 Português
Português English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 em todos os serviços de alojamento
em todos os serviços de alojamentoHospede o Ollama em um Servidor LLM e Tenha Controle sobre a Censura de IA
Palavras-chave
Antes de mergulhar na configuração, aqui estão os termos com maior probabilidade de confundir os leitores neste guia. Este glossário rápido mantém o vocabulário de Linux, GPU e modelos locais claro desde o início.
| Palavra-chave | Breve explicação |
|---|---|
| 🤖 LLM | Large Language Model; um modelo de IA que gera texto a partir de prompts. |
| 🦙 Ollama | Um executor e servidor de modelos locais para descarregar, servir e chamar LLMs na sua própria máquina. |
| 🖥️ GPU | O processador gráfico utilizado aqui para acelerar a inferência do modelo. |
| 💾 VRAM | A memória na GPU; é um dos principais limites sobre o tamanho de um modelo que pode caber numa placa. |
| ⚡ Inferência | O ato de executar um modelo para gerar uma resposta. |
| 🔄 systemd | O gestor de serviços Linux utilizado para iniciar, parar, reiniciar e ativar serviços como o Ollama. |
| 🧩 Driver NVIDIA | A camada de software que permite ao Ubuntu comunicar corretamente com a GPU NVIDIA para cargas de trabalho de computação. |
| 🚫 nouveau | Um driver gráfico Linux de código aberto que pode impedir a configuração adequada de computação NVIDIA se for utilizado em vez do driver oficial NVIDIA. |
| 📊 nvidia-smi | A ferramenta de linha de comandos da NVIDIA para verificar a visibilidade da GPU, o uso de VRAM e a saúde do driver. |
| 🔌 API endpoint | Um URL que ferramentas ou scripts chamam para enviar prompts ao Ollama e receber respostas. |
| ☁️ Camada de serviço controlada pelo fornecedor | A camada de API gerida pelo fornecedor que pode adicionar moderação, registo, aplicação de políticas ou outros controlos antes de um modelo responder. |
| 🧬 Fine-tune | Uma versão modificada de um modelo base ajustada para diferente tom, comportamento ou tarefas de propósito especial. |
| ⚖️ Pesos do modelo | Os parâmetros internos aprendidos do modelo; o auto-alojamento não os altera automaticamente. |
| 📝 Modelfile | Um ficheiro Ollama utilizado para criar uma variante de modelo local personalizada com o seu próprio prompt de sistema e parâmetros de execução. |
| 🪪 UUID | Um identificador de hardware estável para uma GPU; é frequentemente mais seguro do que IDs numéricos de GPU porque a ordem dos dispositivos pode mudar. |
| 🔒 TLS | A encriptação utilizada por HTTPS e proxies inversos para proteger o tráfego entre clientes e o servidor. |
| 🌐 Proxy inverso | Um serviço front-end que pode adicionar TLS, autenticação e acesso público controlado antes de encaminhar pedidos ao Ollama. |
| 🎛️ Temperatura / seed | Definições de geração; a temperatura afeta a aleatoriedade, enquanto um seed fixo ajuda a tornar os testes repetidos mais comparáveis. |
| 🧱 CPU spill / caminho misto | Uma situação em que parte do modelo ou carga de trabalho fica fora da memória GPU e utiliza recursos CPU, o que pode abrandar a inferência. |
| 🔧 nvidia_uvm | Um módulo de kernel NVIDIA relacionado com a gestão de memória GPU que por vezes precisa de ser recarregado durante a resolução de problemas. |
Por Que Vale a Pena Auto-Alojar um LLM

Se já fez a parte difícil — alugou o servidor GPU, instalou o Ubuntu, aprendeu a navegar pelo SSH e manteve os seus próprios serviços a funcionar — torna-se rapidamente frustrante quando uma IA alojada ainda controla o último troço. Pode recusar um pedido perfeitamente normal, enterrar a resposta sob avisos, alterar o estilo de resposta sem aviso, e manter cada prompt a fluir através da fronteira de outra pessoa. Para muitos utilizadores técnicos, essa é a verdadeira frustração: não apenas o que o modelo diz, mas quem controla a camada de serviço quando o diz.
Este guia trata de resolver isso com modelos abertos e locais, não com truques de contorno para APIs proprietárias. Irá auto-alojar o Ollama num servidor Ubuntu GPU, executar inferência localmente, verificar que o caminho GPU é real, e ver o que muda quando escolhe uma família de modelos diferente. Um equívoco a esclarecer desde cedo: auto-alojado não significa automaticamente irrestrito. Significa que controla muito mais da pilha — e deixa de depender de um caminho de serviço controlado pelo fornecedor — mas o modelo que executa pode ainda ter o seu próprio comportamento de alinhamento.
📝 Nota: Os comandos neste guia são validados com base na documentação atual do Ollama, mas os resultados de terminal mostrados abaixo são exemplos representativos em vez de capturas de benchmarks em tempo real. Utilize-os como padrão de sucesso, não como uma afirmação de desempenho.
No final, terá um serviço Ollama a funcionar no Ubuntu, uma API local verificada em 127.0.0.1:11434, prova de que a inferência suportada por GPU está realmente a acontecer, e uma comparação fundamentada entre um modelo alinhado mainstream e uma alternativa menos restrita. Este tutorial foi escrito para leitores confortáveis com SSH, Ubuntu, sudo e systemd, mas que não precisam de experiência prévia com Ollama.
O Servidor Ubuntu GPU Exato Utilizado para Este Guia

Esta demonstração está ancorada numa máquina Ubuntu real com uma única GPU, porque conselhos vagos de “deve funcionar na maioria dos servidores” é como os guias de auto-alojamento se tornam enganosos. A máquina de referência aqui é a classe real de host utilizada para este guia: o tipo de máquina que um indivíduo avançado, laboratório ou pequena equipa alugaria quando quer inferência local privada sem saltar diretamente para um rack de aceleradores empresariais. Ainda irá discutir o comportamento multi-GPU mais tarde, porque o Ollama muda quando um modelo ultrapassa uma placa, mas trate essa parte como contexto orientado para o futuro em vez de prova deste servidor exato.
Servidor GPU — Ryzen 9 3950X + RTX 4070 Ti Super
| Componente | Detalhes |
|---|---|
| CPU | AMD Ryzen 9 3950X (16 núcleos / 32 threads) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| Capacidade | Forte para modelos da classe 8B; modelos maiores tornam-se decisões de spill ou atualização |
Na prática, esta é uma configuração muito forte para modelos do dia a dia da classe 8B e ainda útil para trabalho local maior até ao ponto em que 16GB de VRAM se torna a verdadeira limitação. Um modelo como llama3.1:8b com aproximadamente 4.9GB cabe facilmente nesta placa. Um modelo como gpt-oss:20b com aproximadamente 14GB é o tipo de teste de topo de gama para uma única GPU que ainda faz sentido aqui. Um modelo como qwen3:30b com aproximadamente 19GB é melhor tratado como ponto de referência para o que muda num host maior ou de dual-GPU do que como um ajuste limpo para esta máquina exata.
Essa distinção importa porque o objetivo deste artigo não é espremer o maior número possível para uma manchete. É mostrar como é um servidor LLM auto-alojado sensato quando se quer privacidade, controlo local e memória GPU suficiente para executar modelos úteis sem compromisso constante. Esta classe de hardware é onde a inferência auto-alojada se torna realista, não teórica.
Também explica algumas escolhas que verá mais tarde: mistral é usado primeiro porque proporciona uma prova rápida e com pouco atrito de que a pilha funciona, enquanto a comparação de comportamento fica na classe 8B onde esta máquina está confortável. qwen3:30b ainda aparece mais tarde, mas como exemplo teórico do tipo de modelo que pode desencadear a colocação multi-GPU num host maior em vez de como prova em tempo real deste servidor. Com as expectativas definidas, o próximo passo é validar o host antes de o Ollama o tocar.
Execute Estas Verificações de Pré-Instalação Antes de Tocar no Ollama

Comece com nvidia-smi. Se este comando estiver ausente ou falhar, pare aí e corrija primeiro o driver NVIDIA. Não instale o Ollama ainda, porque uma pilha NVIDIA com problemas fará com que cada sintoma posterior pareça uma falha de aplicação quando na realidade é uma falha de plataforma.
Execute primeiro a verificação de GPU:
nvidia-smi
❗Se o Ubuntu indicar que o nvidia-smi está em falta, não assuma que o servidor não tem GPU. Um modo de falha comum em máquinas Ubuntu alugadas é que a placa está presente mas ainda ligada ao nouveau em vez do driver NVIDIA. Consulte primeiro a secção “Corrigir Problema de Driver Nvidia no Ubuntu“.
Um resultado saudável nesta classe de servidor deve ter um aspeto semelhante a este:
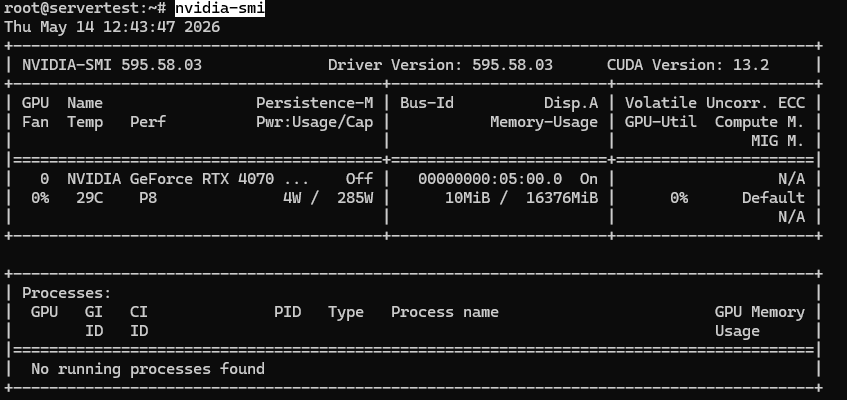
Depois de o nvidia-smi funcionar e a GPU estar visível, continue com as verificações abaixo.
O que pretende confirmar é simples: a GPU instalada está visível, reporta aproximadamente 16GB de VRAM neste host, e o driver está carregado de forma limpa. Se estiver num servidor multi-GPU, o mesmo comando deve listar cada placa.
nvidia-smi -L

❗ Importante: A documentação atual de suporte GPU do Ollama utiliza o driver NVIDIA 531+ como o piso real para inferência NVIDIA suportada. Trate o 531+ como o requisito para este guia, mesmo que tenha visto notas da comunidade mais antigas a citar versões mais baixas.
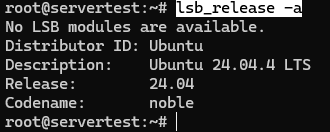
Agora confirme que o host é realmente o ambiente Ubuntu que este guia assume:
lsb_release -a
Por fim, verifique o espaço livre em disco antes de começar a descarregar modelos. A instalação em si é pequena; os modelos não são. Depois de avançar para além de testes pequenos, uma biblioteca de 20B-30B pode consumir dezenas de gigabytes rapidamente, por isso 100GB+ livres é a mentalidade certa antes de trabalho sério com modelos locais.
df -h /

Se estas verificações passarem, eliminou as principais incógnitas de infraestrutura: as GPUs estão presentes, a base do driver é sã, o Ubuntu está confirmado, e o disco tem espaço para descarregamentos reais de modelos. Esse é o ponto em que instalar o Ollama se torna um próximo passo limpo em vez de uma suposição.
Corrigir Problema de Driver Nvidia no Ubuntu
Siga os passos abaixo para corrigir problemas com o comando “nvidia-smi”.
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
Se essa saída mostrar uma placa NVIDIA e uma linha como Kernel driver in use: nouveau, instale o pacote de driver Ubuntu recomendado em vez de instalar apenas o nvidia-utils.
Instale o pacote ubuntu-drivers-common (necessário para a gestão de drivers) e os cabeçalhos do kernel para o seu kernel atualmente em execução.
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)Analise o seu sistema e liste os drivers proprietários disponíveis (por exemplo, drivers GPU NVIDIA) que podem ser instalados.
ubuntu-drivers devices
Em seguida, instale o pacote de driver recomendado. No nosso caso foi: nvidia-driver-595-open:
apt install -y nvidia-driver-595-open
rebootApós o reinício, execute novamente:
nvidia-smi
nvidia-smi -LInstalar o Ollama e Confirmar que o Serviço Está Saudável

O caminho Ubuntu suportado é o instalador oficial do Ollama, não um fluxo de tarball personalizado nem um desvio pelo Docker. Isso importa porque este guia trata de obter um serviço local fiável com padrões previsíveis, integração systemd e comportamento de propriedade sensato no Linux.
Execute o instalador exatamente como documentado:
curl -fsSL https://ollama.com/install.sh | sh
Num sistema saudável, o script instala o binário, cria o utilizador de serviço ollama, adiciona as associações de grupo corretas quando disponíveis, escreve a unidade systemd e inicia o serviço ligado a 127.0.0.1:11434.
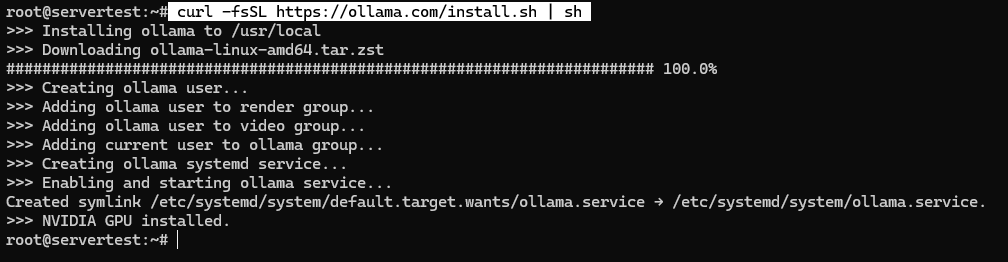
Depois de o script terminar, valide o serviço em vez de assumir sucesso:
sudo systemctl status ollama --no-pager
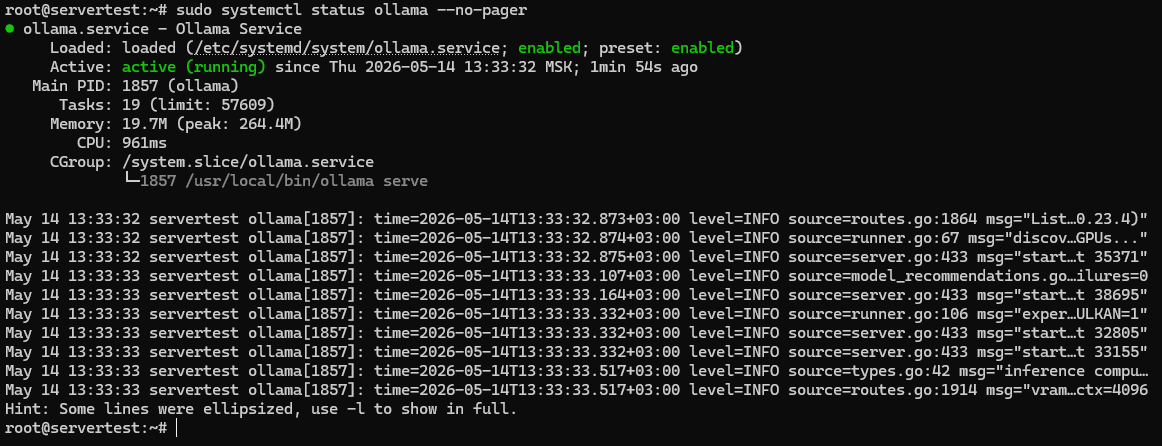
Está à procura de três coisas aqui: o ficheiro de unidade está presente, o serviço está ativado para arranque, e Active: active (running) confirma que o servidor está realmente em execução.
Primeiro, estabeleça a conta de utilizador de serviço Linux de forma concreta, e só depois pense em como e onde o armazenamento de modelos será gerido.
getent passwd ollama

Essa única linha explica muito do comportamento futuro. Os modelos no Linux residem sob a propriedade do serviço, e se os mover posteriormente para outro disco sem corrigir as permissões para o utilizador ollama, cria os seus próprios problemas.
Mais uma verificação fecha o ciclo no bind padrão:
ss -tlnp | grep 11434

⚠️ Aviso: O Ollama não requer autenticação na API local por padrão. Isso é aceitável quando está ligado a 127.0.0.1, mas não é seguro expor a porta 11434 diretamente à internet como se fosse um serviço público reforçado.
Se o serviço não arrancar de forma limpa, vá primeiro aos registos em vez de reinstalar às cegas:
journalctl -u ollama -n 100 --no-pager
Essa é a forma mais rápida de detetar problemas de permissões, erros de arranque, problemas de deteção de driver ou problemas de bind. Depois de o serviço estar saudável no localhost, a próxima coisa a compreender é como o comportamento de colocação de GPU funciona em tempo de execução.
Como o Ollama Utiliza Realmente Uma ou Múltiplas GPUs
Mesmo que o servidor utilizado para este guia tenha uma GPU, o comportamento multi-GPU ainda vale a pena compreender porque muitos utilizadores podem estar em máquinas maiores ou expandir mais tarde. Muita confusão com duas GPUs começa com a expectativa errada: “Tenho duas placas, por isso ambas devem estar ativas o tempo todo.” Não é assim que o Ollama funciona. A regra prática é muito mais simples: se um modelo cabe numa GPU, o Ollama normalmente mantê-lo-á numa GPU. Só se distribui por múltiplas GPUs quando o modelo não cabe confortavelmente numa única placa.
Utilize estas duas verificações em conjunto sempre que quiser ver o desempenho da GPU:
ollama ps
watch -n 1 nvidia-smi
ollama ps indica como o modelo carregado está a ser processado. 100% GPU significa que o modelo está totalmente residente na memória GPU. 100% CPU significa que a aceleração GPU não está a ser utilizada. Um estado misto indica que alguma parte da carga de trabalho ou residência saiu do caminho GPU. watch -n 1 nvidia-smi complementa isso mostrando o uso de VRAM em tempo real por placa enquanto o modelo está carregado.
A forma mais rápida de manter essas funções claras é esta:
| Comando | O que prova | O que não prova |
|---|---|---|
| ollama ps | Se o modelo está a ser executado em GPU, CPU ou num caminho misto | Qual placa ou placas exatas estão a suportar a carga |
| watch -n 1 nvidia-smi | Atividade de VRAM em tempo real por GPU | Se o uso dual-GPU significa automaticamente uma melhor escolha de modelo |
📝 Nota: CUDA_VISIBLE_DEVICES é um controlo de visibilidade, não um interruptor “usar ambas as GPUs”. Se alguma vez restringir o acesso à GPU, prefira os UUIDs do nvidia-smi -L em vez de IDs numéricos porque a ordem das GPUs pode variar entre ambientes e reinícios.
Execute o Seu Primeiro Modelo Local e Verifique a Inferência GPU
Neste ponto, não precisa de um modelo gigante para provar que o servidor funciona. Precisa de um sucesso rápido e honesto. mistral é um bom primeiro pull porque é pequeno, rápido de descarregar e fácil de carregar, mesmo que llama3.1:8b seja a referência de base posterior para comparação de comportamento.
Comece por fazer pull do modelo:
ollama pull mistral

Agora execute um prompt pequeno para que a máquina faça algo útil, não apenas administrativo. A resposta pode demorar alguns segundos.
ollama run mistral "In one sentence, explain why people self-host LLMs."

Para provar que esta é inferência suportada por GPU em vez de um fallback para CPU, verifique o estado de execução:
ollama ps

E para ver o que já está no disco, liste o inventário local:
ollama list

mistral é a prova inicial correta porque dá uma resposta rápida sem transformar a validação da configuração numa longa espera. Mais tarde, llama3.1:8b torna-se mais útil porque é uma referência de base alinhada mais forte para comparar o comportamento do modelo.
Por fim, verifique onde a instalação Linux está a armazenar modelos:
sudo du -sh /usr/share/ollama/.ollama/models

Esse caminho — /usr/share/ollama/.ollama/models — é o armazenamento padrão de modelos Linux documentado pelo Ollama.
Quando vir uma resposta bem-sucedida, 100% GPU no ollama ps, e o uso do disco a aumentar na localização esperada, tem a primeira prova significativa de que a pilha local funciona.
Prove que É um Servidor, Não Apenas um Wrapper CLI

Um prompt de linha de comandos é agradável, mas a razão para auto-alojar o Ollama não é apenas para conversar dentro de um terminal. É para executar um servidor de inferência local que outras ferramentas, scripts e aplicações podem chamar sem enviar prompts através da fronteira de API de outra pessoa. A prova mais rápida é um pedido HTTP limpo ao endpoint nativo do Ollama.
Envie um pedido de geração local com streaming desativado para que a primeira resposta seja fácil de inspecionar:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'Uma resposta bem-sucedida deve voltar como JSON e ter um aspeto semelhante a este:
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
A lista de verificação de sucesso é simples: o pedido HTTP funciona localmente, JSON válido é devolvido, done: true está presente, e a resposta do modelo está em response. Esse é o ponto em que o Ollama deixa de ser “um CLI que por acaso descarrega modelos” e se torna infraestrutura que pode realmente integrar em ferramentas locais e automação.
Se quiser compatibilidade com software que espera uma forma de pedido no estilo OpenAI, o Ollama também expõe endpoints /v1 localmente:
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 Nota: Esse rótulo “compatível com OpenAI” é fácil de interpretar mal. Não significa que está a falar com a OpenAI, e não muda o facto de o servidor ainda ser local. Significa apenas que a forma do pedido é familiar o suficiente para ferramentas e SDKs construídos em torno do padrão da API OpenAI. O URL base permanece http://localhost:11434/v1/, e qualquer chave API de substituição que algumas bibliotecas cliente insistam pode ser ignorada para uso local do Ollama.
De Onde Vêm Realmente as Restrições do Modelo

Esta é a parte que normalmente é simplificada numa única ideia vaga de “censura”, mas tecnicamente existem três camadas diferentes envolvidas: a camada de serviço do fornecedor, o alinhamento e ajuste de instruções do modelo, e o comportamento de prompt/execução que controla você mesmo. O auto-alojamento altera algumas dessas camadas dramaticamente. Não as apaga todas.
Uma forma simples de visualizar é esta:
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
Resultados:
– A camada de serviço controlada pelo fornecedor desaparece do caminho local
– A fronteira de rede e registo local torna-se sua
– O próprio treino e alinhamento do modelo ainda acompanha o modelo
Depois de separar as camadas, os passos de configuração anteriores tornam-se muito mais significativos:
| Camada | Controlada localmente após esta configuração? | Ponto de prova | O que ainda continua verdadeiro |
|---|---|---|---|
| Processo do servidor | Sim | ollama.service está a ser executado no Ubuntu | Agora controla o tempo de atividade, registos, atualizações e endereço de bind |
| Fronteira de rede | Sim | Verificação de bind 127.0.0.1:11434 | Os pedidos locais já não requerem um salto de moderação do fornecedor |
| Prompt de sistema / padrões de execução | Sim | Modelfile para mensagem de sistema controlada | Pode orientar o comportamento, mas não reescrever o treino |
| Camada de moderação do lado do fornecedor | Normalmente removida para inferência apenas local | Chamada à API local nativa tem sucesso no localhost | Esta é uma das maiores mudanças de controlo que o auto-alojamento lhe dá |
| Alinhamento do modelo nos pesos | Não, não automaticamente | Diferente ajuste do modelo dá resultados diferentes | Um modelo local pode ainda hesitar, recusar ou moralizar |
| Escolha da família de modelos | Sim | llama3.1:8b vs dolphin3 | Escolha o que melhor se adapta às suas necessidades |
Pode pensar nisso como uma produção teatral. O auto-alojamento muda o palco, a iluminação, os microfones e as notas do realizador. Não retreina o ator. Se um modelo foi ajustado para responder com cautela, hesitar frequentemente ou recusar certos tipos de enquadramento, executá-lo localmente não desfará magicamente esse treino.
O que a sua configuração atual já provou é mais restrito, mas ainda importante: controla o processo do servidor, controla a fronteira da API, e já não está a encaminhar prompts locais através de uma camada de moderação de propriedade do fornecedor. Essa é uma mudança real em privacidade e controlo. O que não provou é que cada modelo local se comportará da mesma forma ou que cada recusa no futuro foi causada por um fornecedor cloud.
É aqui que entra a escolha do modelo. Se quiser o efeito prático de menos avisos, respostas mais diretas ou comportamento menos propenso a recusas, não chega lá dizendo “auto-alojado” mais alto. Chega lá escolhendo uma família de modelos ou fine-tune diferente — e compreendendo as trocas que vêm com isso.
Escolher um Modelo Local Menos Restrito

Se quiser um teste justo, compare modelos que ocupam aproximadamente a mesma classe de tamanho. É por isso que este guia utiliza llama3.1:8b como referência de base alinhada mainstream e dolphin3 como modelo de comparação menos restrito. Ambos têm cerca de 4.9GB, o que torna a diferença de comportamento mais fácil de interpretar sem também alterar drasticamente a pegada de hardware.
Faça pull dos modelos de comparação localmente:
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistralAqui está o enquadramento prático para os três nomes que mais provavelmente verá nesta parte do ecossistema Ollama:
| Modelo | Tamanho aprox. | Papel neste artigo | Leitura prática |
|---|---|---|---|
| llama3.1:8b | 4.9GB | Referência de base alinhada mainstream | Boa referência padrão para comportamento “normal” de seguimento de instruções moderno |
| dolphin3 | 4.9GB | Comparação principal menos restrita | Pegada similar, normalmente mais direto, frequentemente menos preenchido |
| dolphin-mistral | 4.1GB | Alternativa mais antiga opcional | Ainda útil historicamente, mas não a melhor comparação atual para uso diário |
⚠️ Aviso: Um fine-tune diferente não é “o mesmo modelo com censura removida.” Pode alterar a diretividade, a densidade de avisos e a disposição para seguir o enquadramento do utilizador, mas também pode alterar o tom, a factualidade, a consistência e a personalidade geral.
Desempenho GPU
Antes de executar os modelos desejados, é essencial compreender primeiro as possibilidades e limitações do hardware envolvido. Assim, há duas coisas a testar conceptualmente: primeiro, como é o comportamento limpo de GPU única no hardware real utilizado para este guia; segundo, o que muda se posteriormente executar a mesma pilha num host dual-GPU. Ambas importam, mas apenas a primeira é uma prova em tempo real desta máquina exata.
Neste servidor, o melhor teste de execução de topo de gama é gpt-oss:20b. É suficientemente grande para ser interessante enquanto ainda faz sentido numa placa de 16GB.
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
Depois de o modelo carregar, confirme o estado de execução:
ollama ps

Essa é a prova prática que pretende nesta máquina. Mostra que os modelos mais pequenos cabem facilmente e que um modelo local maior mas ainda realista pode empurrar uma placa de 16GB perto do seu envelope utilizável sem precisar de múltiplas GPUs.
Se posteriormente executar o Ollama num host de duas GPUs, um modelo como qwen3:30b torna-se o tipo de carga de trabalho que pode demonstrar a colocação multi-GPU. O fluxo de trabalho é o mesmo — observe o nvidia-smi, execute o modelo, inspecione o ollama ps — mas o objetivo não é fazer as duas placas acenderem por si só. O objetivo é confirmar que o Ollama só distribui um modelo por múltiplas GPUs quando o modelo já não cabe de forma limpa numa.
Considerações sobre Contorno de Censura

Para comparação de comportamento, mantenha as condições controladas para estar a testar o modelo mais do que a aleatoriedade. Utilize o mesmo endpoint, o mesmo prompt, stream: false, uma temperatura baixa e um seed fixo:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'Em seguida, repita o mesmo pedido com “model”: “dolphin3”. O seed fixo não elimina toda a variância, mas reduz aleatoriedade suficiente para tornar as diferenças de tom e conformidade mais fáceis de ver.
- Um primeiro prompt seguro é: “O auto-alojamento de um LLM significa que o utilizador controla totalmente o comportamento do modelo? Responda em 4 pontos. Seja direto e omita preâmbulos.” Uma resposta representativa do llama3.1:8b tende a soar assim:
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.Uma resposta representativa do dolphin3 ao mesmo prompt soa frequentemente mais condensada:
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - Um segundo prompt útil é: “Escreva um caso conciso em cinco frases sobre por que uma equipa sensível à privacidade pode rejeitar a IA gerida pelo fornecedor. Sem introdução nem conclusão.” O llama3.1:8b normalmente cumpre, mas num tom empresarial mais moderado. O dolphin3 segue mais prontamente a nitidez solicitada. Esse é o tipo de diferença que está a procurar aqui: não resultados dramáticos sem lei, mas mudanças em diretividade, enquadramento e densidade de avisos.
- A terceira categoria de prompts para validação pode ser a seguinte: pedir cinco razões factuais pelas quais um escritor pode preferir um modelo local para trabalho criativo incomum, de nicho ou não mainstream. Na prática, ambos os modelos respondem, mas o dolphin3 tende a manter-se mais próximo do tom não moralizador solicitado e de respostas diretas.
O padrão parece este:
| Tipo de prompt | Comportamento de base do llama3.1:8b | Comportamento do dolphin3 | Conclusão prática |
|---|---|---|---|
| Diretividade vs hesitação | Mais cauteloso, ligeiramente mais explicativo | Mais comprimido e direto | Mesmos factos, estilo de recusa/aviso diferente |
| Conformidade com tom mais assertivo | Frequentemente responde, mas suaviza a retórica | Mais disposto a seguir a assertividade solicitada | A obediência ao enquadramento faz parte da escolha do modelo |
| Enquadramento criativo de nicho | Factual, por vezes preenchido | Factual, normalmente menos moralizador | “Menos restrito” manifesta-se frequentemente como tom, não como capacidade pura |
E assim, aqui estão as conclusões honestas:
- A escolha de modelo local altera significativamente o comportamento de saída.
- Diferentes modelos variam em diretividade e densidade de avisos.
- O auto-alojamento remove uma camada de serviço controlada pelo fornecedor.
Agora Controla a Pilha, Não Apenas o Prompt

A frustração do início deste guia nunca foi apenas sobre um modelo recusar um pedido. Era sobre o facto de a camada de serviço, a camada de política e a fronteira de privacidade residirem noutro lugar. Após esta configuração, essa parte mudou. O seu servidor de inferência corre na sua máquina Ubuntu, a fronteira da API local é sua, o menu de modelos é seu, e os seus padrões de prompt/execução são seus para ajustar.
O que ainda requer julgamento é a parte que nenhum instalador pode resolver por si: escolher modelos que se adequem ao seu caso de uso, orientá-los com padrões sensatos, e expor o acesso de forma segura se avançar para além do localhost. Essa é a forma real do controlo de auto-alojamento. Não liberdade mágica de toda e qualquer restrição, mas propriedade da pilha que decide como, onde e com que modelo a inferência acontece. Se quiser o melhor próximo passo, comece por criar um Modelfile personalizado — ou colocar acesso remoto seguro à frente da API local quando estiver pronto.
O Que Fazer Após a Configuração Base

Neste ponto, a promessa central está cumprida. O servidor funciona, a API funciona, o caminho GPU é real, e as diferenças de comportamento do modelo já não são abstratas. O próximo passo não é “instalar mais coisas às cegas.” É ajustar as partes da pilha que agora lhe pertencem.
Personalizar o Comportamento do Modelo com um Modelfile
Um Modelfile é a forma mais limpa de alterar os padrões de prompt local sem tocar nos pesos do modelo. Comece por inspecionar a definição atual do modelo para perceber o que está a estender:
ollama show --modelfile dolphin3
Em seguida, crie uma variação local simples:
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192Construa-a como um novo nome de modelo e teste-a:
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ Importante: Um Modelfile altera o comportamento de prompt e execução, não o histórico de treino do modelo. Pode orientar o tom e os padrões, mas não retreina o modelo subjacente.
Proteger a Configuração
O bind ao localhost é um bom padrão, mas não é o fim da história de segurança. Verifique novamente o endereço de escuta atual:
ss -tlnp | grep 11434
Se o objetivo é manter o Ollama apenas local, fixe esse comportamento explicitamente com uma substituição systemd:
sudo systemctl edit ollama
Adicione o seguinte:
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
Em seguida, recarregue e reinicie o serviço:
sudo systemctl daemon-reload
sudo systemctl restart ollamaSe precisar de acesso remoto mais tarde, não publique o 11434 diretamente. Em vez disso, coloque um proxy inverso com TLS e autenticação à frente:
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ Aviso: Trate a exposição pública como um projeto de reforço separado. O Ollama por si só é um servidor de inferência local, não um gateway de API público pronto para produção com autenticação integrada, limitação de taxa e padrões voltados para a internet.
Modelos Recomendados para Este Hardware
Depois de a instalação base funcionar, a melhoria de maior valor é escolher modelos que se adequem bem a esta máquina em vez de perseguir o maior destaque. Para o servidor single-4070 Ti SUPER utilizado aqui, o menu prático parece este:
| Caso de uso | Modelo | Tamanho | Colocação esperada | Por que se adequa a esta máquina |
|---|---|---|---|---|
| Primeiro sucesso | mistral | 4.4GB | GPU única | Validação rápida, simples e com pouco atrito |
| Referência geral | llama3.1:8b | 4.9GB | GPU única | Forte ponto de referência mainstream |
| 8B menos restrito | dolphin3 | 4.9GB | GPU única | Melhor comparação equivalente com llama3.1:8b |
| Nível de raciocínio | gpt-oss:20b | 14GB | Normalmente GPU única | Raciocínio mais forte enquanto ainda cabe de forma limpa |
| Nível local de maior qualidade | qwen3:30b | 19GB | Necessita dual-GPU ou VRAM maior | Melhor como alvo de atualização futura do que como ajuste limpo para esta máquina exata |
| Nível focado em código | deepseek-coder:33b | 19GB | Necessita dual-GPU ou VRAM maior | Opção forte se avançar para uma máquina maior ou adicionar uma segunda GPU mais tarde |
| Apenas experimental | llama3.1:70b | 43GB | CPU spill severo / muito mais lento / trocas de contexto reduzido | Não é um alvo realista para este host a menos que aceite compromisso pesado |
Arranque Automático e Manutenção
Depois da parte divertida vem a parte que mantém um servidor LLM local utilizável um mês depois. Confirme o comportamento no arranque, mantenha o serviço atualizado, observe os registos e saiba como descarregar modelos grandes quando precisar da VRAM de volta.
sudo systemctl is-enabled ollama
sudo systemctl enable --now ollama
curl -fsSL https://ollama.com/install.sh | sh
journalctl -u ollama -n 100 --no-pager
Para operações diárias de modelos, estes são os comandos que utilizará com mais frequência:
ollama list
ollama ps
ollama stop gpt-oss:20b
sudo du -sh /usr/share/ollama/.ollama/modelsE se o armazenamento de modelos tiver de ser movido para um disco maior, prepare o diretório para o utilizador de serviço antes de redirecionar o Ollama:
sudo mkdir -p /mnt/ai/ollama-models
sudo chown -R ollama:ollama /mnt/ai/ollama-modelsEm seguida, defina OLLAMA_MODELS através do systemctl edit ollama. Esse detalhe de propriedade é o que impede que uma migração de armazenamento se torne num problema de permissões.
Referência de Resolução de Problemas
Quando algo se avaria, o caminho mais rápido é normalmente fazer corresponder o sintoma à camada certa em vez de tentar ciclos aleatórios de reinstalação. Utilize esta tabela como primeira abordagem:
| Sintoma | Causa provável | Verificação | Correção |
|---|---|---|---|
| Falha do nvidia-smi | Problema de driver ou pilha GPU | nvidia-smi, lspci -nnk | grep -A3 -Ei ‘VGA|3D|NVIDIA’, ubuntu-drivers devices | Corrija primeiro a camada NVIDIA; se o Ubuntu estiver a usar nouveau, instale o driver NVIDIA recomendado, reinicie e execute novamente o nvidia-smi |
| O ollama.service não arranca | Problema de serviço, permissão ou bind | systemctl status ollama, journalctl -u ollama -n 100 –no-pager | Resolva o erro do serviço antes de fazer pull de modelos |
| O modelo corre em CPU | Falha na deteção de GPU ou ocorreu fallback | ollama ps, registos | Reinicie o serviço; se necessário recarregue o nvidia_uvm |
| Apenas uma GPU está ativa | O modelo cabe numa placa | watch -n 1 nvidia-smi | Isto é normal; num host multi-GPU, teste com um modelo que exceda o envelope de VRAM de uma placa se quiser observar a colocação multi-GPU |
| A porta 11434 está exposta em 0.0.0.0 | Endereço de bind alterado | ss -tlnp | grep 11434 | Defina OLLAMA_HOST=127.0.0.1:11434 e reinicie |
| Erros de caminho de modelo após mover o armazenamento | Propriedade incorreta no diretório de modelos | ls -ld <model-dir> | sudo chown -R ollama:ollama <model-dir> |
| GPU desaparece após suspensão/retoma | Problema NVIDIA UVM | registos e verificações de GPU | Recarregue o nvidia_uvm e reinicie o serviço se necessário |
Se apenas se lembrar de uma regra operacional desta secção, que seja esta: trate o Ollama como um serviço real, não como uma utilidade CLI descartável. Registos, propriedade, endereços de bind e caminhos de armazenamento importam tanto quanto a janela de prompt.


