 Русский
Русский English
English  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 на всех хостинговых услугах
на всех хостинговых услугахРазместите Ollama на LLM-сервере самостоятельно и возьмите под контроль цензуру ИИ
Ключевые слова
Прежде чем приступить к настройке, ознакомьтесь с терминами, которые чаще всего вызывают затруднения у читателей этого руководства. Краткий глоссарий поможет сразу разобраться в терминологии Linux, GPU и локальных моделей.
| Ключевое слово | Краткое пояснение |
|---|---|
| 🤖 LLM | Большая языковая модель; модель искусственного интеллекта, генерирующая текст на основе запросов. |
| 🦙 Ollama | Локальный запускатель и сервер моделей для загрузки, обслуживания и вызова LLM на собственном компьютере. |
| 🖥️ GPU | Графический процессор, используемый здесь для ускорения инференса модели. |
| 💾 VRAM | Память GPU; является одним из основных ограничений по размеру модели, которую можно разместить на видеокарте. |
| ⚡ Inference | Процесс запуска модели для генерации ответа. |
| 🔄 systemd | Менеджер служб Linux, используемый для запуска, остановки, перезапуска и включения служб, таких как Ollama. |
| 🧩 NVIDIA driver | Программный слой, обеспечивающий корректное взаимодействие Ubuntu с GPU NVIDIA для вычислительных задач. |
| 🚫 nouveau | Графический драйвер Linux с открытым исходным кодом, который может препятствовать правильной настройке вычислений NVIDIA, если используется вместо официального драйвера NVIDIA. |
| 📊 nvidia-smi | Инструмент командной строки NVIDIA для проверки видимости GPU, использования VRAM и состояния драйвера. |
| 🔌 API endpoint | URL, по которому инструменты или скрипты отправляют запросы в Ollama и получают ответы. |
| ☁️ Vendor-controlled serving layer | Управляемый провайдером слой API, который может добавлять модерацию, ведение журналов, применение политик и другие элементы управления перед тем, как модель ответит. |
| 🧬 Fine-tune | Модифицированная версия базовой модели, настроенная под другой тон, поведение или специализированные задачи. |
| ⚖️ Model weights | Выученные внутренние параметры модели; самостоятельный хостинг автоматически их не изменяет. |
| 📝 Modelfile | Файл Ollama, используемый для создания пользовательского варианта локальной модели с собственным системным промптом и параметрами времени выполнения. |
| 🪪 UUID | Стабильный аппаратный идентификатор GPU; зачастую надёжнее числовых идентификаторов GPU, поскольку порядок устройств может меняться. |
| 🔒 TLS | Шифрование, используемое HTTPS и обратными прокси для защиты трафика между клиентами и сервером. |
| 🌐 Reverse proxy | Внешний сервис, который может добавлять TLS, аутентификацию и контролируемый публичный доступ перед перенаправлением запросов в Ollama. |
| 🎛️ Temperature / seed | Параметры генерации; temperature влияет на случайность, а фиксированный seed помогает сделать повторные тесты более сопоставимыми. |
| 🧱 CPU spill / mixed path | Ситуация, когда часть модели или рабочей нагрузки выходит за пределы памяти GPU и использует ресурсы CPU, что может замедлить инференс. |
| 🔧 nvidia_uvm | Модуль ядра NVIDIA, связанный с управлением памятью GPU, который иногда требует перезагрузки в процессе устранения неполадок. |
Почему стоит самостоятельно размещать LLM

Если вы уже прошли сложный путь — арендовали GPU-сервер, установили Ubuntu, освоили работу с SSH и поддерживаете собственные сервисы в рабочем состоянии, — то быстро начинаешь испытывать разочарование, когда размещённый у провайдера ИИ всё равно контролирует последнее звено. Он может отклонить совершенно обычный запрос, утопить ответ в оговорках, без предупреждения изменить стиль ответов и пропускать каждый промпт через чужие ограничения. Для многих технических пользователей это и есть настоящая проблема: не только то, что модель говорит, но и кто контролирует слой обслуживания в момент её ответа.
Это руководство посвящено решению данной проблемы с помощью открытых и локальных моделей, а не обходным приёмам для проприетарных API. Вы самостоятельно разместите Ollama на Ubuntu GPU-сервере, запустите инференс локально, убедитесь, что путь через GPU реален, и увидите, что меняется при выборе другого семейства моделей. Важно прояснить одно заблуждение: самостоятельный хостинг не означает автоматически отсутствие ограничений. Это означает, что вы контролируете значительно большую часть стека и перестаёте зависеть от пути обслуживания, управляемого провайдером, однако запускаемая вами модель всё равно может сохранять собственное поведение выравнивания.
📝 Примечание: Команды в этом руководстве проверены на соответствие актуальной документации Ollama, однако приведённые ниже результаты в терминале являются репрезентативными примерами, а не реальными снимками результатов бенчмарков. Используйте их как образец успешного выполнения, а не как заявление о производительности.
По завершении у вас будет работающий сервис Ollama на Ubuntu, проверенный локальный API по адресу 127.0.0.1:11434, подтверждение того, что GPU-инференс действительно происходит, а также обоснованное сравнение между основной выровненной моделью и менее ограниченной альтернативой. Это руководство написано для читателей, уверенно работающих с SSH, Ubuntu, sudo и systemd, но не имеющих предварительного опыта работы с Ollama.
Конкретный Ubuntu GPU-сервер, использованный в этом руководстве

Это руководство основано на реальной однопроцессорной машине Ubuntu с одним GPU, поскольку расплывчатые советы «должно работать на большинстве серверов» превращают руководства по самостоятельному хостингу в источник заблуждений. Эталонная машина здесь — это реальный класс хоста, использованного для данного руководства: именно такую машину арендует продвинутый пользователь, лаборатория или небольшая команда, когда им нужен частный локальный инференс без немедленного перехода к стойке корпоративных ускорителей. Далее будет рассмотрено поведение при нескольких GPU, поскольку Ollama меняется, когда модель не умещается на одной карте, однако эту часть следует воспринимать как перспективный контекст, а не как доказательство на основе данного конкретного сервера.
GPU-сервер — Ryzen 9 3950X + RTX 4070 Ti Super
| Компонент | Характеристики |
|---|---|
| CPU | AMD Ryzen 9 3950X (16 ядер / 32 потока) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| Возможности | Отлично подходит для моделей класса 8B; более крупные модели требуют решения о переносе части нагрузки на CPU или обновлении |
На практике это очень мощная конфигурация для повседневных моделей класса 8B и всё ещё полезная для более крупных локальных задач вплоть до момента, когда 16GB VRAM становятся реальным ограничением. Такая модель, как llama3.1:8b размером примерно 4.9GB, легко помещается на этой карте. Модель gpt-oss:20b размером около 14GB — это верхняя граница теста на одном GPU, которая всё ещё имеет смысл для данной машины. Модель qwen3:30b размером около 19GB лучше рассматривать как ориентир для понимания того, что меняется на более крупном или двухпроцессорном хосте, а не как вариант для этой конкретной машины.
Это различие важно, поскольку цель данной статьи — не вписать наибольшее возможное число в заголовок. Цель — показать, как выглядит разумный самостоятельно размещённый LLM-сервер, когда вам нужны конфиденциальность, локальный контроль и достаточно GPU-памяти для запуска полезных моделей без постоянных компромиссов. Этот класс оборудования — тот уровень, где самостоятельный инференс становится реальностью, а не теорией.
Это также объясняет ряд решений, которые вы увидите далее: mistral используется первым, поскольку обеспечивает быстрое и простое доказательство работоспособности стека, тогда как сравнение поведения остаётся в классе 8B, с которым эта машина справляется комфортно. qwen3:30b упоминается позже, но лишь как теоретический пример модели, способной задействовать несколько GPU на более мощном хосте, а не как живое доказательство с данного сервера. Теперь, когда ожидания сформированы, следующий шаг — проверить хост перед установкой Ollama.
Выполните эти предварительные проверки перед установкой Ollama

Начните с nvidia-smi. Если эта команда отсутствует или завершается с ошибкой, остановитесь и сначала исправьте драйвер NVIDIA. Не устанавливайте Ollama, пока стек NVIDIA не работает корректно: неисправная платформа заставит каждый последующий симптом выглядеть как сбой приложения, тогда как на самом деле проблема будет на уровне платформы.
Сначала выполните проверку GPU:
nvidia-smi
❗Если Ubuntu сообщает, что nvidia-smi не найден, не предполагайте, что на сервере нет GPU. Распространённая проблема на арендованных машинах Ubuntu — карта присутствует, но по-прежнему привязана к nouveau вместо драйвера NVIDIA. Сначала ознакомьтесь с разделом «Исправление проблемы с драйвером Nvidia на Ubuntu».
Исправный результат на сервере этого класса должен выглядеть примерно так:
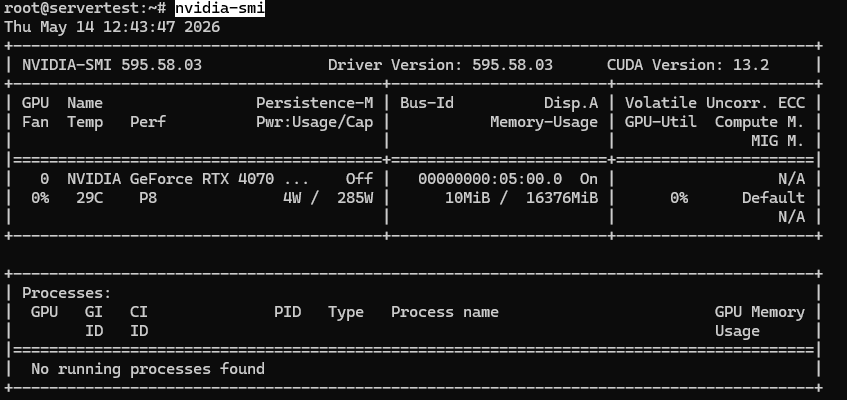
Как только nvidia-smi работает и GPU виден, продолжайте выполнение проверок ниже.
Необходимо убедиться в следующем: установленный GPU виден, сообщает о примерно 16GB VRAM на данном хосте, и драйвер загружен без ошибок. Если вы работаете на сервере с несколькими GPU, та же команда должна отобразить каждую карту.
nvidia-smi -L

❗ Важно: Актуальная документация по поддержке GPU в Ollama устанавливает NVIDIA driver 531+ в качестве реальной минимальной версии для поддерживаемого инференса NVIDIA. Считайте 531+ обязательным требованием для данного руководства, даже если вы встречали старые материалы сообщества с упоминанием более ранних версий.
Теперь убедитесь, что хост действительно является той средой Ubuntu, которую предполагает данное руководство:
lsb_release -a
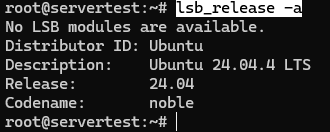
Наконец, перед загрузкой моделей проверьте свободное место на диске. Сам установщик занимает мало места; модели — нет. Как только вы выйдете за рамки небольших тестов, библиотека моделей размером 20B–30B может быстро занять десятки гигабайт, поэтому перед серьёзной работой с локальными моделями рекомендуется иметь 100GB+ свободного места.
df -h /

Если все проверки пройдены, вы устранили основные неизвестные факторы инфраструктуры: GPU присутствуют, базовая версия драйвера корректна, Ubuntu подтверждена, а на диске достаточно места для загрузки реальных моделей. Именно в этот момент установка Ollama становится логичным следующим шагом, а не догадкой.
Исправление проблемы с драйвером Nvidia на Ubuntu
Выполните приведённые ниже шаги для устранения проблем с командой «nvidia-smi».
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
Если в выводе отображается карта NVIDIA и строка вида Kernel driver in use: nouveau, установите рекомендованный пакет драйвера Ubuntu вместо установки только nvidia-utils.
Установите пакет ubuntu-drivers-common (необходим для управления драйверами) и заголовочные файлы ядра для текущей запущенной версии ядра.
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)Выполните сканирование системы и выведите список доступных проприетарных драйверов (например, драйверов GPU NVIDIA), которые можно установить.
ubuntu-drivers devices
Затем установите рекомендованный пакет драйвера. В нашем случае это был: nvidia-driver-595-open:
apt install -y nvidia-driver-595-open
rebootПосле перезагрузки повторно выполните:
nvidia-smi
nvidia-smi -LУстановка Ollama и проверка работоспособности сервиса

Поддерживаемый путь для Ubuntu — официальный установщик Ollama, а не пользовательский архивный процесс и не способ через Docker. Это важно, поскольку данное руководство посвящено созданию надёжного локального сервиса с предсказуемыми настройками по умолчанию, интеграцией systemd и корректным управлением правами владения в Linux.
Запустите установщик точно так, как указано в документации:
curl -fsSL https://ollama.com/install.sh | sh
На исправной системе скрипт устанавливает бинарный файл, создаёт пользователя сервиса ollama, при необходимости добавляет правильные членства в группах, записывает юнит systemd и запускает сервис, привязанный к 127.0.0.1:11434.
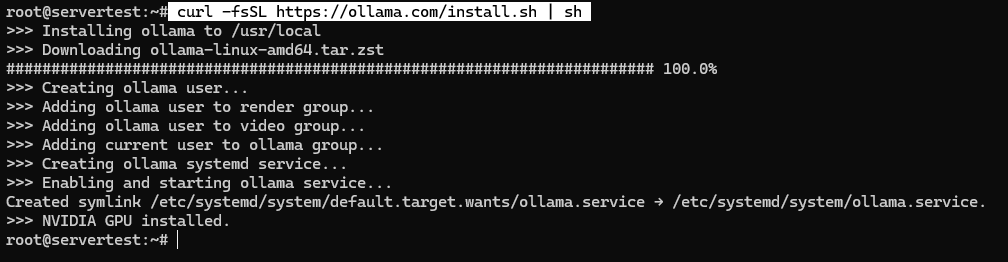
После завершения работы скрипта проверьте сервис вместо того, чтобы предполагать успешную установку:
sudo systemctl status ollama --no-pager
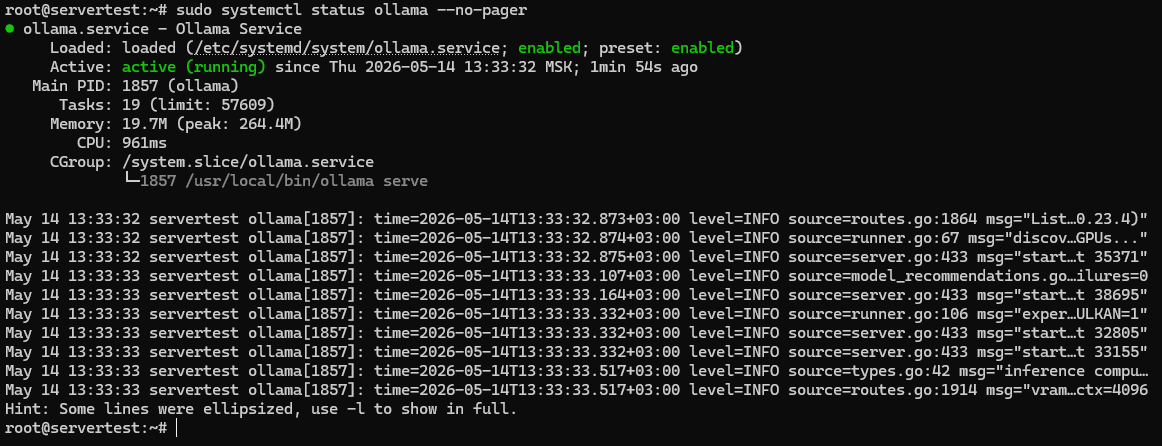
Здесь нужно убедиться в трёх вещах: файл юнита присутствует, сервис включён для автозапуска при загрузке, и Active: active (running) подтверждает, что сервер действительно работает.
Сначала чётко установите учётную запись пользователя сервиса Linux, и только после этого думайте о том, как и где будет организовано хранение моделей.
getent passwd ollama

Эта одна строка объясняет многое в будущем поведении системы. Модели в Linux находятся под владением пользователя сервиса, и если впоследствии вы перенесёте их на другой диск, не исправив права для пользователя ollama, вы сами создадите себе проблему.
Ещё одна проверка завершает картину относительно привязки по умолчанию:
ss -tlnp | grep 11434

⚠️ Предупреждение: По умолчанию Ollama не требует аутентификации для локального API. Это приемлемо, когда он привязан к 127.0.0.1, однако открывать порт 11434 напрямую в интернет как защищённый публичный сервис небезопасно.
Если сервис не запускается корректно, сначала обратитесь к журналам, а не переустанавливайте вслепую:
journalctl -u ollama -n 100 --no-pager
Это самый быстрый способ обнаружить проблемы с правами доступа, ошибки запуска, проблемы с обнаружением драйвера или проблемы с привязкой. Как только сервис корректно работает на localhost, следующее, что нужно понять, — это поведение размещения на GPU во время работы.
Как Ollama реально использует один или несколько GPU
Несмотря на то что сервер, используемый в этом руководстве, оснащён одним GPU, поведение при нескольких GPU всё равно стоит понять, поскольку многие пользователи могут работать на более мощных машинах или планируют расширение в будущем. Большинство заблуждений при наличии двух GPU начинаются с неверных ожиданий: «У меня две карты, значит обе должны быть задействованы постоянно». Ollama работает иначе. Практическое правило значительно проще: если модель умещается на одном GPU, Ollama обычно оставляет её на одном GPU. Распределение между несколькими GPU происходит только тогда, когда модель не помещается на одной карте.
Используйте эти две проверки вместе каждый раз, когда хотите увидеть производительность GPU:
ollama ps
watch -n 1 nvidia-smi
ollama ps показывает, как обрабатывается загруженная модель. 100% GPU означает, что модель полностью размещена в памяти GPU. 100% CPU означает, что GPU-ускорение не используется. Смешанное состояние говорит о том, что часть рабочей нагрузки или часть модели вышла за пределы пути через GPU. watch -n 1 nvidia-smi дополняет это, показывая в реальном времени использование VRAM на каждой карте во время загрузки модели.
Самый простой способ запомнить роль каждой команды:
| Команда | Что доказывает | Что не доказывает |
|---|---|---|
| ollama ps | Работает ли модель на GPU, CPU или по смешанному пути | Какая именно карта или карты несут нагрузку |
| watch -n 1 nvidia-smi | Активность VRAM в реальном времени по каждому GPU | Означает ли использование двух GPU автоматически лучший выбор модели |
📝 Примечание: CUDA_VISIBLE_DEVICES — это элемент управления видимостью, а не переключатель «использовать оба GPU». Если вам когда-либо потребуется ограничить доступ к GPU, предпочтительнее использовать UUID из nvidia-smi -L, а не числовые идентификаторы, поскольку порядок GPU может меняться в разных средах и после перезагрузок.
Запустите первую локальную модель и проверьте инференс на GPU
На данном этапе для проверки работоспособности сервера не нужна огромная модель. Нужен быстрый и очевидный успех. mistral — хороший выбор для первой загрузки: она небольшая, быстро скачивается и легко загружается, хотя позднее llama3.1:8b станет основным ориентиром для сравнения поведения моделей.
Начните с загрузки модели:
ollama pull mistral

Теперь выполните небольшой запрос, чтобы машина сделала что-то полезное, а не только административное. Ответ может занять несколько секунд.
ollama run mistral "In one sentence, explain why people self-host LLMs."

Чтобы убедиться, что это инференс с использованием GPU, а не откат к CPU, проверьте состояние во время выполнения:
ollama ps

Чтобы увидеть, что уже находится на диске, выведите список локальных моделей:
ollama list

mistral — правильный первый тест, поскольку даёт быстрый ответ, не превращая проверку настройки в долгое ожидание. Позже llama3.1:8b становится более полезной, поскольку представляет собой более качественный выровненный ориентир для сравнения поведения моделей.
Наконец, проверьте, где Linux-установка хранит модели:
sudo du -sh /usr/share/ollama/.ollama/models

Этот путь — /usr/share/ollama/.ollama/models — является стандартным хранилищем моделей для Linux, задокументированным Ollama.
Как только вы видите успешный ответ, 100% GPU в ollama ps и увеличение использования диска в ожидаемом месте, у вас есть первое значимое доказательство работоспособности локального стека.
Докажите, что это сервер, а не просто обёртка для CLI

Запрос через командную строку — это хорошо, но цель самостоятельного размещения Ollama — не только вести чат в терминале. Цель — запустить локальный сервер инференса, к которому смогут обращаться другие инструменты, скрипты и приложения, не отправляя промпты через чужую границу API. Самое быстрое доказательство — один чистый HTTP-запрос к нативному эндпоинту Ollama.
Отправьте локальный запрос generate с отключённой потоковой передачей, чтобы первый ответ было легко проанализировать:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'Успешный ответ должен вернуться в формате JSON и выглядеть примерно так:
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
Контрольный список успеха прост: HTTP-запрос работает локально, возвращается корректный JSON, присутствует done: true, и ответ модели находится в поле response. Именно в этот момент Ollama перестаёт быть «CLI, который заодно скачивает модели» и становится инфраструктурой, которую можно реально интегрировать в локальные инструменты и автоматизацию.
Если вам нужна совместимость с программным обеспечением, ожидающим формат запросов в стиле OpenAI, Ollama также предоставляет эндпоинты /v1 локально:
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 Примечание: Ярлык «совместимый с OpenAI» легко понять неправильно. Это не означает, что вы обращаетесь к OpenAI, и не меняет того факта, что сервер по-прежнему локальный. Это означает лишь, что формат запроса достаточно знаком для инструментов и SDK, созданных на основе шаблона OpenAI API. Базовый URL остаётся http://localhost:11434/v1/, а любой ключ API-заполнитель, на котором настаивают некоторые клиентские библиотеки, можно игнорировать при локальном использовании Ollama.
Откуда на самом деле берутся ограничения модели

Эта часть обычно сводится к одной расплывчатой идее о «цензуре», однако технически здесь задействованы три разных уровня: слой обслуживания провайдера, выравнивание модели и её настройка для следования инструкциям, а также поведение промптов и среды выполнения, которое вы контролируете сами. Самостоятельный хостинг кардинально меняет одни из этих уровней. Другие — нет.
Простой способ представить это:
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
Результаты:
– Слой обслуживания, управляемый провайдером, исчезает из локального пути
– Граница локальной сети и ведение журналов становятся вашими
– Собственное обучение модели и её выравнивание по-прежнему поставляются вместе с моделью
Как только вы разграничиваете уровни, предыдущие шаги настройки приобретают куда более глубокий смысл:
| Уровень | Контролируется локально после настройки? | Доказательство | Что по-прежнему остаётся верным |
|---|---|---|---|
| Процесс сервера | Да | ollama.service работает на Ubuntu | Вы теперь контролируете время работы, журналы, обновления и адрес привязки |
| Граница сети | Да | Проверка привязки 127.0.0.1:11434 | Локальные запросы больше не требуют прохождения через модерацию провайдера |
| Системный промпт / настройки по умолчанию | Да | Modelfile для управляемого системного сообщения | Вы можете направлять поведение, но не переписывать обучение |
| Слой модерации на стороне провайдера | Как правило, убирается при локальном инференсе | Вызов локального нативного API успешно выполняется на localhost | Это одно из самых значительных изменений в контроле, которое даёт самостоятельный хостинг |
| Выравнивание модели в весах | Нет, не автоматически | Разная настройка модели даёт разные результаты | Локальная модель по-прежнему может уклоняться от ответов, отказывать или морализировать |
| Выбор семейства моделей | Да | llama3.1:8b против dolphin3 | Выберите ту, которая лучше всего соответствует вашим потребностям |
Можно представить это как театральную постановку. Самостоятельный хостинг меняет сцену, освещение, микрофоны и режиссёрские указания. Он не переобучает актёра. Если модель была настроена отвечать осторожно, часто уклоняться или отказывать на определённые запросы, запуск её локально не отменит это обучение волшебным образом.
То, что ваша текущая настройка уже доказала, более конкретно, но всё же важно: вы контролируете процесс сервера, вы контролируете границу API, и вы больше не направляете локальные промпты через управляемый провайдером слой модерации. Это реальный сдвиг в конфиденциальности и контроле. Что это не доказало, так это то, что каждая локальная модель будет вести себя одинаково или что каждый отказ в будущем был вызван облачным провайдером.
Именно здесь вступает в игру выбор модели. Если вы хотите практического эффекта в виде меньшего числа оговорок, более прямых ответов или менее отказчивого поведения, вы не добьётесь этого, просто говоря «самостоятельный хостинг» громче. Вы добьётесь этого, выбрав другое семейство моделей или fine-tune — и понимая сопутствующие компромиссы.
Выбор менее ограниченной локальной модели

Для честного теста сравнивайте модели примерно одного класса по размеру. Именно поэтому в данном руководстве используется llama3.1:8b как основной выровненный ориентир и dolphin3 как сравниваемая менее ограниченная модель. Обе весят около 4.9GB, что облегчает интерпретацию различий в поведении без существенного изменения нагрузки на оборудование.
Загрузите сравниваемые модели локально:
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistralВот практическое описание трёх названий, которые вы чаще всего встретите в этой части экосистемы Ollama:
| Модель | Примерный размер | Роль в статье | Практическая оценка |
|---|---|---|---|
| llama3.1:8b | 4.9GB | Основной выровненный ориентир | Хорошая точка отсчёта для «нормального» поведения современных моделей при следовании инструкциям |
| dolphin3 | 4.9GB | Основная менее ограниченная сравниваемая модель | Схожий размер, как правило более прямолинейная, часто менее перегруженная оговорками |
| dolphin-mistral | 4.1GB | Необязательная более старая альтернатива | Всё ещё полезна в историческом контексте, но не лучший актуальный вариант для повседневного сравнения |
⚠️ Предупреждение: Другой fine-tune — это не «та же модель с убранной цензурой». Он может изменить прямолинейность, плотность оговорок и готовность следовать пользовательской формулировке, но также может изменить тон, точность, последовательность и общую индивидуальность модели.
Производительность GPU
Перед запуском нужных моделей необходимо понять возможности и ограничения задействованного оборудования. Концептуально нужно протестировать два аспекта: во-первых, как выглядит чистое поведение одного GPU на реальном оборудовании, используемом в этом руководстве; во-вторых, что меняется при запуске того же стека на хосте с двумя GPU. Оба аспекта важны, однако только первый является живым доказательством с данной конкретной машины.
На этом сервере лучшим верхним тестом во время выполнения является gpt-oss:20b. Он достаточно большой, чтобы быть интересным, и при этом всё ещё имеет смысл на одной карте с 16GB.
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
После загрузки модели подтвердите состояние среды выполнения:
ollama ps

Это практическое доказательство, которое нужно получить на данной машине. Оно показывает, что меньшие модели легко помещаются, а более крупная, но всё ещё реалистичная локальная модель способна загрузить одну карту с 16GB почти до предела без необходимости в нескольких GPU.
Если впоследствии вы запустите Ollama на хосте с двумя GPU, такая модель, как qwen3:30b, станет той рабочей нагрузкой, которая может продемонстрировать распределение между несколькими GPU. Рабочий процесс тот же — следите за nvidia-smi, запустите модель, проверьте ollama ps — однако суть не в том, чтобы ради самого факта задействовать обе карты. Суть в том, чтобы убедиться: Ollama распределяет модель между несколькими GPU только тогда, когда она перестаёт чисто умещаться на одной карте.
Вопросы обхода цензуры

Для сравнения поведения моделей сохраняйте контролируемые условия, чтобы тестировать модель, а не случайность. Используйте одинаковый эндпоинт, одинаковый промпт, stream: false, низкую температуру и фиксированный seed:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'Затем повторите тот же запрос с “model”: “dolphin3”. Фиксированный seed не устраняет всю вариативность, но снижает достаточно случайности, чтобы различия в тоне и степени выполнения инструкций стали более заметными.
- Безопасный первый промпт: «Означает ли самостоятельный хостинг LLM, что пользователь полностью контролирует поведение модели? Ответьте в 4 тезисах. Будьте прямолинейны и опустите вступления.» Типичный ответ llama3.1:8b звучит примерно так:
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.Типичный ответ dolphin3 на тот же промпт зачастую выглядит более лаконично:
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - Второй полезный промпт: «Напишите пять чётких предложений в защиту того, почему команда, работающая с конфиденциальными данными, может отказаться от ИИ, управляемого провайдером. Без вступления и заключения.» llama3.1:8b обычно выполняет задание, но в более сдержанном корпоративном тоне. dolphin3 легче следует запрошенной резкости. Именно такого рода различие здесь ищется: не кардинально иной вывод, а изменения в прямолинейности, формулировке и плотности оговорок.
- Третья категория промптов для проверки может быть следующей: попросить пять фактических причин, по которым писатель может предпочесть локальную модель для нестандартной, нишевой или неосновной творческой работы. На практике обе модели отвечают, но dolphin3, как правило, придерживается запрошенного не-морализаторского тона и даёт более прямые ответы.
Закономерность выглядит следующим образом:
| Тип промпта | Базовое поведение llama3.1:8b | Поведение dolphin3 | Практический вывод |
|---|---|---|---|
| Прямолинейность vs уклончивость | Более осторожный, немного более многословный | Более сжатый и прямолинейный | Те же факты, разный стиль отказов/оговорок |
| Соблюдение более резкого тона | Как правило отвечает, но смягчает риторику | Охотнее следует запрошенной резкости | Послушность в формулировке — часть выбора модели |
| Нишевая творческая формулировка | Фактически, иногда перегружен | Фактически, обычно менее морализаторский | «Менее ограниченный» часто проявляется как тон, а не чистые возможности |
И вот честные выводы:
- Выбор локальной модели существенно меняет поведение вывода.
- Разные модели отличаются прямолинейностью и плотностью оговорок.
- Самостоятельный хостинг убирает управляемый провайдером слой обслуживания.
Теперь вы контролируете стек, а не только промпт

Разочарование, с которого начиналось это руководство, никогда не сводилось только к тому, что модель отклоняет запрос. Дело было в том, что слой обслуживания, слой политик и граница конфиденциальности находились где-то в другом месте. После этой настройки эта часть изменилась. Ваш сервер инференса работает на вашей машине Ubuntu, граница локального API — ваша, меню моделей — ваше, а настройки промптов и среды выполнения по умолчанию — ваши для настройки.
То, что по-прежнему требует суждения, — это часть, которую никакой установщик не решит за вас: выбор моделей, соответствующих вашему сценарию использования, управление ими с помощью разумных настроек по умолчанию и безопасное предоставление доступа, если вы выйдете за пределы localhost. Такова реальная суть контроля при самостоятельном хостинге. Не магическая свобода от всех ограничений, а владение стеком, который определяет, как, где и с какой моделью происходит инференс. Если хотите сделать лучший следующий шаг — начните с создания пользовательского Modelfile или организуйте безопасный удалённый доступ перед локальным API, когда будете готовы.
Что делать после базовой настройки

На данном этапе основное обещание выполнено. Сервер работает, API работает, путь через GPU реален, а различия в поведении моделей больше не абстрактны. Следующий шаг — не «устанавливать больше всего подряд». Это настройка тех частей стека, которые теперь принадлежат вам.
Настройка поведения модели с помощью Modelfile
Modelfile — это самый чистый способ изменить локальные настройки промптов по умолчанию, не затрагивая веса модели. Начните с проверки текущего определения модели, чтобы понять, что вы расширяете:
ollama show --modelfile dolphin3
Затем создайте простой локальный вариант:
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192Соберите его под новым именем модели и протестируйте:
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ Важно: Modelfile изменяет поведение при промптинге и во время выполнения, но не историю обучения модели. Он может задавать тон и настройки по умолчанию, но не переобучает базовую модель.
Защита настройки
Привязка к localhost — хорошее значение по умолчанию, но это не конец истории безопасности. Сначала повторно проверьте текущий адрес прослушивания:
ss -tlnp | grep 11434
Если цель — оставить Ollama только локальным, явно закрепите это поведение с помощью переопределения systemd:
sudo systemctl edit ollama
Добавьте следующее:
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
Затем перезагрузите и перезапустите сервис:
sudo systemctl daemon-reload
sudo systemctl restart ollamaЕсли впоследствии вам понадобится удалённый доступ, не публикуйте 11434 напрямую. Вместо этого поставьте перед ним обратный прокси с TLS и аутентификацией:
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ Предупреждение: Относитесь к публичному доступу как к отдельному проекту по защите. Сам по себе Ollama — это локальный сервер инференса, а не готовый к производству публичный API-шлюз со встроенной аутентификацией, ограничением запросов и настройками для работы в интернете.
Рекомендуемые модели для данного оборудования
После успешной базовой установки наиболее ценным улучшением является выбор моделей, которые действительно хорошо подходят для этой машины, а не погоня за самым громким заголовком. Для сервера с одним GPU RTX 4070 Ti Super, используемого здесь, практическое меню выглядит следующим образом:
| Сценарий использования | Модель | Размер | Ожидаемое размещение | Почему подходит для этой машины |
|---|---|---|---|---|
| Первый успешный тест | mistral | 4.4GB | Один GPU | Быстрая, простая, проверка без лишних трудностей |
| Общий ориентир | llama3.1:8b | 4.9GB | Один GPU | Сильная основная точка отсчёта |
| Менее ограниченная 8B | dolphin3 | 4.9GB | Один GPU | Лучшее сопоставимое сравнение с llama3.1:8b |
| Уровень рассуждений | gpt-oss:20b | 14GB | Как правило один GPU | Более мощные рассуждения при чистом размещении |
| Более качественный локальный уровень | qwen3:30b | 19GB | Требует двух GPU или большего объёма VRAM | Лучше рассматривать как цель для будущего обновления, а не как подходящий вариант для этой машины |
| Ориентированный на код уровень | deepseek-coder:33b | 19GB | Требует двух GPU или большего объёма VRAM | Сильный вариант, если вы перейдёте на более мощную машину или добавите второй GPU позже |
| Только экспериментальный | llama3.1:70b | 43GB | Значительная нагрузка на CPU / намного медленнее / компромиссы по контексту | Нереалистичная цель для этого хоста, если только вы не готовы к серьёзным компромиссам |
Автозапуск и обслуживание
После увлекательной части наступает та, которая обеспечивает работоспособность локального LLM-сервера через месяц.


