak jenis framing tertentu, menjalankannya secara lokal tidak akan secara ajaib membatalkan training tersebut.
Yang telah dibuktikan pengaturan Anda saat ini lebih sempit, tetapi masih penting: Anda mengendalikan proses server, Anda mengendalikan batas API, dan Anda tidak lagi merutekan prompt lokal melalui lapisan moderasi yang dimiliki vendor. Itu adalah pergeseran nyata dalam privasi dan kontrol. Yang belum dibuktikannya adalah bahwa setiap model lokal akan berperilaku sama atau bahwa setiap penolakan di masa depan disebabkan oleh penyedia cloud.
Di situlah pilihan model masuk. Jika Anda menginginkan efek praktis dari lebih sedikit penafian, jawaban yang lebih langsung, atau perilaku yang kurang sering menolak, Anda tidak mendapatkannya dengan mengatakan “self-hosted” lebih keras. Anda mendapatkannya dengan memilih keluarga model atau fine-tune yang berbeda — dan dengan memahami tradeoff yang menyertainya.
Pilih Model Lokal yang Kurang Dibatasi

Jika Anda menginginkan pengujian yang adil, bandingkan model yang menempati kelas ukuran yang kira-kira sama. Itulah mengapa panduan ini menggunakan llama3.1:8b sebagai baseline aligned mainstream dan dolphin3 sebagai model perbandingan yang kurang dibatasi. Keduanya sekitar 4.9GB, yang membuat perbedaan perilaku lebih mudah diinterpretasikan tanpa juga terlalu drastis mengubah jejak perangkat keras.
Tarik model perbandingan secara lokal:
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistralBerikut adalah framing praktis untuk tiga nama yang paling mungkin Anda lihat di bagian ekosistem Ollama ini:
| Model | Ukuran perkiraan | Peran dalam artikel ini | Pembacaan praktis |
|---|---|---|---|
| llama3.1:8b | 4.9GB | Baseline aligned mainstream | Referensi default yang baik untuk perilaku instruction-following modern yang “normal” |
| dolphin3 | 4.9GB | Perbandingan utama yang kurang dibatasi | Jejak serupa, biasanya lebih langsung, sering kali lebih sedikit padding |
| dolphin-mistral | 4.1GB | Alternatif lama yang opsional | Masih berguna secara historis, tetapi bukan perbandingan daily-driver terbaik saat ini |
⚠️ Peringatan: Fine-tune yang berbeda bukanlah “model yang sama dengan sensor dihapus.” Ini dapat mengubah kelangsungan, kepadatan penafian, dan kesediaan untuk mengikuti framing pengguna, tetapi juga dapat mengubah nada, faktualitas, konsistensi, dan kepribadian keseluruhan.
Performa GPU
Sebelum menjalankan model yang diinginkan, pertama-tama penting untuk memahami kemungkinan dan keterbatasan perangkat keras yang terlibat. Jadi, ada dua hal yang perlu diuji secara konseptual: pertama, seperti apa perilaku GPU tunggal yang bersih pada perangkat keras yang sebenarnya digunakan untuk panduan ini; kedua, apa yang berubah jika Anda kemudian menjalankan tumpukan yang sama pada host dual-GPU. Keduanya penting, tetapi hanya yang pertama yang merupakan bukti langsung dari mesin yang tepat ini.
Pada server ini, pengujian runtime kelas atas yang lebih baik adalah gpt-oss:20b. Cukup besar untuk menarik minat sementara masih masuk akal pada satu kartu 16GB.
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
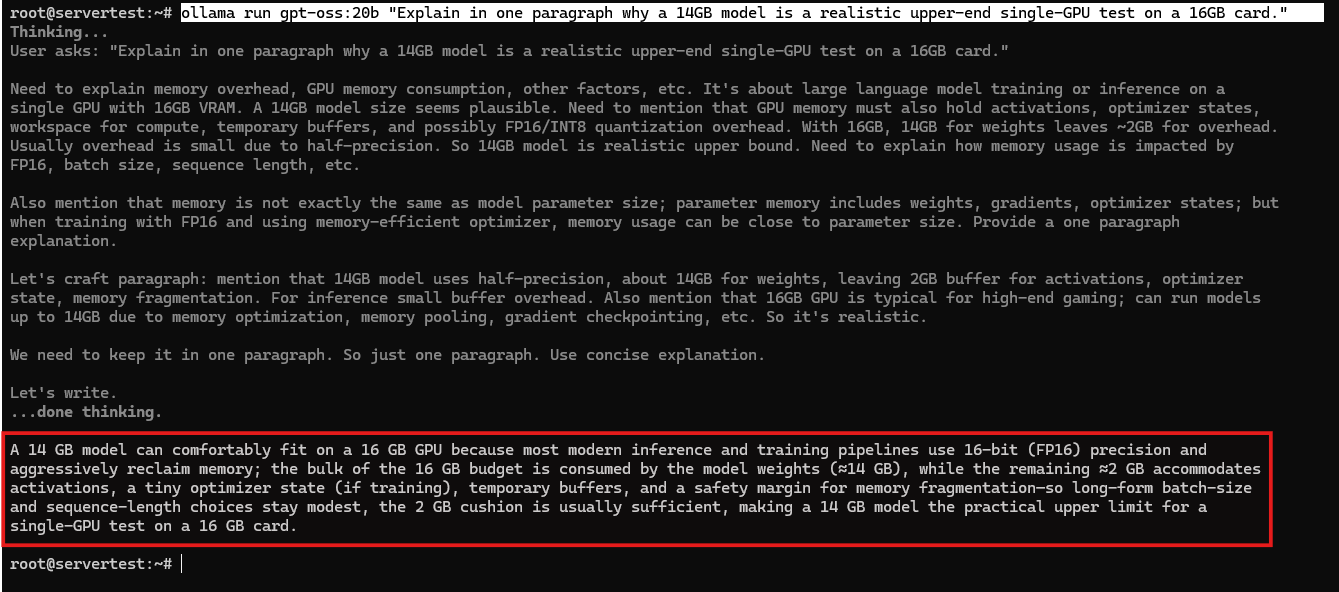
Setelah model dimuat, konfirmasi status runtime:
ollama ps

Itulah bukti praktis yang Anda inginkan pada mesin ini. Ini menunjukkan bahwa model yang lebih kecil dengan mudah muat dan bahwa model lokal yang lebih besar tetapi masih realistis dapat mendorong satu kartu 16GB mendekati batas penggunaan yang dapat digunakan tanpa memerlukan beberapa GPU.
Jika Anda kemudian menjalankan Ollama pada host dua-GPU, model seperti qwen3:30b menjadi jenis beban kerja yang dapat mendemonstrasikan penempatan multi-GPU. Alurnya sama — pantau nvidia-smi, jalankan model, periksa ollama ps — tetapi intinya bukan untuk membuat kedua kartu menyala demi kepentingannya sendiri. Intinya adalah untuk mengonfirmasi bahwa Ollama hanya menyebarkan model ke beberapa GPU ketika model tidak lagi muat dengan bersih di satu kartu.
Pertimbangan Melewati Sensor

Untuk perbandingan perilaku, jaga kondisi tetap terkontrol sehingga Anda lebih menguji model daripada keacakan. Gunakan endpoint yang sama, prompt yang sama, stream: false, temperature rendah, dan seed tetap:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'Kemudian ulangi permintaan yang sama dengan “model”: “dolphin3”. Seed tetap tidak menghapus semua varians, tetapi mengurangi keacakan yang cukup untuk membuat perbedaan nada dan kepatuhan lebih mudah dilihat.
- Prompt aman pertama adalah: “Apakah self-hosting LLM berarti pengguna sepenuhnya mengendalikan perilaku model? Jawab dalam 4 poin. Langsung dan lewati pembuka.” Jawaban llama3.1:8b yang representatif cenderung terdengar seperti ini:
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.Jawaban dolphin3 yang representatif untuk prompt yang sama sering terdengar lebih sederhana:
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - Prompt kedua yang berguna adalah: “Tulis argumen tajam lima kalimat mengapa tim yang sensitif terhadap privasi mungkin menolak AI yang dikelola vendor. Tanpa intro dan tanpa kesimpulan.” llama3.1:8b biasanya mematuhi, tetapi dengan nada korporat yang lebih terukur. dolphin3 lebih mudah mengikuti ketajaman yang diminta. Itulah jenis perbedaan yang Anda cari di sini: bukan output yang dramatis dan tanpa hukum, tetapi perubahan dalam kelangsungan, framing, dan kepadatan penafian.
- Kategori prompt ketiga untuk validasi dapat berupa: minta lima alasan faktual mengapa seorang penulis mungkin lebih memilih model lokal untuk pekerjaan kreatif yang tidak biasa, khusus, atau tidak arus utama. Dalam praktiknya, kedua model menjawab, tetapi dolphin3 cenderung tetap lebih dekat pada nada non-moralisasi yang diminta, dan jawaban langsung.
Polanya terlihat seperti ini:
| Jenis prompt | Perilaku baseline llama3.1:8b | Perilaku dolphin3 | Kesimpulan praktis |
|---|---|---|---|
| Kelangsungan vs ketidakpastian | Lebih berhati-hati, sedikit lebih penjelasan | Lebih ringkas dan langsung | Fakta yang sama, gaya penolakan/penafian berbeda |
| Kepatuhan nada yang lebih tajam | Sering menjawab, tetapi melembutkan retorika | Lebih mau mengikuti tepi yang diminta | Kepatuhan framing adalah bagian dari pilihan model |
| Framing kreatif yang tidak biasa | Faktual, terkadang berisi padding | Faktual, biasanya kurang bermoralisasi | “Kurang dibatasi” sering muncul sebagai nada, bukan kemampuan murni |
Dan dengan demikian, berikut adalah kesimpulan yang jujur:
- Pilihan model lokal secara signifikan mengubah perilaku output.
- Model yang berbeda bervariasi dalam kelangsungan dan kepadatan penafian.
- Self-hosting menghapus lapisan penyajian yang dikendalikan vendor.
Anda Sekarang Mengendalikan Tumpukan, Bukan Hanya Prompt

Frustrasi dari awal panduan ini tidak pernah hanya tentang model yang menolak permintaan. Ini adalah tentang fakta bahwa lapisan penyajian, lapisan kebijakan, dan batas privasi berada di tempat lain. Setelah pengaturan ini, bagian itu telah berubah. Server inferensi Anda berjalan di mesin Ubuntu Anda, batas API lokal milik Anda, menu model milik Anda, dan default prompt/runtime milik Anda untuk disetel.
Yang masih memerlukan pertimbangan adalah bagian yang tidak dapat diselesaikan oleh penginstal mana pun untuk Anda: memilih model yang sesuai dengan kasus penggunaan Anda, mengarahkannya dengan default yang wajar, dan mengekspos akses dengan aman jika Anda bergerak melampaui localhost. Itulah bentuk nyata dari kontrol self-hosting. Bukan kebebasan ajaib dari setiap batasan, tetapi kepemilikan tumpukan yang memutuskan bagaimana, di mana, dan dengan model mana inferensi terjadi. Jika Anda menginginkan langkah terbaik berikutnya, mulailah dengan membuat Modelfile kustom — atau dengan menempatkan akses jarak jauh yang aman di depan API lokal ketika Anda siap.
Apa yang Harus Dilakukan Setelah Pengaturan Dasar

Pada titik ini, janji inti terpenuhi. Server berfungsi, API berfungsi, jalur GPU nyata, dan perbedaan perilaku model tidak lagi abstrak. Langkah berikutnya bukan “instal lebih banyak hal secara membabi buta.” Ini adalah untuk menyetel bagian-bagian dari tumpukan yang sekarang menjadi milik Anda.
Menyesuaikan Perilaku Model dengan Modelfile
Modelfile adalah cara paling bersih untuk mengubah default prompting lokal tanpa menyentuh bobot model itu sendiri. Mulai dengan memeriksa definisi model saat ini sehingga Anda memahami apa yang Anda perluas:
ollama show --modelfile dolphin3
Kemudian buat variasi lokal yang sederhana:
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192Bangun sebagai nama model baru dan uji:
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ Penting: Modelfile mengubah perilaku prompting dan runtime, bukan riwayat training model. Ini dapat mengarahkan nada dan default, tetapi tidak melatih ulang model yang mendasarinya.
Mengamankan Pengaturan
Binding localhost adalah default yang baik, tetapi itu bukan akhir dari cerita keamanan. Periksa kembali alamat listen saat ini terlebih dahulu:
ss -tlnp | grep 11434
Jika tujuannya adalah menjaga Ollama hanya-lokal, tetapkan perilaku tersebut secara eksplisit dengan override systemd:
sudo systemctl edit ollama
Tambahkan yang berikut ini:
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
Kemudian muat ulang dan restart layanan:
sudo systemctl daemon-reload
sudo systemctl restart ollamaJika Anda membutuhkan akses jarak jauh nanti, jangan publikasikan 11434 secara langsung. Pasang reverse proxy dengan TLS dan autentikasi di depannya:
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ Peringatan: Perlakukan paparan publik sebagai proyek penguatan keamanan yang terpisah. Ollama sendiri adalah server inferensi lokal, bukan gateway API publik siap produksi dengan autentikasi bawaan, pembatasan laju, dan default yang menghadap internet.
Model yang Direkomendasikan untuk Perangkat Keras Ini
Setelah instalasi dasar berfungsi, peningkatan nilai tertinggi adalah memilih model yang benar-benar sesuai dengan mesin ini daripada mengejar yang terbesar. Untuk server GPU tunggal 4070 Ti SUPER yang digunakan di sini, menu praktisnya terlihat seperti ini:
| Kasus penggunaan | Model | Ukuran | Penempatan yang diharapkan | Mengapa sesuai dengan mesin ini |
|---|---|---|---|---|
| Keberhasilan pertama | mistral | 4.4GB | GPU tunggal | Validasi cepat, sederhana, minim hambatan |
| Baseline umum | llama3.1:8b | 4.9GB | GPU tunggal | Titik referensi mainstream yang kuat |
| 8B yang kurang dibatasi | dolphin3 | 4.9GB | GPU tunggal | Perbandingan like-for-like terbaik dengan llama3.1:8b |
| Tingkat penalaran | gpt-oss:20b | 14GB | Biasanya GPU tunggal | Penalaran yang lebih kuat sambil masih muat dengan bersih |
| Tingkat lokal berkualitas lebih tinggi | qwen3:30b | 19GB | Membutuhkan dual-GPU atau VRAM yang lebih besar | Lebih baik sebagai target peningkatan di masa depan daripada kesesuaian bersih untuk mesin yang tepat ini |
| Tingkat berfokus kode | deepseek-coder:33b | 19GB | Membutuhkan dual-GPU atau VRAM yang lebih besar | Pilihan kuat jika Anda beralih ke kotak yang lebih besar atau menambahkan GPU kedua nanti |
| Hanya eksperimental | llama3.1:70b | 43GB | CPU spill parah / jauh lebih lambat / tradeoff konteks yang dikurangi | Bukan target yang realistis untuk host ini kecuali Anda menerima kompromi berat |
Auto-Start dan Pemeliharaan
Setelah bagian yang menyenangkan, datanglah bagian yang menjaga server LLM lokal tetap dapat digunakan sebulan dari sekarang. Konfirmasi perilaku boot-time, jaga layanan tetap diperbarui, pantau log, dan ketahui cara membongkar model besar ketika Anda membutuhkan VRAM kembali.
sudo systemctl is-enabled ollama
sudo systemctl enable --now ollama
curl -fsSL https://ollama.com/install.sh | sh
journalctl -u ollama -n 100 --no-pager
Untuk operasi model sehari-hari, berikut adalah perintah yang paling sering Anda gunakan:
ollama list
ollama ps
ollama stop gpt-oss:20b
sudo du -sh /usr/share/ollama/.ollama/modelsDan jika penyimpanan model harus dipindahkan ke disk yang lebih besar, siapkan direktori untuk pengguna layanan sebelum Anda mengarahkan ulang Ollama:
sudo mkdir -p /mnt/ai/ollama-models
sudo chown -R ollama:ollama /mnt/ai/ollama-modelsKemudian atur OLLAMA_MODELS melalui systemctl edit ollama. Detail kepemilikan itulah yang mencegah migrasi penyimpanan berubah menjadi masalah izin.
Referensi Pemecahan Masalah
Ketika sesuatu rusak, jalur tercepat biasanya mencocokkan gejala dengan lapisan yang tepat daripada mencoba loop penginstalan ulang secara acak. Gunakan tabel ini sebagai langkah pertama:
| Gejala | Kemungkinan penyebab | Periksa | Perbaikan |
|---|---|---|---|
| nvidia-smi gagal | Masalah driver atau tumpukan GPU | nvidia-smi, lspci -nnk | grep -A3 -Ei ‘VGA|3D|NVIDIA’, ubuntu-drivers devices | Perbaiki lapisan NVIDIA terlebih dahulu; jika Ubuntu menggunakan nouveau, instal driver NVIDIA yang direkomendasikan, reboot, dan jalankan kembali nvidia-smi |
| ollama.service tidak mau mulai | Masalah layanan, izin, atau bind | systemctl status ollama, journalctl -u ollama -n 100 –no-pager | Selesaikan kesalahan layanan sebelum menarik model |
| Model berjalan di CPU | Penemuan GPU gagal atau terjadi fallback | ollama ps, log | Restart layanan; jika diperlukan muat ulang nvidia_uvm |
| Hanya satu GPU yang aktif | Model muat di satu kartu | watch -n 1 nvidia-smi | Ini normal; pada host multi-GPU, uji dengan model yang melebihi selubung VRAM satu kartu jika Anda ingin mengamati penempatan multi-GPU |
| Port 11434 terekspos di 0.0.0.0 | Alamat bind berubah | ss -tlnp | grep 11434 | Atur OLLAMA_HOST=127.0.0.1:11434 dan restart |
| Kesalahan jalur model setelah memindahkan penyimpanan | Kepemilikan yang salah pada direktori model | ls -ld <model-dir> | sudo chown -R ollama:ollama <model-dir> |
| GPU menghilang setelah suspend/resume | Masalah NVIDIA UVM | log dan pemeriksaan GPU | Muat ulang nvidia_uvm dan restart layanan jika diperlukan |
Jika Anda hanya mengingat satu aturan operasional dari bagian ini, jadikan ini: perlakukan Ollama seperti layanan nyata, bukan utilitas CLI yang bisa dibuang. Log, kepemilikan, alamat bind, dan jalur penyimpanan sama pentingnya dengan jendela prompt.


