 Polski
Polski English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 na wszystkich usługach hostingowych
na wszystkich usługach hostingowychHostuj Ollama samodzielnie na serwerze LLM i przejmij kontrolę nad cenzurą AI
Słowa kluczowe
Przed przystąpieniem do konfiguracji, poniżej przedstawiono terminy, które najprawdopodobniej mogą wprowadzić w błąd czytelników tego przewodnika. Ten krótki słowniczek od samego początku wyjaśnia terminologię związaną z Linux, GPU i modelami lokalnymi.
| Słowo kluczowe | Krótkie wyjaśnienie |
|---|---|
| 🤖 LLM | Large Language Model; model AI generujący tekst na podstawie podpowiedzi. |
| 🦙 Ollama | Lokalny program uruchamiający i serwer do pobierania, serwowania i wywoływania LLM na własnej maszynie. |
| 🖥️ GPU | Procesor graficzny używany tutaj do przyspieszania inferencji modelu. |
| 💾 VRAM | Pamięć GPU; jest jednym z głównych ograniczeń dotyczących tego, jak duży model może zmieścić się na karcie. |
| ⚡ Inferencja | Czynność uruchamiania modelu w celu wygenerowania odpowiedzi. |
| 🔄 systemd | Menedżer usług Linux używany do uruchamiania, zatrzymywania, restartowania i włączania usług takich jak Ollama. |
| 🧩 Sterownik NVIDIA | Warstwa oprogramowania umożliwiająca Ubuntu prawidłową komunikację z GPU NVIDIA dla obciążeń obliczeniowych. |
| 🚫 nouveau | Otwartoźródłowy sterownik graficzny Linux, który może uniemożliwiać prawidłową konfigurację obliczeń NVIDIA, jeśli jest używany zamiast oficjalnego sterownika NVIDIA. |
| 📊 nvidia-smi | Narzędzie wiersza poleceń NVIDIA do sprawdzania widoczności GPU, użycia VRAM i stanu sterownika. |
| 🔌 Endpoint API | URL, który narzędzia lub skrypty wywołują w celu wysyłania podpowiedzi do Ollama i odbierania odpowiedzi. |
| ☁️ Warstwa serwująca kontrolowana przez dostawcę | Zarządzana przez dostawcę warstwa API, która może dodawać moderację, logowanie, egzekwowanie polityki lub inne kontrole przed odpowiedzią modelu. |
| 🧬 Dostrajanie (Fine-tune) | Zmodyfikowana wersja modelu bazowego dostrojona pod kątem innego tonu, zachowania lub zadań specjalnego przeznaczenia. |
| ⚖️ Wagi modelu (Model weights) | Wyuczone parametry wewnętrzne modelu; samodzielne hostowanie nie zmienia ich automatycznie. |
| 📝 Modelfile | Plik Ollama używany do tworzenia niestandardowego lokalnego wariantu modelu z własnym promptem systemowym i parametrami środowiska uruchomieniowego. |
| 🪪 UUID | Stabilny identyfikator sprzętowy GPU; często jest bezpieczniejszy niż numeryczne identyfikatory GPU, ponieważ kolejność urządzeń może się zmieniać. |
| 🔒 TLS | Szyfrowanie używane przez HTTPS i odwrotne proxy w celu zabezpieczenia ruchu między klientami a serwerem. |
| 🌐 Odwrotne proxy (Reverse proxy) | Usługa frontendowa, która może dodawać TLS, uwierzytelnianie i kontrolowany dostęp publiczny przed przekazywaniem żądań do Ollama. |
| 🎛️ Temperatura / ziarno (Temperature / seed) | Ustawienia generowania; temperatura wpływa na losowość, podczas gdy stałe ziarno pomaga uczynić powtarzane testy bardziej porównywalnymi. |
| 🧱 Przelew CPU / ścieżka mieszana (CPU spill / mixed path) | Sytuacja, w której część modelu lub obciążenia wykracza poza pamięć GPU i używa zasobów CPU, co może spowalniać inferencję. |
| 🔧 nvidia_uvm | Moduł jądra NVIDIA związany z zarządzaniem pamięcią GPU, który czasami wymaga ponownego załadowania podczas rozwiązywania problemów. |
Dlaczego warto samodzielnie hostować LLM

Jeśli wykonałeś już najtrudniejszą część — wynająłeś serwer GPU, zainstalowałeś Ubuntu, nauczyłeś się poruszać po SSH i utrzymujesz własne usługi — szybko staje się to frustrujące, gdy hostowane AI nadal kontroluje ostatni odcinek drogi. Może odmówić wykonania zupełnie zwykłego żądania, zakopać odpowiedź pod zastrzeżeniami, zmienić styl odpowiedzi bez ostrzeżenia i sprawić, że każdy prompt przepływa przez czyjąś granicę. Dla wielu technicznych użytkowników to jest prawdziwa frustracja: nie tylko to, co model mówi, ale kto kontroluje warstwę serwującą, gdy to robi.
Ten przewodnik dotyczy naprawienia tego za pomocą otwartych i lokalnych modeli, a nie sztuczek obejścia zastrzeżonych API. Samodzielnie zainstalujesz Ollama na serwerze Ubuntu z GPU, uruchomisz inferencję lokalnie, zweryfikujesz, że ścieżka GPU jest prawdziwa, i zobaczysz, co się zmienia, gdy wybierzesz inną rodzinę modeli. Jedno nieporozumienie do wyjaśnienia na początku: samodzielne hostowanie nie oznacza automatycznie braku ograniczeń. Oznacza, że kontrolujesz znacznie więcej warstw stosu — i przestajesz polegać na ścieżce serwowania kontrolowanej przez dostawcę — ale model, który uruchamiasz, może nadal mieć własne zachowanie wynikające z dopasowania.
📝 Uwaga: Polecenia w tym przewodniku zostały zweryfikowane zgodnie z aktualną dokumentacją Ollama, jednak pokazane poniżej wyniki terminala są przykładami reprezentatywnymi, a nie rzeczywistymi przechwyceniami benchmarków. Używaj ich jako wzorca sukcesu, a nie jako twierdzenia o wydajności.
Po zakończeniu będziesz mieć działającą usługę Ollama na Ubuntu, zweryfikowane lokalne API pod adresem 127.0.0.1:11434, dowód na to, że inferencja wspierana przez GPU rzeczywiście działa, oraz ugruntowane porównanie między głównym dopasowanym modelem a mniej restrykcyjną alternatywą. Ten samouczek jest napisany dla czytelników, którzy czują się komfortowo z SSH, Ubuntu, sudo i systemd, ale nie potrzebują wcześniejszego doświadczenia z Ollama.
Dokładny serwer Ubuntu z GPU użyty w tym przewodniku

Ten przewodnik jest zakotwiczony w prawdziwej maszynie Ubuntu z jednym GPU, ponieważ niejasne porady “powinno działać na większości serwerów” sprawiają, że przewodniki dotyczące samodzielnego hostowania stają się mylące. Serwer referencyjny to rzeczywista klasa hosta użyta w tym przewodniku: rodzaj maszyny, którą zaawansowany użytkownik, laboratorium lub mały zespół faktycznie wynajmuje, gdy chce prywatnej lokalnej inferencji bez przeskakiwania od razu do szafy pełnej akceleratorów korporacyjnych. W dalszej części omówione zostanie zachowanie wieloGPU, ponieważ Ollama zmienia się, gdy model przerasza jedną kartę, ale traktuj tę część jako kontekst zorientowany na przyszłość, a nie jako dowód z tego konkretnego serwera.
Serwer GPU — Ryzen 9 3950X + RTX 4070 Ti Super
| Komponent | Szczegóły |
|---|---|
| CPU | AMD Ryzen 9 3950X (16 rdzeni / 32 wątki) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| Możliwości | Mocny dla modeli klasy 8B; większe modele stają się decyzjami dotyczącymi przelewu lub aktualizacji |
W praktyce jest to bardzo mocna konfiguracja dla codziennych modeli klasy 8B, a także przydatna do większej lokalnej pracy aż do punktu, w którym 16GB VRAM staje się prawdziwym ograniczeniem. Model taki jak llama3.1:8b o rozmiarze około 4,9GB łatwo mieści się na tej karcie. Model taki jak gpt-oss:20b o rozmiarze około 14GB to rodzaj testu na jednym GPU na wysokim końcu, który nadal ma sens w tym przypadku. Model taki jak qwen3:30b o rozmiarze około 19GB lepiej traktować jako punkt odniesienia dla tego, co zmienia się na większym lub dwuGPU hoście, niż jako czysty wybór dla tej konkretnej maszyny.
To rozróżnienie ma znaczenie, ponieważ celem tego artykułu nie jest wciśnięcie jak największej liczby do nagłówka. Chodzi o pokazanie, jak wygląda sensowny samodzielnie hostowany serwer LLM, gdy chcesz prywatności, lokalnej kontroli i wystarczającej ilości pamięci GPU do uruchamiania użytecznych modeli bez ciągłych kompromisów. Ta klasa sprzętu to miejsce, gdzie samodzielnie hostowana inferencja staje się realistyczna, a nie teoretyczna.
Wyjaśnia to również kilka wyborów, które zobaczysz później: mistral jest używany jako pierwszy, ponieważ zapewnia szybki, bezproblemowy dowód działania stosu, podczas gdy porównanie zachowań pozostaje w klasie 8B, gdzie ta maszyna czuje się komfortowo. qwen3:30b pojawia się później, ale jako teoretyczny przykład rodzaju modelu, który może wyzwolić wieloGPU umieszczanie na większym hoście, a nie jako żywy dowód z tego serwera. Po ustaleniu oczekiwań, następnym krokiem jest walidacja hosta przed uruchomieniem Ollama.
Uruchom te kontrole przed instalacją zanim dotkniesz Ollama

Zacznij od nvidia-smi. Jeśli to polecenie jest niedostępne lub kończy się niepowodzeniem, zatrzymaj się i najpierw napraw sterownik NVIDIA. Nie instaluj jeszcze Ollama, ponieważ uszkodzony stos NVIDIA sprawi, że każdy późniejszy objaw będzie wyglądał jak awaria aplikacji, gdy w rzeczywistości jest to awaria platformy.
Najpierw uruchom sprawdzenie GPU:
nvidia-smi
❗Jeśli Ubuntu mówi, że nvidia-smi jest niedostępne, nie zakładaj, że serwer nie ma GPU. Częstym trybem awarii na wynajmowanych maszynach Ubuntu jest to, że karta jest obecna, ale nadal powiązana z nouveau zamiast ze sterownikiem NVIDIA. Najpierw sprawdź sekcję “Napraw problem ze sterownikiem Nvidia na Ubuntu“.
Prawidłowy wynik dla tej klasy serwera powinien wyglądać mniej więcej tak:
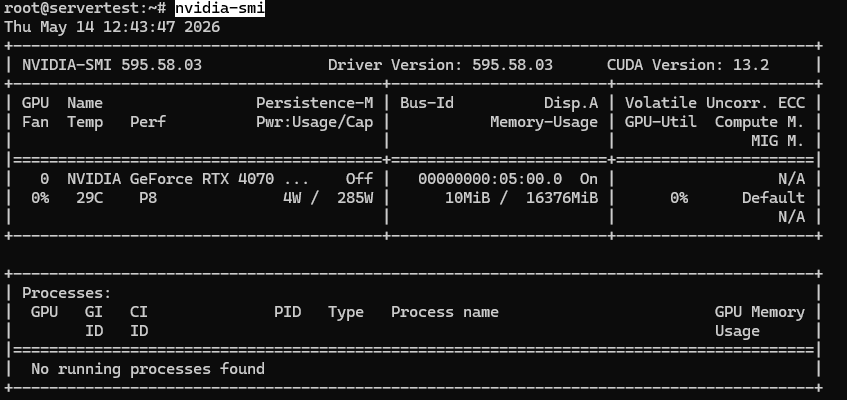
Gdy nvidia-smi działa i GPU jest widoczny, kontynuuj poniższe sprawdzenia.
To, co chcesz potwierdzić, jest proste: zainstalowany GPU jest widoczny, raportuje około 16GB VRAM na tym hoście, a sterownik jest załadowany czysto. Jeśli jesteś na serwerze wieloGPU, to samo polecenie powinno wylistować każdą kartę.
nvidia-smi -L

❗ Ważne: Aktualna dokumentacja wsparcia GPU Ollama używa sterownika NVIDIA 531+ jako rzeczywistego dolnego progu dla obsługiwanej inferencji NVIDIA. Traktuj 531+ jako wymaganie dla tego przewodnika, nawet jeśli widziałeś starsze notatki społeczności podające niższe wersje.
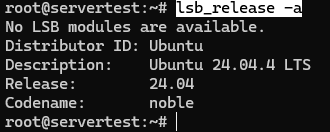
Teraz potwierdź, że host jest rzeczywiście środowiskiem Ubuntu zakładanym przez ten przewodnik:
lsb_release -a
Na koniec sprawdź wolne miejsce na dysku przed rozpoczęciem pobierania modeli. Sam instalator jest mały; modele nie są. Gdy wyjdziesz poza małe testy, biblioteka 20B-30B może szybko pochłonąć dziesiątki gigabajtów, więc 100GB+ wolnego miejsca to właściwe nastawienie przed poważną lokalną pracą z modelami.
df -h /

Jeśli te sprawdzenia zakończą się pomyślnie, wyeliminowałeś główne niewiadome infrastrukturalne: GPU są obecne, poziom sterownika jest sensowny, Ubuntu jest potwierdzony, a dysk ma miejsce na prawdziwe pobieranie modeli. To jest punkt, w którym instalacja Ollama staje się czystym następnym krokiem zamiast zgadywania.
Napraw problem ze sterownikiem Nvidia na Ubuntu
Wykonaj poniższe kroki, aby naprawić problemy z poleceniem “nvidia-smi”.
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
Jeśli ten wynik pokazuje kartę NVIDIA i linię taką jak Kernel driver in use: nouveau, zainstaluj zalecany pakiet sterownika Ubuntu zamiast instalować tylko nvidia-utils.
Zainstaluj pakiet ubuntu-drivers-common (potrzebny do zarządzania sterownikami) i nagłówki jądra dla aktualnie działającego jądra.
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)Przeskanuj system i wylistuj dostępne zastrzeżone sterowniki (np. sterowniki GPU NVIDIA), które można zainstalować.
ubuntu-drivers devices
Następnie zainstaluj zalecany pakiet sterownika. W naszym przypadku był to: nvidia-driver-595-open:
apt install -y nvidia-driver-595-open
rebootPo ponownym uruchomieniu uruchom ponownie:
nvidia-smi
nvidia-smi -LZainstaluj Ollama i potwierdź, że usługa działa prawidłowo

Obsługiwaną ścieżką dla Ubuntu jest oficjalny instalator Ollama, a nie niestandardowy przepływ tarball i nie objazd przez Docker. Ma to znaczenie, ponieważ ten przewodnik dotyczy uzyskania niezawodnej lokalnej usługi z przewidywalnymi ustawieniami domyślnymi, integracją systemd i sensownym zachowaniem własności na Linux.
Uruchom instalator dokładnie tak, jak udokumentowano:
curl -fsSL https://ollama.com/install.sh | sh
Na zdrowym systemie skrypt instaluje plik binarny, tworzy użytkownika usługi ollama, dodaje odpowiednie członkostwa w grupach gdy są dostępne, zapisuje jednostkę systemd i uruchamia usługę powiązaną z 127.0.0.1:11434.
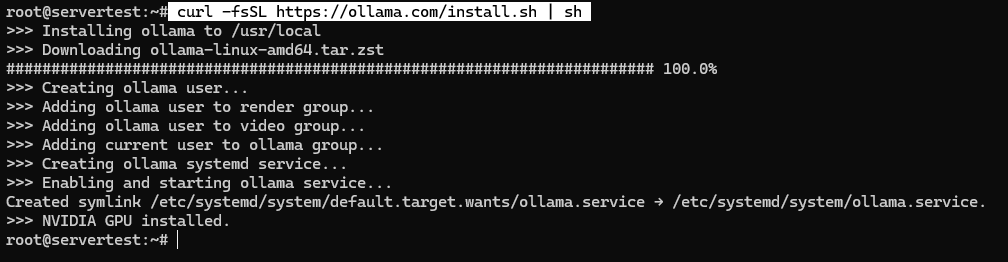
Po zakończeniu działania skryptu zweryfikuj usługę zamiast zakładać sukces:
sudo systemctl status ollama --no-pager
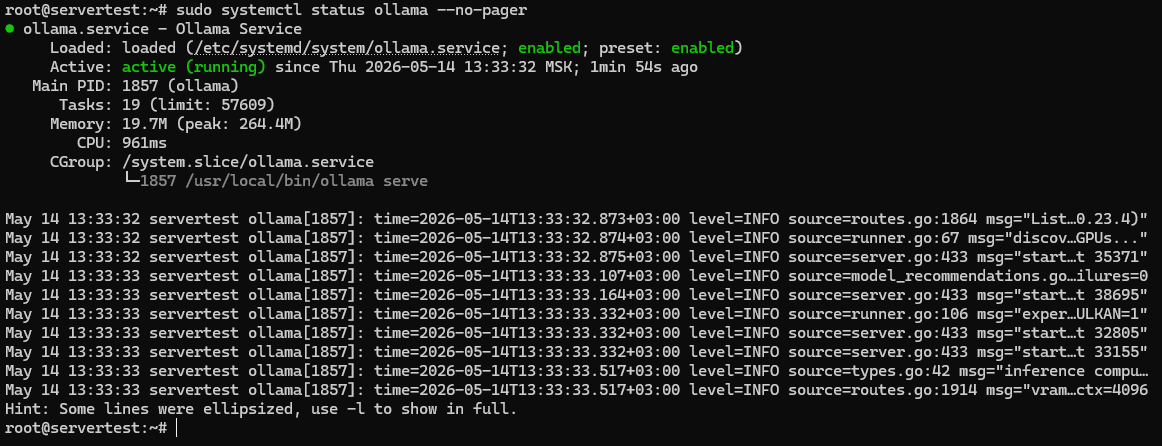
Szukasz tutaj trzech rzeczy: plik jednostki jest obecny, usługa jest włączona przy starcie systemu, a Active: active (running) potwierdza, że serwer faktycznie działa.
Najpierw ustal konto użytkownika usługi Linux w konkretny sposób, a dopiero potem pomyśl o tym, jak i gdzie będzie obsługiwane przechowywanie modeli.
getent passwd ollama

Ta pojedyncza linia wyjaśnia wiele przyszłych zachowań. Modele na Linux żyją pod własnością usługi, a jeśli później przeniesiesz je na inny dysk bez naprawienia uprawnień dla użytkownika ollama, stworzysz własne problemy.
Jeszcze jedno sprawdzenie zamyka pętlę dotyczącą domyślnego powiązania:
ss -tlnp | grep 11434

⚠️ Ostrzeżenie: Ollama domyślnie nie wymaga uwierzytelniania w lokalnym API. Jest to w porządku, gdy jest powiązane z 127.0.0.1, ale nie jest bezpieczne wystawianie portu 11434 bezpośrednio do internetu, jakby była to zahartowana usługa publiczna.
Jeśli usługa nie uruchomi się czysto, najpierw zajrzyj do logów zamiast ślepo ponownie instalować:
journalctl -u ollama -n 100 --no-pager
To najszybszy sposób na wykrycie problemów z uprawnieniami, błędów uruchamiania, problemów z wykrywaniem sterowników lub problemów z powiązaniem. Gdy usługa działa prawidłowo na localhost, następną rzeczą do zrozumienia jest to, jak zachowuje się umieszczanie GPU w czasie działania.
Jak Ollama faktycznie używa jednego lub wielu GPU
Mimo że serwer używany w tym przewodniku ma jeden GPU, zachowanie wieloGPU nadal warto rozumieć, ponieważ wielu użytkowników może korzystać z większych maszyn lub może je później rozbudować. Wiele nieporozumień dotyczących dwóch GPU zaczyna się od błędnego oczekiwania: “Mam dwie karty, więc obie powinny być cały czas aktywne.” Tak nie działa Ollama. Praktyczna zasada jest o wiele prostsza: jeśli model mieści się na jednym GPU, Ollama zazwyczaj będzie go trzymać na jednym GPU. Rozprzestrzenia się na wiele GPU tylko wtedy, gdy model nie mieści się wygodnie na jednej karcie.
Używaj tych dwóch sprawdzeń razem, gdy chcesz zobaczyć wydajność GPU:
ollama ps
watch -n 1 nvidia-smi
ollama ps mówi ci, jak jest przetwarzany załadowany model. 100% GPU oznacza, że model jest w pełni rezydentny w pamięci GPU. 100% CPU oznacza, że akceleracja GPU nie jest używana. Stan mieszany mówi ci, że część obciążenia lub rezydencji wylała się poza ścieżkę GPU. watch -n 1 nvidia-smi uzupełnia to, pokazując na żywo użycie VRAM na kartę podczas ładowania modelu.
Najszybszy sposób na utrzymanie tych ról w porządku to:
| Polecenie | Co udowadnia | Czego nie udowadnia |
|---|---|---|
| ollama ps | Czy model działa na GPU, CPU czy ścieżce mieszanej | Która dokładnie karta lub karty niosą obciążenie |
| watch -n 1 nvidia-smi | Aktywność VRAM w czasie rzeczywistym na GPU | Czy użycie dwóch GPU automatycznie oznacza lepszy wybór modelu |
📝 Uwaga: CUDA_VISIBLE_DEVICES to kontrola widoczności, a nie przełącznik “używaj obu GPU”. Jeśli kiedykolwiek ograniczysz dostęp do GPU, preferuj UUID z nvidia-smi -L zamiast numerycznych identyfikatorów, ponieważ kolejność GPU może się różnić między środowiskami i ponownymi uruchomieniami.
Uruchom swój pierwszy lokalny model i zweryfikuj inferencję GPU
W tym momencie nie potrzebujesz gigantycznego modelu, aby udowodnić, że serwer działa. Potrzebujesz szybkiego, uczciwego sukcesu. mistral jest dobrym pierwszym wyborem do pobrania, ponieważ jest mały, szybki do pobrania i łatwy do załadowania, mimo że llama3.1:8b będzie późniejszym punktem odniesienia do porównania zachowań.
Zacznij od pobrania modelu:
ollama pull mistral

Teraz uruchom przez niego mały prompt, żeby maszyna zrobiła coś użytecznego, a nie tylko administracyjnego. Odpowiedź może zająć kilka sekund.
ollama run mistral "In one sentence, explain why people self-host LLMs."

Aby udowodnić, że jest to inferencja wspierana przez GPU, a nie powrót do CPU, sprawdź stan środowiska uruchomieniowego:
ollama ps

A żeby zobaczyć, co jest już na dysku, wylistuj lokalny inwentarz:
ollama list

mistral jest właściwym pierwszym dowodem, ponieważ daje szybką odpowiedź bez zamieniania walidacji konfiguracji w długie oczekiwanie. Później llama3.1:8b staje się bardziej użyteczny, ponieważ jest mocniejszym dopasowanym punktem odniesienia do porównania zachowań modeli.
Na koniec sprawdź, gdzie instalacja Linux przechowuje modele:
sudo du -sh /usr/share/ollama/.ollama/models

Ta ścieżka — /usr/share/ollama/.ollama/models — to standardowe magazyn modeli Linux udokumentowany przez Ollama.
Gdy zobaczysz pomyślną odpowiedź, 100% GPU w ollama ps i rosnące użycie dysku w oczekiwanej lokalizacji, masz pierwszy znaczący dowód na działanie lokalnego stosu.
Udowodnij, że to serwer, a nie tylko opakowanie CLI

Prompt wiersza poleceń jest miły, ale powodem samodzielnego hostowania Ollama nie jest tylko rozmowa w terminalu. Chodzi o uruchomienie lokalnego serwera inferencji, który inne narzędzia, skrypty i aplikacje mogą wywoływać bez wysyłania promptów przez granicę API kogoś innego. Najszybszym dowodem jest jedno czyste żądanie HTTP do natywnego endpointu Ollama.
Wyślij lokalne żądanie generowania z wyłączonym strumieniowaniem, aby pierwsza odpowiedź była łatwa do sprawdzenia:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'Pomyślna odpowiedź powinna wrócić jako JSON i wyglądać mniej więcej tak:
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
Lista kontrolna sukcesu jest prosta: żądanie HTTP działa lokalnie, wraca prawidłowy JSON, obecne jest done: true, a odpowiedź modelu jest w response. To jest punkt, w którym Ollama przestaje być “CLI, które przypadkowo pobiera modele” i staje się infrastrukturą, którą możesz faktycznie zintegrować z lokalnymi narzędziami i automatyzacją.
Jeśli chcesz kompatybilności z oprogramowaniem oczekującym kształtu żądania w stylu OpenAI, Ollama udostępnia również lokalnie endpointy /v1:
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 Uwaga: Ta etykieta “kompatybilny z OpenAI” jest łatwa do błędnego odczytania. Nie oznacza, że rozmawiasz z OpenAI i nie zmienia faktu, że serwer nadal jest lokalny. Oznacza tylko, że kształt żądania jest wystarczająco znajomy dla narzędzi i SDK zbudowanych wokół wzorca API OpenAI. Bazowy URL pozostaje http://localhost:11434/v1/, a zastępczy klucz API, na którym niektóre biblioteki klienckie nalegają, może być ignorowany do lokalnego użytku Ollama.
Skąd naprawdę pochodzą ograniczenia modeli

To jest część, która zwykle jest spłaszczana do jednej niejasnej idei “cenzury”, ale technicznie zaangażowane są trzy różne warstwy: warstwa serwująca dostawcy, dopasowanie modelu i dostrajanie instrukcji, oraz zachowanie promptu/środowiska uruchomieniowego, które sam kontrolujesz. Samodzielne hostowanie dramatycznie zmienia niektóre z tych warstw. Nie usuwa ich wszystkich.
Prosty sposób na wyobrażenie sobie tego to:
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
Wyniki:
– Warstwa serwująca kontrolowana przez dostawcę znika z lokalnej ścieżki
– Granica sieci lokalnej i logowania staje się twoja
– Własne szkolenie i dopasowanie modelu nadal są dostarczane z modelem
Gdy oddzielisz warstwy, wcześniejsze kroki konfiguracji stają się znacznie bardziej znaczące:
| Warstwa | Kontrolowana lokalnie po tej konfiguracji? | Punkt dowodowy | Co nadal pozostaje prawdą |
|---|---|---|---|
| Proces serwera | Tak | ollama.service działa na Ubuntu | Teraz kontrolujesz czas działania, logi, aktualizacje i adres powiązania |
| Granica sieci | Tak | Sprawdzenie powiązania 127.0.0.1:11434 | Lokalne żądania nie wymagają już przeskoku moderacji dostawcy |
| Prompt systemowy / domyślne środowisko uruchomieniowe | Tak | Modelfile dla kontrolowanej wiadomości systemowej | Możesz kierować zachowaniem, ale nie przepisywać szkolenia |
| Warstwa moderacji po stronie dostawcy | Zazwyczaj usunięta dla inferencji tylko lokalnej | Natywne lokalne wywołanie API powiedzie się na localhost | To jest jedna z największych zmian kontroli, jaką daje ci samodzielne hostowanie |
| Dopasowanie modelu w wagach | Nie, nie automatycznie | Różne dostrajanie modelu daje różne wyniki | Lokalny model nadal może się wahać, odmawiać lub moralizować |
| Wybór rodziny modeli | Tak | llama3.1:8b vs dolphin3 | Wybierz ten, który najlepiej odpowiada twoim potrzebom |
Można to porównać do produkcji scenicznej. Samodzielne hostowanie zmienia scenę, oświetlenie, mikrofony i notatki reżysera. Nie szkoli ponownie aktora. Jeśli model był dostrojony do ostrożnego odpowiadania, częstego wahania lub odmawiania pewnych rodzajów oprawienia, uruchomienie go lokalnie nie cofnie magicznie tego szkolenia.
To, co twoja obecna konfiguracja już udowodniła, jest węższe, ale nadal ważne: kontrolujesz proces serwera, kontrolujesz granicę API i nie kierujesz już lokalnych promptów przez warstwę moderacji należącą do dostawcy. To jest realna zmiana w prywatności i kontroli. Czego nie udowodniła, to że każdy lokalny model będzie zachowywał się tak samo lub że każda przyszła odmowa była spowodowana przez dostawcę chmurowego.
Tutaj wchodzi w grę wybór modelu. Jeśli chcesz praktycznego efektu mniejszej liczby zastrzeżeń, bardziej bezpośrednich odpowiedzi lub zachowania mniej skłonnego do odmów, nie osiągniesz tego, mówiąc głośniej “samodzielnie hostowane”. Osiągniesz to, wybierając inną rodzinę modeli lub dostrajanie — i rozumiejąc związane z tym kompromisy.
Wybierz mniej restrykcyjny model lokalny

Jeśli chcesz sprawiedliwego testu, porównuj modele, które zajmują mniej więcej tę samą klasę rozmiarów. Dlatego ten przewodnik używa llama3.1:8b jako głównego dopasowanego punktu odniesienia i dolphin3 jako modelu porównawczego mniej restrykcyjnego. Oba mają około 4,9GB, co sprawia, że różnica w zachowaniu jest łatwiejsza do interpretacji bez drastycznej zmiany footprintu sprzętowego.
Pobierz lokalnie modele do porównania:
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistralOto praktyczne opisy trzech nazw, które najprawdopodobniej zobaczysz w tej części ekosystemu Ollama:
| Model | Przybliżony rozmiar | Rola w tym artykule | Praktyczne odczytanie |
|---|---|---|---|
| llama3.1:8b | 4.9GB | Główny dopasowany punkt odniesienia | Dobry domyślny punkt odniesienia dla “normalnego” nowoczesnego zachowania podążającego za instrukcjami |
| dolphin3 | 4.9GB | Główne porównanie mniej restrykcyjne | Podobny footprint, zwykle bardziej bezpośredni, często mniej wypełniony |
| dolphin-mistral | 4.1GB | Opcjonalna starsza alternatywa | Nadal historycznie użyteczny, ale nie najlepsze aktualne porównanie do codziennego użytku |
⚠️ Ostrzeżenie: Inne dostrajanie to nie “ten sam model z usuniętą cenzurą.” Może zmienić bezpośredniość, gęstość zastrzeżeń i chęć podążania za oprawą użytkownika, ale może również zmienić ton, faktyczność, spójność i ogólną osobowość.
Wydajność GPU
Przed uruchomieniem żądanych modeli, niezbędne jest najpierw zrozumienie możliwości i ograniczeń zaangażowanego sprzętu. Są więc dwie rzeczy do przetestowania koncepcyjnie: po pierwsze, jak wygląda czyste zachowanie pojedynczego GPU na rzeczywistym sprzęcie używanym w tym przewodniku; po drugie, co się zmienia, jeśli później uruchomisz ten sam stos na hoście z dwoma GPU. Obie mają znaczenie, ale tylko pierwsza jest żywym dowodem z tej dokładnej maszyny.
Na tym serwerze, lepszym testem środowiska uruchomieniowego na wysokim końcu jest gpt-oss:20b. Jest wystarczająco duży, żeby być interesującym, a jednocześnie wciąż sensowny na jednej karcie 16GB.
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
Po załadowaniu modelu potwierdź stan środowiska uruchomieniowego:
ollama ps

To jest praktyczny dowód, którego szukasz na tej maszynie. Pokazuje, że mniejsze modele mieszczą się łatwo i że większy, ale wciąż realistyczny model lokalny może zbliżyć jedną kartę 16GB do jej użytecznej granicy bez konieczności wielu GPU.
Jeśli później uruchomisz Ollama na hoście z dwoma GPU, model taki jak qwen3:30b staje się rodzajem obciążenia, który może zademonstrować umieszczanie wieloGPU. Przepływ pracy jest taki sam — obserwuj nvidia-smi, uruchom model, sprawdź ollama ps — ale chodzi nie o to, żeby obie karty zaświeciły się dla samego efektu. Chodzi o potwierdzenie, że Ollama rozprzestrzenia model na wiele GPU tylko wtedy, gdy model nie mieści się już czysto na jednym.
Rozważania dotyczące omijania cenzury

Do porównania zachowań trzymaj warunki pod kontrolą, żebyś testował model bardziej niż losowość. Używaj tego samego endpointu, tego samego promptu, stream: false, niskiej temperatury i stałego ziarna:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'Następnie powtórz to samo żądanie z “model”: “dolphin3”. Stałe ziarno nie usuwa całej wariancji, ale redukuje jej wystarczająco dużo, żeby różnice w tonie i zgodności były łatwiejsze do zauważenia.
- Bezpiecznym pierwszym promptem jest: “Czy samodzielne hostowanie LLM oznacza, że użytkownik w pełni kontroluje zachowanie modelu? Odpowiedz w 4 punktach. Bądź bezpośredni i pomiń wstępy.” Reprezentatywna odpowiedź llama3.1:8b brzmi zazwyczaj tak:
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.Reprezentatywna odpowiedź dolphin3 na ten sam prompt często brzmi bardziej zwięźle:
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - Drugim użytecznym promptem jest: “Napisz ostry pięciozdaniowy argument za tym, dlaczego zespół wrażliwy na prywatność może odrzucić AI zarządzane przez dostawcę. Bez wstępu i bez zakończenia.” llama3.1:8b zazwyczaj spełnia to żądanie, ale w bardziej wyważonym korporacyjnym tonie. dolphin3 chętniej podąża za żądaną ostrością. To jest rodzaj różnicy, której tu szukasz: nie dramatyczne bezprawne wyniki, ale zmiany w bezpośredniości, oprawie i gęstości zastrzeżeń.
- Trzecia kategoria promptów do walidacji może być następująca: poproś o pięć faktycznych powodów, dla których pisarz może preferować model lokalny do niezwykłej, niszowej lub niemainstreamowej twórczości. W praktyce oba modele odpowiadają, ale dolphin3 zazwyczaj trzyma się bliżej żądanego tonu bez moralizowania i bezpośrednich odpowiedzi.
Wzorzec wygląda następująco:
| Typ promptu | Zachowanie bazowe llama3.1:8b | Zachowanie dolphin3 | Praktyczny wniosek |
|---|---|---|---|
| Bezpośredniość vs wahanie | Bardziej ostrożny, nieco bardziej wyjaśniający | Bardziej skompresowany i bezpośredni | Te same fakty, inny styl odmowy/zastrzeżeń |
| Zgodność z ostrzejszym tonem | Często odpowiada, ale łagodzi retorykę | Chętniej podąża za żądaną krawędzią | Posłuszeństwo oprawie jest częścią wyboru modelu |
| Niszowe oprawienie twórcze | Faktyczne, czasem wypełnione | Faktyczne, zazwyczaj mniej moralizujące | “Mniej restrykcyjny” często objawia się jako ton, a nie czysta możliwość |
Oto uczciwe wnioski:
- Wybór modelu lokalnego znacząco zmienia zachowanie wyjściowe.
- Różne modele różnią się bezpośredniością i gęstością zastrzeżeń.
- Samodzielne hostowanie usuwa warstwę serwującą kontrolowaną przez dostawcę.
Teraz kontrolujesz stos, a nie tylko prompt

Frustracja z początku tego przewodnika nigdy nie dotyczyła tylko modelu odmawiającego żądania. Chodziło o to, że warstwa serwująca, warstwa polityki i granica prywatności znajdowały się gdzieś indziej. Po tej konfiguracji ta część się zmieniła. Twój serwer inferencji działa na twojej maszynie Ubuntu, lokalna granica API jest twoja, menu modeli jest twoje, a twoje domyślne ustawienia promptu/środowiska uruchomieniowego możesz dostosowywać.
To, co nadal wymaga osądu, to część, której żaden instalator nie może za ciebie rozwiązać: wybieranie modeli pasujących do twojego przypadku użycia, kierowanie nimi z sensownymi wartościami domyślnymi i bezpieczne udostępnianie dostępu, gdy wyjdziesz poza localhost. To jest prawdziwy kształt kontroli samodzielnego hostowania. Nie magiczna wolność od wszelkich ograniczeń, ale własność stosu, który decyduje o tym, jak, gdzie i z którym modelem odbywa się inferencja. Jeśli chcesz najlepszego następnego kroku, zacznij od stworzenia niestandardowego Modelfile — lub umieszczenia bezpiecznego zdalnego dostępu przed lokalnym API, gdy będziesz gotowy.
Co zrobić po podstawowej konfiguracji

W tym momencie podstawowa obietnica jest spełniona. Serwer działa, API działa, ścieżka GPU jest prawdziwa, a różnice w zachowaniu modeli nie są już abstrakcyjne. Następnym krokiem nie jest “ślepe instalowanie kolejnych rzeczy.” Chodzi o dostrojenie części stosu, które teraz do ciebie należą.
Dostosowywanie zachowania modelu za pomocą Modelfile
Modelfile to najczystszy sposób na zmianę lokalnych domyślnych ustawień promptowania bez dotykania samych wag modelu. Zacznij od sprawdzenia aktualnej definicji modelu, żebyś rozumiał, co rozszerzasz:
ollama show --modelfile dolphin3
Następnie stwórz prostą lokalną wariację:
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192Zbuduj ją jako nową nazwę modelu i przetestuj:
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ Ważne: Modelfile zmienia zachowanie promptowania i środowiska uruchomieniowego, a nie historię szkolenia modelu. Może kierować tonem i wartościami domyślnymi, ale nie szkoli ponownie bazowego modelu.
Zabezpieczenie konfiguracji
Powiązanie z localhost jest dobrym ustawieniem domyślnym, ale nie jest końcem historii bezpieczeństwa. Najpierw sprawdź ponownie aktualny adres nasłuchiwania:
ss -tlnp | grep 11434
Jeśli celem jest utrzymanie Ollama tylko lokalnie, przypnij to zachowanie explicite za pomocą nadpisania systemd:
sudo systemctl edit ollama
Dodaj następujące:
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
Następnie przeładuj i zrestartuj usługę:
sudo systemctl daemon-reload
sudo systemctl restart ollamaJeśli później potrzebujesz zdalnego dostępu, nie publikuj bezpośrednio 11434. Zamiast tego umieść odwrotne proxy z TLS i uwierzytelnianiem przed nim:
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ Ostrzeżenie: Traktuj publiczne wystawienie jako oddzielny projekt hartowania. Ollama samo w sobie jest lokalnym serwerem inferencji, a nie gotową do produkcji publiczną bramą API z wbudowanym uwierzytelnianiem, ograniczaniem szybkości i domyślnymi ustawieniami skierowanymi do internetu.
Zalecane modele dla tego sprzętu
Gdy podstawowa instalacja działa, ulepszeniem o najwyższej wartości jest wybieranie modeli, które rzeczywiście dobrze pasują do tej maszyny, zamiast gonieniu za największym nagłówkiem. Dla serwera z pojedynczym 4070 Ti SUPER używanego tutaj, praktyczne menu wygląda następująco:
| Przypadek użycia | Model | Rozmiar | Oczekiwane umieszczenie | Dlaczego pasuje do tej maszyny |
|---|---|---|---|---|
| Pierwszy sukces | mistral | 4.4GB | Pojedynczy GPU | Szybka, prosta walidacja bez tarcia |
| Ogólny punkt odniesienia | llama3.1:8b | 4.9GB | Pojedynczy GPU | Mocny główny punkt odniesienia |
| Mniej restrykcyjny 8B | dolphin3 | 4.9GB | Pojedynczy GPU | Najlepsze porównanie jak-dla-jak z llama3.1:8b |
| Poziom rozumowania | gpt-oss:20b | 14GB | Zazwyczaj pojedynczy GPU | Mocniejsze rozumowanie przy jednoczesnym czystym dopasowaniu |
| Wyższy poziom jakości lokalnej | qwen3:30b | 19GB | Wymaga dwóch GPU lub większego VRAM | Lepszy jako cel przyszłej aktualizacji niż czyste dopasowanie dla tej konkretnej maszyny |
| Poziom skoncentrowany na kodzie | deepseek-coder:33b | 19GB | Wymaga dwóch GPU lub większego VRAM | Mocna opcja jeśli przejdziesz na większą maszynę lub dodasz drugi GPU później |
| Tylko eksperymentalny | llama3.1:70b | 43GB | Poważny przelew CPU / znacznie wolniejszy / kompromisy zredukowanego kontekstu | Nie realistyczny cel dla tego hosta, chyba że akceptujesz duże kompromisy |
Auto-start i konserwacja
Po fajnej części przychodzi ta, która sprawia, że lokalny serwer LLM jest używalny miesiąc później. Potwierdź zachowanie przy starcie, aktualizuj usługę, obserwuj logi i wiedz, jak zwolnić duże modele, gdy potrzebujesz z powrotem VRAM.
sudo systemctl is-enabled ollama
sudo systemctl enable --now ollama
curl -fsSL https://ollama.com/install.sh | sh
journalctl -u ollama -n 100 --no-pager
Do codziennych operacji na modelach, oto polecenia, których będziesz używać najczęściej:
ollama list
ollama ps
ollama stop gpt-oss:20b
sudo du -sh /usr/share/ollama/.ollama/modelsA jeśli przechowywanie modeli musi zostać przeniesione na większy dysk, przygotuj katalog dla użytkownika usługi przed ponownym wskazaniem Ollama:
sudo mkdir -p /mnt/ai/ollama-models
sudo chown -R ollama:ollama /mnt/ai/ollama-modelsNastępnie ustaw OLLAMA_MODELS przez systemctl edit ollama. Ten jeden szczegół dotyczący własności jest tym, co zapobiega zamianie migracji pamięci masowej w problem z uprawnieniami.
Podręcznik rozwiązywania problemów
Gdy coś się psuje, najszybszą ścieżką jest zazwyczaj dopasowanie objawu do właściwej warstwy zamiast próbowania losowych pętli ponownej instalacji. Użyj tej tabeli jako pierwszego przejścia:
| Objaw | Prawdopodobna przyczyna | Sprawdzenie | Naprawa |
|---|---|---|---|
| nvidia-smi kończy się niepowodzeniem | Problem ze sterownikiem lub stosem GPU | nvidia-smi, lspci -nnk | grep -A3 -Ei ‘VGA|3D|NVIDIA’, ubuntu-drivers devices | Najpierw napraw warstwę NVIDIA; jeśli Ubuntu używa nouveau, zainstaluj zalecany sterownik NVIDIA, uruchom ponownie i ponownie uruchom nvidia-smi |
| ollama.service nie uruchamia się | Problem z usługą, uprawnieniami lub powiązaniem | systemctl status ollama, journalctl -u ollama -n 100 –no-pager | Rozwiąż błąd usługi przed pobieraniem modeli |
| Model działa na CPU | Wykrywanie GPU nie powiodło się lub nastąpił fallback | ollama ps, logi | Zrestartuj usługę; jeśli potrzeba, przeładuj nvidia_uvm |
| Tylko jeden GPU jest aktywny | Model mieści się na jednej karcie | watch -n 1 nvidia-smi | To jest normalne; na hoście wieloGPU przetestuj z modelem, który przekracza kopertę VRAM jednej karty, jeśliZaoszczędź |


