 中文 (中国)
中文 (中国) English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia 





在LLM服务器上自托管Ollama,掌控AI审查
关键词
在深入设置之前,以下是本指南中最容易让读者感到困惑的术语。这份简短的词汇表从一开始就将 Linux、GPU 和本地模型的词汇阐述清楚。
| 关键词 | 简要说明 |
|---|---|
| 🤖 LLM | 大型语言模型;一种根据提示词生成文本的 AI 模型。 |
| 🦙 Ollama | 一个本地模型运行器和服务器,用于在您自己的机器上下载、部署和调用 LLM。 |
| 🖥️ GPU | 此处用于加速模型推理的图形处理器。 |
| 💾 VRAM | GPU 上的显存;它是限制一张显卡能容纳多大模型的主要因素之一。 |
| ⚡ Inference | 运行模型以生成答案的过程。 |
| 🔄 systemd | Linux 服务管理器,用于启动、停止、重启和启用 Ollama 等服务。 |
| 🧩 NVIDIA driver | 使 Ubuntu 能够正确与 NVIDIA GPU 通信以执行计算任务的软件层。 |
| 🚫 nouveau | 一种开源 Linux 图形驱动程序,若使用它而非官方 NVIDIA 驱动程序,可能会阻碍正常的 NVIDIA 计算环境配置。 |
| 📊 nvidia-smi | NVIDIA 的命令行工具,用于检查 GPU 可见性、VRAM 使用情况和驱动程序健康状态。 |
| 🔌 API endpoint | 工具或脚本调用的 URL,用于向 Ollama 发送提示词并接收响应。 |
| ☁️ Vendor-controlled serving layer | 由服务商管理的 API 层,可在模型响应之前添加内容审核、日志记录、策略执行或其他控制措施。 |
| 🧬 Fine-tune | 基础模型的改进版本,针对不同的语气、行为或特定任务进行了调优。 |
| ⚖️ Model weights | 模型学习到的内部参数;自托管不会自动改变这些参数。 |
| 📝 Modelfile | Ollama 文件,用于使用您自己的系统提示词和运行时参数创建自定义本地模型变体。 |
| 🪪 UUID | GPU 的稳定硬件标识符;它通常比数字 GPU ID 更安全,因为设备顺序可能会发生变化。 |
| 🔒 TLS | HTTPS 和反向代理使用的加密协议,用于保护客户端与服务器之间的流量安全。 |
| 🌐 Reverse proxy | 一种前端服务,可在将请求转发给 Ollama 之前添加 TLS、身份验证和受控的公共访问。 |
| 🎛️ Temperature / seed | 生成设置;temperature 影响随机性,而固定的 seed 有助于使重复测试更具可比性。 |
| 🧱 CPU spill / mixed path | 模型或工作负载的某部分超出 GPU 显存并使用 CPU 资源的情况,这可能会降低推理速度。 |
| 🔧 nvidia_uvm | 与 GPU 内存管理相关的 NVIDIA 内核模块,在故障排除期间有时需要重新加载。 |
为什么自托管 LLM 值得一试

如果您已经完成了最艰难的部分——租用了 GPU 服务器、安装了 Ubuntu、熟悉了 SSH 的使用方式,并维护着自己的服务——那么当一个托管 AI 仍然控制着最后一环时,挫败感会很快涌现。它可能拒绝一个完全正常的请求,将答案淹没在免责声明之中,不经警告地改变响应风格,并让每一个提示词都流经他人设定的边界。对于许多技术用户而言,这才是真正的挫败感所在:不仅仅是模型说了什么,而是在它说话时,谁在控制服务层。
本指南旨在通过开放的本地模型来解决这一问题,而非探讨绕过专有 API 的技巧。您将在 Ubuntu GPU 服务器上自托管 Ollama,在本地运行推理,验证 GPU 路径是否真实有效,并了解选择不同模型系列时会发生哪些变化。有一个误解需要提前澄清:自托管并不自动意味着不受限制。它意味着您掌控了更多的技术栈——并且不再依赖供应商控制的服务路径——但您运行的模型仍然可能带有其自身的对齐行为。
📝 注意:本指南中的命令已根据当前 Ollama 文档进行了验证,但下方显示的终端输出为具有代表性的示例,而非实时基准测试的截图。请将其作为成功模式的参考,而非性能声明。
最终,您将在 Ubuntu 上拥有一个可正常运行的 Ollama 服务,一个经过验证的本地 API(地址为 127.0.0.1:11434),以及 GPU 支持的推理确实在运行的证明,同时还能对主流对齐模型与限制较少的替代模型进行有依据的比较。本教程面向熟悉 SSH、Ubuntu、sudo 和 systemd,但无需具备 Ollama 使用经验的读者。
本指南所使用的具体 Ubuntu GPU 服务器

本演示基于一台真实的单 GPU Ubuntu 机器,因为模糊的”应该适用于大多数服务器”式建议正是自托管指南变得具有误导性的原因。本指南的参考机器是实际用于编写本文的那类主机:当高级个人、实验室或小型团队希望在无需直接跃升至企业级加速器机架的情况下进行私有本地推理时,他们实际会租用的那种机器。本文后续也会讨论多 GPU 的行为,因为一旦模型超出单张显卡的容量,Ollama 的表现就会有所不同,但请将那部分内容视为面向未来的参考,而非来自这台具体服务器的实测证明。
GPU 服务器 — Ryzen 9 3950X + RTX 4070 Ti Super
| 组件 | 详情 |
|---|---|
| CPU | AMD Ryzen 9 3950X(16 核 / 32 线程) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| 性能 | 对于 8B 级模型表现强劲;更大的模型则需要权衡是否溢出至 CPU 或升级硬件 |
在实际使用中,这是一套非常强劲的日常 8B 级模型配置,对于更大的本地任务也同样有用,直到 16GB VRAM 成为真正的瓶颈为止。像 llama3.1:8b 这样约 4.9GB 的模型可以轻松放入这张显卡。像 gpt-oss:20b 这样约 14GB 的模型,是在这里仍然合理的单 GPU 高端测试类型。而像 qwen3:30b 这样约 19GB 的模型,更适合作为在更大或双 GPU 主机上会有何变化的参考点,而非这台机器的适配选择。
这一区别很重要,因为本文的重点不是将尽可能大的数字塞进标题。而是展示当您希望兼顾隐私、本地控制和足够的 GPU 显存以运行实用模型而无需不断妥协时,一个合理的自托管 LLM 服务器是什么样子的。这个硬件级别正是自托管推理从理论走向现实的起点。
这也解释了您在后文中会看到的一些选择:首先使用 mistral,是因为它能快速、低阻力地证明技术栈可以正常工作,而行为对比则保持在这台机器得心应手的 8B 级别。qwen3:30b 在后文仍会出现,但仅作为在更大主机上可能触发多 GPU 分配的模型类型的理论示例,而非来自本服务器的实测证明。明确预期之后,下一步是在 Ollama 接入之前对主机进行验证。
安装 Ollama 前请先运行这些预检查

从 nvidia-smi 开始。如果此命令缺失或执行失败,请停下来先修复 NVIDIA 驱动程序。暂时不要安装 Ollama,因为损坏的 NVIDIA 技术栈会让所有后续症状看起来像是应用程序故障,而实际上却是平台故障。
首先运行 GPU 检查:
nvidia-smi
❗如果 Ubuntu 提示找不到 nvidia-smi,请不要就此认为服务器没有 GPU。在租用的 Ubuntu 机器上,一种常见的故障模式是显卡存在,但仍绑定到 nouveau 而非 NVIDIA 驱动程序。请先查阅”修复 Ubuntu 上的 Nvidia 驱动程序问题“章节。
在这类服务器上,正常的输出结果大致如下所示:
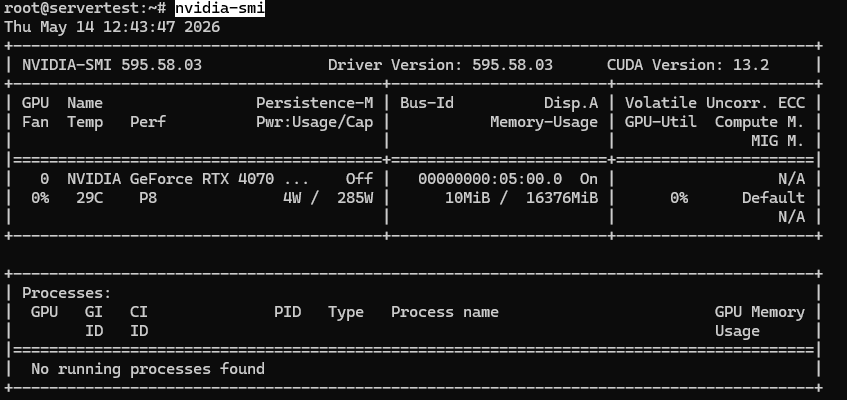
一旦 nvidia-smi 正常工作且 GPU 可见,请继续执行以下检查。
您需要确认的内容很简单:已安装的 GPU 可见,在此主机上报告的 VRAM 大约为 16GB,且驱动程序已干净加载。如果您使用的是多 GPU 服务器,同一命令应列出每张显卡。
nvidia-smi -L

❗ 重要:当前 Ollama GPU 支持文档将 NVIDIA driver 531+ 作为支持 NVIDIA 推理的实际最低要求。即使您看到过引用更低版本的旧社区说明,本指南也请以 531+ 作为要求。
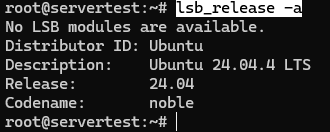
现在确认主机确实是本指南所假设的 Ubuntu 环境:
lsb_release -a
最后,在开始下载模型之前检查可用磁盘空间。安装程序本身体积很小,但模型文件却不然。一旦超出小型测试的范围,一个 20B-30B 的模型库可能会迅速占用数十 GB 的空间,因此在进行认真的本地模型工作之前,保持 100GB+ 的可用空间是正确的思路。
df -h /

如果这些检查均通过,您已经排除了主要的基础设施未知因素:GPU 存在,驱动程序基线正常,Ubuntu 已确认,磁盘有足够空间用于真实的模型拉取。到了这一步,安装 Ollama 才是清晰的下一步,而不再是一种猜测。
修复 Ubuntu 上的 Nvidia 驱动程序问题
按照以下步骤修复”nvidia-smi”命令的问题。
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
如果该输出显示了一张 NVIDIA 显卡以及类似 Kernel driver in use: nouveau 的行,请安装推荐的 Ubuntu 驱动程序包,而非单独安装 nvidia-utils。
安装 ubuntu-drivers-common 包(驱动程序管理所需)以及当前运行内核的内核头文件。
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)扫描您的系统并列出可供安装的专有驱动程序(例如 NVIDIA GPU 驱动程序)。
ubuntu-drivers devices
然后安装推荐的驱动程序包。在我们的案例中,它是:nvidia-driver-595-open:
apt install -y nvidia-driver-595-open
reboot重启后,重新运行:
nvidia-smi
nvidia-smi -L安装 Ollama 并确认服务运行正常

Ubuntu 支持的安装方式是使用官方 Ollama 安装程序,而非自定义 tarball 流程,也不是绕道 Docker。这一点很重要,因为本指南的目标是在 Linux 上获得一个具有可预测默认设置、systemd 集成和合理所有权行为的可靠本地服务。
严格按照文档运行安装程序:
curl -fsSL https://ollama.com/install.sh | sh
在一个健康的系统上,脚本会安装二进制文件、创建 ollama 服务用户、在可用时添加正确的用户组成员身份、写入 systemd 单元,并启动绑定到 127.0.0.1:11434 的服务。
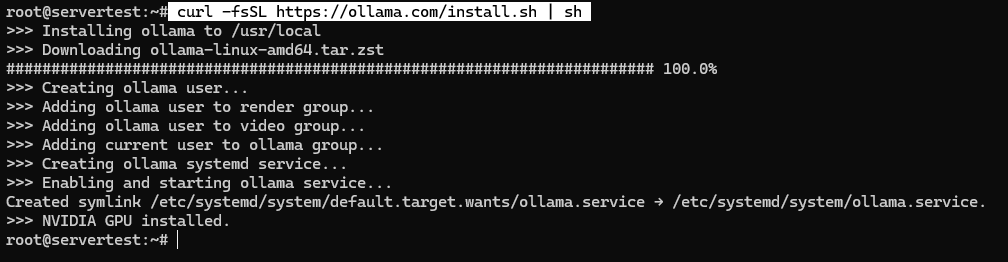
脚本完成后,请验证服务状态,而非假设成功:
sudo systemctl status ollama --no-pager
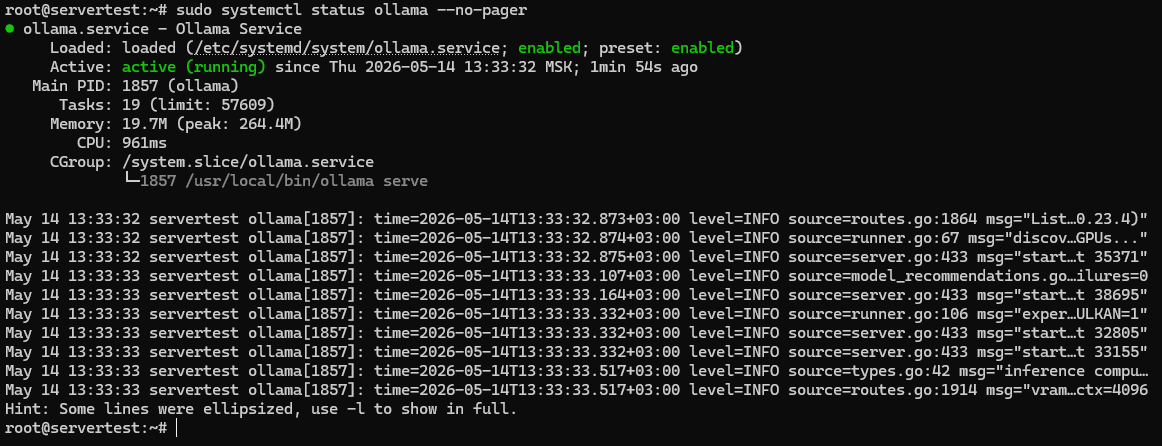
您需要在此确认三件事:单元文件已存在,服务已设置为开机启动,且 Active: active (running) 确认服务器确实已启动并运行。
首先以具体的方式确认 Linux 服务用户账户,然后再考虑模型存储的处理方式和位置。
getent passwd ollama

这一行信息解释了大量后续行为。Linux 上的模型归属于该服务的所有权,如果您后来将模型移动到另一块磁盘而未修复 ollama 用户的权限,就会造成问题。
最后一项检查确认默认绑定情况:
ss -tlnp | grep 11434

⚠️ 警告:Ollama 默认在本地 API 上不需要身份验证。当它绑定到 127.0.0.1 时这没有问题,但将端口 11434 直接暴露在互联网上是不安全的,不能将其视为已加固的公共服务。
如果服务未能正常启动,请先查看日志,而非盲目重新安装:
journalctl -u ollama -n 100 --no-pager
这是发现权限问题、启动错误、驱动程序检测问题或绑定问题的最快方法。一旦服务在本地主机上正常运行,下一步需要了解的是运行时 GPU 分配的行为方式。
Ollama 实际上如何使用单个或多个 GPU
尽管本指南所使用的服务器只有一个 GPU,但多 GPU 的行为仍值得了解,因为许多用户可能使用更大的机器,或者将来可能会扩展。很多关于双 GPU 的困惑源于错误的预期:”我有两张显卡,所以两张应该一直都亮着。”Ollama 的工作方式并非如此。实际规则要简单得多:如果一个模型能放入一张 GPU,Ollama 通常会将其保留在一张 GPU 上。只有当模型无法舒适地放入单张显卡时,它才会跨多张 GPU 分配。
每当您想查看 GPU 性能时,请结合使用以下两个命令:
ollama ps
watch -n 1 nvidia-smi
ollama ps 告诉您已加载的模型是如何被处理的。100% GPU 表示模型完全驻留在 GPU 显存中。100% CPU 表示未使用 GPU 加速。混合状态表明工作负载或驻留的某部分溢出到了 GPU 路径之外。watch -n 1 nvidia-smi 与之互补,在模型加载时实时显示每张显卡的 VRAM 使用情况。
区分这两个命令的最简便方法如下:
| 命令 | 能证明什么 | 不能证明什么 |
|---|---|---|
| ollama ps | 模型是在 GPU、CPU 还是混合路径上运行 | 具体是哪张或哪几张显卡承载了负载 |
| watch -n 1 nvidia-smi | 每张 GPU 的实时 VRAM 活动情况 | 双 GPU 使用是否自动意味着更好的模型选择 |
📝 注意:CUDA_VISIBLE_DEVICES 是一个可见性控制开关,而非”同时使用两张 GPU”的开关。如果您需要限制 GPU 访问,建议优先使用 nvidia-smi -L 中的 UUID,而非数字 ID,因为 GPU 排序在不同环境和重启后可能会发生变化。
运行您的第一个本地模型并验证 GPU 推理
此时,您不需要一个庞大的模型来证明服务器可以正常工作。您需要的是一次快速、真实的成功。mistral 是一个不错的首次拉取选择,因为它体积小、下载快、易于加载,尽管 llama3.1:8b 将在后续作为行为对比的基准模型。
首先拉取模型:
ollama pull mistral

现在通过它运行一个小提示词,让机器做些有意义的事情,而不仅仅是管理操作。响应可能需要几秒钟。
ollama run mistral "In one sentence, explain why people self-host LLMs."

为了证明这是 GPU 支持的推理而非 CPU 回退,请检查运行时状态:
ollama ps

要查看磁盘上已有的内容,请列出本地模型清单:
ollama list

mistral 是正确的首次验证选择,因为它能快速给出答案,而不会让配置验证变成漫长的等待。之后,llama3.1:8b 会更加有用,因为它是比较模型行为时更强的对齐基准。
最后,检查 Linux 安装将模型存储在何处:
sudo du -sh /usr/share/ollama/.ollama/models

该路径——/usr/share/ollama/.ollama/models——是 Ollama 文档记录的标准 Linux 模型存储位置。
一旦您看到成功的响应、ollama ps 中显示 100% GPU,以及磁盘使用量在预期位置增加,就获得了本地技术栈正常工作的第一个有意义的证明。
证明它是一个服务器,而非仅仅是 CLI 包装器

命令行提示词固然不错,但自托管 Ollama 的原因不仅仅是在终端中聊天。而是为了运行一个本地推理服务器,让其他工具、脚本和应用程序无需通过他人的 API 边界发送提示词即可进行调用。最快的证明方式是向原生 Ollama 端点发送一次干净的 HTTP 请求。
禁用流式传输发送一个本地生成请求,以便于检查首次响应:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'成功的响应应以 JSON 格式返回,大致如下所示:
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
成功检查清单很简洁:HTTP 请求在本地正常工作,返回了有效的 JSON,done: true 字段存在,模型的答案位于 response 字段中。到了这一步,Ollama 就不再只是”一个碰巧能下载模型的 CLI”,而成为了您可以真正集成到本地工具和自动化流程中的基础设施。
如果您希望与期望 OpenAI 风格请求格式的软件兼容,Ollama 还在本地暴露了 /v1 端点:
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 注意:“OpenAI 兼容”这个标签很容易被误读。它不意味着您在与 OpenAI 通信,也不改变服务器仍在本地运行的事实。它仅意味着请求格式对于基于 OpenAI API 模式构建的工具和 SDK 来说足够熟悉。基础 URL 仍为 http://localhost:11434/v1/,某些客户端库坚持要求的占位 API 密钥在本地 Ollama 使用中可以忽略。
模型限制究竟来自哪里

这部分内容通常被简化成”审查”这一模糊概念,但从技术角度来看,涉及三个不同的层面:供应商的服务层、模型的对齐与指令微调,以及您自己可以控制的提示词/运行时行为。自托管会显著改变其中某些层面,但不会消除所有层面。
可以这样来理解:
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
结果:
– 供应商控制的服务层从本地路径中消失
– 本地网络和日志边界归您所有
– 模型自身的训练和对齐行为仍随模型一同存在
一旦您区分了这些层面,前面的配置步骤就会变得更有意义:
| 层面 | 完成此配置后是否在本地受控? | 证明点 | 仍然成立的事实 |
|---|---|---|---|
| 服务器进程 | 是 | ollama.service 在 Ubuntu 上运行 | 您现在控制正常运行时间、日志、更新和绑定地址 |
| 网络边界 | 是 | 127.0.0.1:11434 绑定检查 | 本地请求不再需要经过供应商的审核跳转 |
| 系统提示词 / 运行时默认值 | 是 | 通过 Modelfile 控制系统消息 | 您可以引导行为,但无法重写训练内容 |
| 供应商端审核层 | 通常在仅本地推理时已移除 | 原生本地 API 调用在 localhost 上成功 | 这是自托管带给您的最重要的控制权转移之一 |
| 权重中的模型对齐 | 不会自动改变 | 不同的模型微调会产生不同的结果 | 本地模型仍然可能会含糊其辞、拒绝回答或进行说教 |
| 模型系列选择 | 是 | llama3.1:8b 与 dolphin3 的对比 | 选择最适合您需求的模型 |
您可以将其想象成一场舞台演出。自托管改变了舞台、灯光、麦克风和导演的指示,但它无法重新培训演员。如果一个模型经过训练会谨慎回答、经常含糊其辞或拒绝某些类型的问题,在本地运行它并不会神奇地消除这种训练。
您当前的配置所证明的范围更窄,但仍然重要:您控制服务器进程,您控制 API 边界,并且您的本地提示词不再通过供应商拥有的审核层路由。这是隐私和控制权的真实转变。它所未证明的是每个本地模型的行为方式都相同,或者未来每次拒绝都是由云服务提供商造成的。
这就是模型选择发挥作用的地方。如果您希望实际获得更少的免责声明、更直接的答案或更少拒绝式行为,仅仅高喊”自托管”并不能实现这一目标。您需要选择不同的模型系列或微调版本,并理解随之而来的权衡。
选择限制较少的本地模型

如果您想进行公平的测试,请比较大致相同大小级别的模型。这就是本指南使用 llama3.1:8b 作为主流对齐基准、使用 dolphin3 作为限制较少的对比模型的原因。它们的大小都约为 4.9GB,这使得行为差异更易于解读,同时也不会过于显著地改变硬件占用。
在本地拉取对比模型:
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistral以下是您在 Ollama 生态系统这一部分中最可能看到的三个名称的实用说明:
| 模型 | 大致大小 | 在本文中的角色 | 实用解读 |
|---|---|---|---|
| llama3.1:8b | 4.9GB | 主流对齐基准 | 作为”正常”现代指令遵循行为的良好默认参考 |
| dolphin3 | 4.9GB | 主要的限制较少对比模型 | 占用空间相近,通常更直接,填充内容更少 |
| dolphin-mistral | 4.1GB | 可选的较旧替代方案 | 历史上仍有参考价值,但不是当前最佳的日常驱动对比选择 |
⚠️ 警告:不同的微调版本并非”移除了审查的同一个模型”。它可以改变直接性、免责声明密度以及遵循用户设定框架的意愿,但也可能改变语气、事实准确性、一致性和整体个性。
GPU 性能
在运行所需模型之前,首先必须了解所涉及硬件的能力和局限性。因此,有两件事需要从概念上进行测试:第一,在本指南实际使用的硬件上,干净的单 GPU 行为是什么样的;第二,如果您稍后在双 GPU 主机上运行相同的技术栈,会发生什么变化。两者都很重要,但只有第一项是来自这台具体机器的实测证明。
在这台服务器上,更好的高端运行时测试是 gpt-oss:20b。它足够大,具有研究价值,同时在单张 16GB 显卡上仍然合理。
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
模型加载后,确认运行时状态:
ollama ps

这就是您在这台机器上想要的实际证明。它表明较小的模型可以轻松适配,而一个更大但仍然现实的本地模型可以将一张 16GB 显卡推向其可用容量的边界,而无需多张 GPU。
如果您稍后在双 GPU 主机上运行 Ollama,像 qwen3:30b 这样的模型就成为能够演示多 GPU 分配的工作负载类型。工作流程是相同的——观察 nvidia-smi,运行模型,检查 ollama ps——但重点不是为了让两张显卡都亮起而去这样做。重点是确认 Ollama 只有在模型无法干净地放入单张显卡时,才会将其分布在多个 GPU 上。
关于绕过内容审查的注意事项

进行行为对比时,请保持条件受控,以便更多地测试模型本身而非随机性。使用相同的端点、相同的提示词、stream: false、较低的 temperature 和固定的 seed:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'然后用 “model”: “dolphin3” 重复相同的请求。固定的 seed 不能消除所有变量,但它能减少足够多的随机性,使语气和合规性差异更易于观察。
- 一个安全的首个提示词是:“自托管 LLM 是否意味着用户完全控制模型的行为?用 4 个要点回答。请直接回答,省略开场白。” 具有代表性的 llama3.1:8b 答案通常听起来像这样:
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.对于同一提示词,具有代表性的 dolphin3 答案通常听起来更加精简:
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - 第二个有用的提示词是:“为注重隐私的团队可能拒绝供应商管理的 AI 写出五句犀利的理由。无需引言和结论。” llama3.1:8b 通常会作答,但语气更为温和、偏向企业风格。dolphin3 则更容易遵循所要求的犀利程度。这正是您在这里所寻找的那种差异:不是戏剧性的、毫无顾忌的输出,而是直接性、框架和免责声明密度上的变化。
- 第三类验证提示词可以是:要求列出五个作家可能偏好本地模型用于非常规、小众或非主流创意写作的实际理由。在实践中,两个模型都会作答,但 dolphin3 往往更贴近所要求的非说教语气,给出更直接的答案。
规律如下所示:
| 提示词类型 | llama3.1:8b 基准行为 | dolphin3 行为 | 实际结论 |
|---|---|---|---|
| 直接性与含糊性 | 更谨慎,解释性略强 | 更简洁、更直接 | 相同的事实,不同的拒绝/免责声明风格 |
| 犀利语气遵从度 | 通常会作答,但会软化措辞 | 更愿意遵循用户要求的边缘表达 | 框架遵从性是模型选择的一部分 |
| 小众创意框架 | 事实性,有时有填充内容 | 事实性,通常说教性更少 | “限制较少”通常体现在语气上,而非纯粹的能力上 |
因此,以下是诚实的结论:
- 本地模型选择会显著改变输出行为。
- 不同模型在直接性和免责声明密度上存在差异。
- 自托管移除了供应商控制的服务层。
您现在控制的是整个技术栈,而非仅仅是提示词

本指南开头的挫败感从来不仅仅是关于模型拒绝某个请求。而是关于服务层、策略层和隐私边界存在于其他地方这一事实。完成此配置后,这部分已经改变。您的推理服务器在您的 Ubuntu 机器上运行,本地 API 边界归您所有,模型选单归您所有,您的提示词/运行时默认值也归您自己调整。
仍然需要您自行判断的,是任何安装程序都无法替您解决的部分:选择符合您使用场景的模型、用合理的默认值引导它们,以及在准备好超出本地主机范围时安全地开放访问。这才是自托管控制权的真实面貌。不是从所有限制中获得神奇的自由,而是拥有决定推理如何发生、在哪里发生以及使用哪个模型的技术栈所有权。如果您想迈出最佳的下一步,可以从创建自定义 Modelfile 开始,或者在准备好时为本地 API 配置安全的远程访问。
基础配置完成后的下一步

此时,核心承诺已经兑现。服务器正常运行,API 正常运行,GPU 路径是真实的,模型行为差异也不再是抽象的概念。下一步不是”盲目地安装更多东西”,而是调整现在属于您的技术栈中的各个部分。
使用 Modelfile 自定义模型行为
Modelfile 是在不触及模型权重的情况下更改本地提示词默认值的最简洁方式。首先检查模型的当前定义,以便了解您将要扩展的内容:
ollama show --modelfile dolphin3
然后创建一个简单的本地变体:
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192将其构建为新的模型名称并进行测试:
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ 重要:Modelfile 改变的是提示词和运行时行为,而非模型的训练历史。它可以引导语气和默认值,但无法重新训练底层模型。
加固配置安全性
本地主机绑定是一个良好的默认设置,但这并非安全故事的终点。首先重新检查当前的监听地址:
ss -tlnp | grep 11434
如果目标是将 Ollama 保持为仅本地访问,请通过 systemd 覆盖明确锁定该行为:
sudo systemctl edit ollama
添加以下内容:
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
然后重新加载并重启服务:
sudo systemctl daemon-reload
sudo systemctl restart ollama如果您以后需要远程访问,请勿直接发布 11434 端口。而应在其前面配置带有 TLS 和身份验证的反向代理:
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ 警告:请将公开暴露视为一个独立的安全加固项目。Ollama 本身是一个本地推理服务器,而非具有内置身份验证、速率限制和面向互联网默认设置的生产就绪公共 API 网关。
适合此硬件的推荐模型
基础安装完成后,最有价值的改进是选择真正适合这台机器的模型,而非追逐最大的数字。对于本指南使用的单 RTX 4070 Ti SUPER 服务器,实用的模型菜单如下:
| 使用场景 | 模型 | 大小 | 预期分配方式 | 为何适合这台机器 |
|---|---|---|---|---|
| 首次成功验证 | mistral | 4.4GB | 单 GPU | 快速、简单、低阻力验证 |
| 通用基准 | llama3.1:8b | 4.9GB | 单 GPU | 强大的主流参考点 |
| 限制较少的 8B 模型 | dolphin3 | 4.9GB | 单 GPU | 与 llama3.1:8b 最佳的同类对比 |
| 推理层级 | gpt-oss:20b | 14GB | 通常为单 GPU | 推理能力更强,同时仍能干净适配 |
| 更高质量本地层级 | qwen3:30b | 19GB | 需要双 GPU 或更大 VRAM | 更适合作为未来升级目标,而非这台机器的干净适配选项 |
| 代码专注层级 | deepseek-coder:33b | 19GB | 需要双 GPU 或更大 VRAM | 如果您以后换用更大的机器或增加第二块 GPU,这是一个强大的选择 |
| 仅限实验性使用 | llama3.1:70b | 43GB | 严重 CPU 溢出 / 速度慢得多 / 上下文减少的权衡 | 除非您接受严重的妥协,否则对这台主机来说不是现实的目标 |
自动启动与日常维护
有趣的部分之后,是让本地 LLM 服务器在一个月后仍可正常使用的部分。确认启动时行为,保持服务更新,监控日志,并了解在需要释放 VRAM 时如何卸载大型模型。
sudo systemctl is-enabled ollama
sudo systemctl enable --now ollama
curl -fsSL https://ollama.com/install.sh | sh
journalctl -u ollama -n 100 --no-pager
对于日常模型操作,以下是您最常用的命令:
ollama list
ollama ps
ollama stop gpt-oss:20b
sudo du -sh /usr/share/ollama/.ollama/models如果模型存储必须迁移到更大的磁盘,请在重新指向 Ollama 之前为服务用户准备好目录:
sudo mkdir -p /mnt/ai/ollama-models
sudo chown -R ollama:ollama /mnt/ai/ollama-models然后通过 systemctl edit ollama 设置 OLLAMA_MODELS。这个所有权细节正是防止存储迁移演变为权限问题的关键所在。
故障排除参考
当出现问题时,最快的解决路径通常是将症状与正确的层面对应起来,而非尝试随机重装循环。请将此表格作为第一步排查手段:
| 症状 | 可能原因 | 检查方法 | 修复方法 |
|---|---|---|---|
| nvidia-smi 失败 | 驱动程序或 GPU 技术栈问题 | nvidia-smi、lspci -nnk | grep -A3 -Ei ‘VGA|3D|NVIDIA’、ubuntu-drivers devices | 先修复 NVIDIA 层;如果 Ubuntu 使用的是 nouveau,请安装推荐的 NVIDIA 驱动程序,重启后重新运行 nvidia-smi |
| ollama.service 无法启动 | 服务、权限或绑定问题 | systemctl status ollama、journalctl -u ollama -n 100 –no-pager | 在拉取模型之前先解决服务错误 |
| 模型在 CPU 上运行 | GPU 检测失败或发生回退 | ollama ps、日志 | 重启服务;如有需要,重新加载 nvidia_uvm |
| 只有一张 GPU 处于活动状态 | 模型适配于单张显卡 | watch -n 1 nvidia-smi | 这是正常现象;在多 GPU 主机上,如果您想观察多 GPU 分配,请使用超出单张显卡 VRAM 容量的模型进行测试 |
| 端口 11434 暴露在 0.0.0.0 上 | 绑定地址已更改 | ss -tlnp | grep 11434 | 设置 OLLAMA_HOST=127.0.0.1:11434 并重启 |
| 迁移存储后出现模型路径错误 | 模型目录所有权错误 | ls -ld <model-dir> | sudo chown -R ollama:ollama <model-dir> |
| 挂起/恢复后 GPU 消失 | NVIDIA UVM 问题 | 日志和 GPU 检查 | 如有需要,重新加载 nvidia_uvm 并重启服务 |
如果您只记住本节中的一条操作规则,请记住这条:将 Ollama 视为真正的服务,而非一次性的 CLI 工具。日志、所有权、绑定地址和存储路径与提示词窗口同等重要。


