 Română
Română English
English  Русский
Русский  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 la toate serviciile de găzduire
la toate serviciile de găzduireGăzduiește Ollama pe un server LLM și preia controlul asupra cenzurii AI
Cuvinte cheie
Înainte de a intra în detaliile configurării, iată termenii care pot crea cel mai mult confuzie pentru cititorii acestui ghid. Acest scurt glosar menține vocabularul Linux, GPU și modelele locale clar de la bun început.
| Cuvânt cheie | Explicație scurtă |
|---|---|
| 🤖 LLM | Model lingvistic de mari dimensiuni; un model AI care generează text pe baza unor solicitări. |
| 🦙 Ollama | Un motor și server local pentru descărcarea, servirea și apelarea LLM-urilor pe propriul calculator. |
| 🖥️ GPU | Procesorul grafic utilizat pentru accelerarea inferenței modelelor. |
| 💾 VRAM | Memoria de pe GPU; reprezintă una dintre principalele limitări privind dimensiunea unui model care poate încăpea pe o placă grafică. |
| ⚡ Inferență | Actul de a rula un model pentru a genera un răspuns. |
| 🔄 systemd | Managerul de servicii Linux utilizat pentru pornirea, oprirea, repornirea și activarea serviciilor precum Ollama. |
| 🧩 Driver NVIDIA | Stratul software care permite Ubuntu să comunice corect cu GPU-ul NVIDIA pentru sarcini de calcul. |
| 🚫 nouveau | Un driver grafic Linux open-source care poate împiedica configurarea corectă a NVIDIA pentru calcul, dacă este utilizat în locul driverului oficial NVIDIA. |
| 📊 nvidia-smi | Instrumentul de linie de comandă al NVIDIA pentru verificarea vizibilității GPU, utilizării VRAM și stării driverului. |
| 🔌 API endpoint | Un URL pe care instrumentele sau scripturile îl apelează pentru a trimite solicitări către Ollama și a primi răspunsuri. |
| ☁️ Strat de servire controlat de furnizor | Stratul API gestionat de furnizor care poate adăuga moderare, jurnalizare, aplicare de politici sau alte controale înainte ca modelul să răspundă. |
| 🧬 Fine-tune | O versiune modificată a unui model de bază, ajustată pentru un ton diferit, un comportament diferit sau sarcini cu scop special. |
| ⚖️ Ponderi ale modelului | Parametrii interni învățați ai modelului; găzduirea locală nu îi modifică automat. |
| 📝 Modelfile | Un fișier Ollama utilizat pentru a crea o variantă locală personalizată a modelului, cu propriul prompt de sistem și parametri de execuție. |
| 🪪 UUID | Un identificator hardware stabil pentru un GPU; este adesea mai sigur decât ID-urile numerice ale GPU-urilor, deoarece ordinea dispozitivelor se poate modifica. |
| 🔒 TLS | Criptarea utilizată de HTTPS și proxy-urile inverse pentru a securiza traficul dintre clienți și server. |
| 🌐 Proxy invers | Un serviciu front-end care poate adăuga TLS, autentificare și acces public controlat înainte de a transmite solicitările către Ollama. |
| 🎛️ Temperatură / seed | Setări de generare; temperatura afectează caracterul aleatoriu, în timp ce un seed fix ajută la compararea mai ușoară a testelor repetate. |
| 🧱 Depășire CPU / cale mixtă | O situație în care o parte din model sau din sarcina de lucru depășește memoria GPU și utilizează resursele CPU, ceea ce poate încetini inferența. |
| 🔧 nvidia_uvm | Un modul kernel NVIDIA legat de gestionarea memoriei GPU, care uneori trebuie reîncărcat în timpul depanării. |
De ce merită să găzduiești local un LLM

Dacă ai trecut deja prin partea dificilă — ai închiriat serverul GPU, ai instalat Ubuntu, te-ai familiarizat cu SSH și ți-ai menținut propriile servicii funcționale — devine repede frustrant când un AI găzduit extern controlează în continuare ultimul segment. Poate refuza o solicitare perfect obișnuită, poate îngropa răspunsul sub avertismente, poate schimba stilul de răspuns fără avertisment și poate menține fiecare prompt să treacă prin granița altcuiva. Pentru mulți utilizatori tehnici, aceasta este frustrarea reală: nu doar ce spune modelul, ci cine controlează stratul de servire atunci când o face.
Acest ghid este despre rezolvarea acestei probleme cu modele deschise și locale, nu despre trucuri de ocolire a API-urilor proprietare. Vei găzdui local Ollama pe un server Ubuntu GPU, vei rula inferența local, vei verifica că calea GPU este reală și vei vedea ce se schimbă atunci când alegi o altă familie de modele. O concepție greșită de clarificat de la bun început: găzduit local nu înseamnă automat fără restricții. Înseamnă că controlezi mult mai mult din stivă — și nu mai depinzi de o cale de servire controlată de furnizor — dar modelul pe care îl rulezi poate păstra în continuare propriul comportament de aliniere.
📝 Notă: Comenzile din acest ghid sunt validate pe baza documentației Ollama actuale, dar rezultatele de terminal prezentate mai jos sunt exemple reprezentative, nu capturi de benchmark în timp real. Folosește-le ca model de succes, nu ca o declarație de performanță.
La final, vei avea un serviciu Ollama funcțional pe Ubuntu, un API local verificat la 127.0.0.1:11434, dovada că inferența susținută de GPU chiar are loc și o comparație clară între un model aliniat mainstream și o alternativă mai puțin restrictivă. Acest tutorial este scris pentru cititori familiarizați cu SSH, Ubuntu, sudo și systemd, dar care nu au experiență anterioară cu Ollama.
Serverul Ubuntu GPU utilizat în acest ghid

Acest ghid pas cu pas se bazează pe un server Ubuntu real cu un singur GPU, deoarece sfaturile vagi de tipul „ar trebui să funcționeze pe majoritatea serverelor” sunt motivul pentru care ghidurile de găzduire locală devin înșelătoare. Configurația de referință de aici este clasa reală de server utilizată pentru acest ghid: tipul de mașină pe care un individ avansat, un laborator sau o echipă mică ar închiria-o atunci când doresc inferență locală privată, fără a trece direct la un rack de acceleratoare enterprise. Va fi discutat și comportamentul multi-GPU mai târziu, deoarece Ollama se schimbă odată ce un model depășește capacitatea unui singur card, dar tratează acea parte ca un context orientat spre viitor, nu ca o dovadă de pe acest server exact.
Server GPU — Ryzen 9 3950X + RTX 4070 Ti Super
| Componentă | Detalii |
|---|---|
| CPU | AMD Ryzen 9 3950X (16 nuclee / 32 fire de execuție) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| Capacitate | Puternic pentru modele din clasa 8B; modelele mai mari devin decizii de depășire sau upgrade |
În practică, aceasta este o configurație foarte puternică pentru modelele din clasa 8B utilizate zilnic și încă utilă pentru lucru local mai extins, până la punctul în care 16GB de VRAM devine constrângerea reală. Un model precum llama3.1:8b la aproximativ 4,9GB încape ușor pe această placă. Un model precum gpt-oss:20b la aproximativ 14GB reprezintă tipul de test la limita superioară a unui singur GPU care are încă sens pe această mașină. Un model precum qwen3:30b la aproximativ 19GB este mai bine tratat ca un punct de referință pentru ce se schimbă pe un server mai mare sau cu două GPU-uri, decât ca o potrivire perfectă pentru această mașină exactă.
Această distincție contează, deoarece scopul acestui articol nu este de a forța cel mai mare număr posibil într-un titlu. Este de a arăta cum arată un server LLM cu găzduire locală rezonabilă atunci când dorești confidențialitate, control local și suficientă memorie GPU pentru a rula modele utile fără compromisuri constante. Această clasă de hardware este locul unde inferența cu găzduire locală devine realistă, nu teoretică.
Explică și câteva alegeri pe care le vei vedea mai târziu: mistral este folosit primul deoarece oferă o dovadă rapidă și fără fricțiuni că stiva funcționează, în timp ce comparația de comportament rămâne în clasa 8B, unde această mașină este confortabilă. qwen3:30b apare totuși mai târziu, dar ca exemplu teoretic al tipului de model care poate declanșa plasarea multi-GPU pe un server mai mare, nu ca dovadă în direct de pe acest server. Cu așteptările stabilite, următorul pas este validarea serverului înainte ca Ollama să îl atingă.
Execută aceste verificări pre-instalare înainte de a atinge Ollama

Începe cu nvidia-smi. Dacă această comandă lipsește sau eșuează, oprește-te acolo și repară mai întâi driverul NVIDIA. Nu instala Ollama încă, deoarece o stivă NVIDIA defectă va face ca fiecare simptom ulterior să pară o eroare de aplicație, când de fapt este o eroare de platformă.
Rulează mai întâi verificarea GPU:
nvidia-smi
❗Dacă Ubuntu spune că nvidia-smi lipsește, nu presupune că serverul nu are GPU. Un mod de eșec frecvent pe serverele Ubuntu închiriate este că placa este prezentă, dar legată în continuare la nouveau în loc de driverul NVIDIA. Verifică mai întâi secțiunea „Rezolvă problema cu driverul Nvidia pe Ubuntu“.
Un rezultat sănătos pe această clasă de server ar trebui să arate aproximativ astfel:
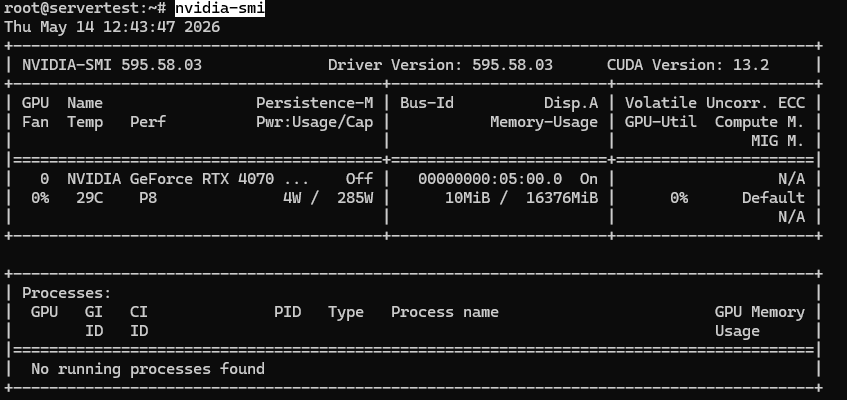
Odată ce nvidia-smi funcționează și GPU-ul este vizibil, continuă cu verificările de mai jos.
Ceea ce vrei să confirmi este simplu: GPU-ul instalat este vizibil, raportează aproximativ 16GB de VRAM pe acest server și driverul este încărcat corect. Dacă ești pe un server cu mai multe GPU-uri, aceeași comandă ar trebui să listeze fiecare placă.
nvidia-smi -L

❗ Important: Documentația actuală de suport GPU Ollama utilizează driverul NVIDIA 531+ ca limită minimă reală pentru inferența NVIDIA suportată. Tratează 531+ ca cerință pentru acest ghid, chiar dacă ai văzut note din comunitate care citează versiuni mai vechi.
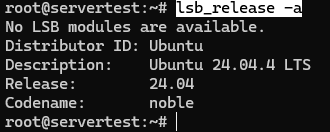
Acum confirmă că serverul este cu adevărat mediul Ubuntu pe care îl presupune acest ghid:
lsb_release -a
În final, verifică spațiul liber pe disc înainte de a începe descărcarea modelelor. Instalarea în sine este mică; modelele nu sunt. Odată ce treci dincolo de teste minore, o bibliotecă de 20B-30B poate consuma rapid zeci de gigaocteți, așa că 100GB+ liber este mentalitatea corectă înainte de lucrul serios cu modele locale.
df -h /

Dacă aceste verificări trec, ai eliminat principalele necunoscute ale infrastructurii: GPU-urile sunt prezente, linia de bază a driverului este solidă, Ubuntu este confirmat și discul are spațiu pentru descărcări reale de modele. Acesta este momentul în care instalarea Ollama devine un pas următor curat, nu o ghicitoare.
Rezolvă problema cu driverul Nvidia pe Ubuntu
Urmează pașii de mai jos pentru a rezolva problemele cu comanda „nvidia-smi”.
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
Dacă acel rezultat arată o placă NVIDIA și o linie precum Kernel driver in use: nouveau, instalează pachetul de drivere Ubuntu recomandat în loc să instalezi doar nvidia-utils.
Instalează pachetul ubuntu-drivers-common (necesar pentru gestionarea driverelor) și antetele de kernel pentru kernelul curent în execuție.
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)Scanează sistemul și listează driverele proprietare disponibile (ex.: drivere GPU NVIDIA) care pot fi instalate.
ubuntu-drivers devices
Apoi instalează pachetul de driver recomandat. În cazul nostru a fost: nvidia-driver-595-open:
apt install -y nvidia-driver-595-open
rebootDupă repornire, rulează din nou:
nvidia-smi
nvidia-smi -LInstalează Ollama și confirmă că serviciul funcționează corect

Calea Ubuntu suportată este programul de instalare oficial Ollama, nu un flux de tarball personalizat și nici o abordare prin Docker. Acest lucru contează deoarece ghidul urmărește obținerea unui serviciu local fiabil cu valori implicite previzibile, integrare systemd și un comportament corect al proprietății pe Linux.
Rulează programul de instalare exact conform documentației:
curl -fsSL https://ollama.com/install.sh | sh
Pe un sistem sănătos, scriptul instalează binarul, creează utilizatorul de serviciu ollama, adaugă apartenența corectă la grupuri când este disponibil, scrie unitatea systemd și pornește serviciul legat la 127.0.0.1:11434.
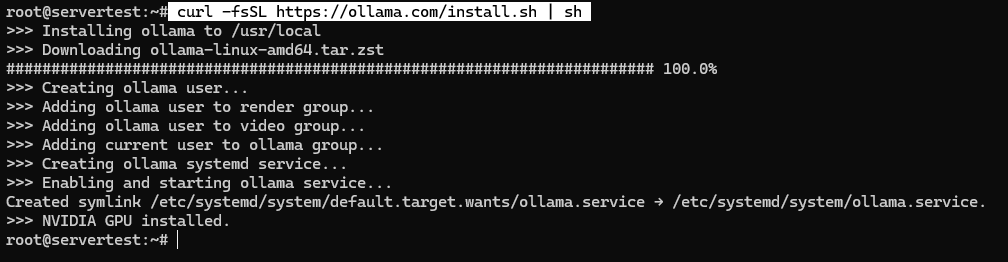
Odată ce scriptul se termină, validează serviciul în loc să presupui succesul:
sudo systemctl status ollama --no-pager
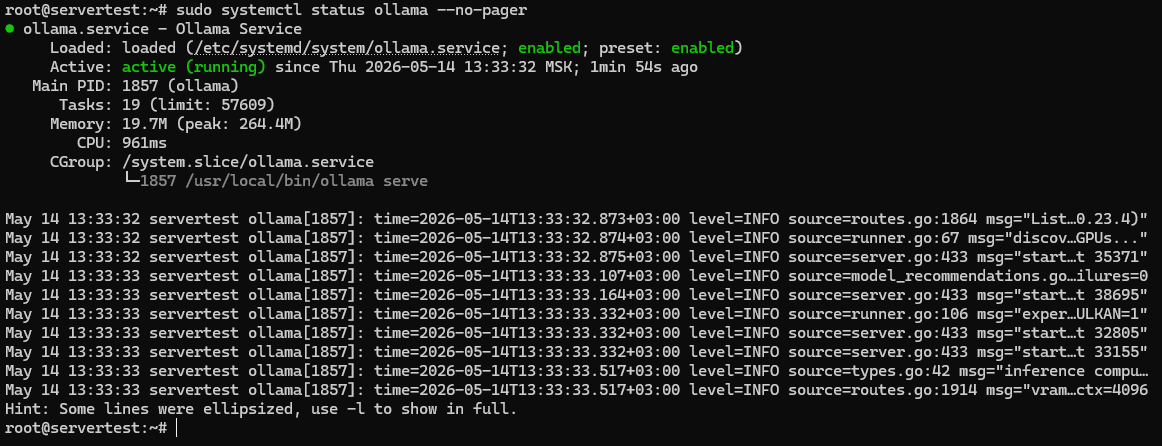
Cauți trei lucruri: fișierul unității este prezent, serviciul este activat la pornire și Active: active (running) confirmă că serverul este efectiv pornit.
Mai întâi, stabilește concret contul de utilizator pentru serviciul Linux și abia apoi gândește-te la modul și locul în care va fi gestionată stocarea modelelor.
getent passwd ollama

Această linie unică explică o mare parte din comportamentul viitor. Modelele pe Linux trăiesc sub proprietatea serviciului și, dacă le muți ulterior pe un alt disc fără a corecta permisiunile pentru utilizatorul ollama, îți creezi singur probleme.
O ultimă verificare închide bucla privind legarea implicită:
ss -tlnp | grep 11434

⚠️ Avertisment: Ollama nu necesită autentificare pe API-ul local în mod implicit. Aceasta este în regulă când este legat la 127.0.0.1, dar nu este sigur să expui portul 11434 direct pe internet ca și cum ar fi un serviciu public întărit.
Dacă serviciul nu pornește corect, mergi mai întâi la jurnale în loc să reinstalezi orbește:
journalctl -u ollama -n 100 --no-pager
Aceasta este cea mai rapidă modalitate de a detecta probleme de permisiuni, erori de pornire, probleme de detectare a driverelor sau probleme de legare. Odată ce serviciul funcționează corect pe localhost, următorul lucru de înțeles este cum se comportă plasarea GPU la runtime.
Cum utilizează Ollama de fapt unul sau mai multe GPU-uri
Chiar dacă serverul utilizat în acest ghid are un singur GPU, comportamentul multi-GPU merită în continuare înțeles, deoarece mulți utilizatori pot fi pe servere mai mari sau pot face extinderi ulterior. O mare parte din confuzia legată de două GPU-uri pornește de la o așteptare greșită: „Am două plăci, deci ambele ar trebui să fie active tot timpul.” Acesta nu este modul în care funcționează Ollama. Regula practică este mult mai simplă: dacă un model încape pe un GPU, Ollama îl va ține de obicei pe un singur GPU. Se extinde pe mai multe GPU-uri doar atunci când modelul nu încape confortabil pe o singură placă.
Folosește aceste două verificări împreună ori de câte ori vrei să vezi performanța GPU:
ollama ps
watch -n 1 nvidia-smi
ollama ps îți spune cum este procesat modelul încărcat. 100% GPU înseamnă că modelul este complet rezident în memoria GPU. 100% CPU înseamnă că accelerarea GPU nu este utilizată. O stare mixtă îți spune că o parte din sarcina de lucru sau din rezidență a depășit calea GPU. watch -n 1 nvidia-smi completează aceasta afișând utilizarea VRAM în timp real per placă în timp ce modelul este încărcat.
Cea mai rapidă modalitate de a menține aceste roluri clare este aceasta:
| Comandă | Ce dovedește | Ce nu dovedește |
|---|---|---|
| ollama ps | Dacă modelul rulează pe GPU, CPU sau o cale mixtă | Care anume placă sau plăci poartă sarcina |
| watch -n 1 nvidia-smi | Activitatea VRAM în timp real per GPU | Dacă utilizarea dual-GPU înseamnă automat o alegere mai bună a modelului |
📝 Notă: CUDA_VISIBLE_DEVICES este un control de vizibilitate, nu un comutator „folosește ambele GPU-uri”. Dacă limitezi vreodată accesul la GPU, preferă UUID-urile din nvidia-smi -L față de ID-urile numerice, deoarece ordinea GPU-urilor poate varia între medii și reporniri.
Rulează primul tău model local și verifică inferența GPU
În acest moment, nu ai nevoie de un model imens pentru a dovedi că serverul funcționează. Ai nevoie de un succes rapid și onest. mistral este o primă descărcare bună, deoarece este mic, se descarcă rapid și se încarcă ușor, chiar dacă llama3.1:8b va fi ulterior linia de bază pentru compararea comportamentului.
Începe prin descărcarea modelului:
ollama pull mistral

Acum rulează un prompt mic prin el, astfel încât mașina să facă ceva util, nu doar administrativ. Răspunsul poate dura câteva secunde.
ollama run mistral "In one sentence, explain why people self-host LLMs."

Pentru a dovedi că aceasta este inferență susținută de GPU, nu o revenire la CPU, verifică starea de runtime:
ollama ps

Și pentru a vedea ce este deja pe disc, listează inventarul local:
ollama list

mistral este prima dovadă potrivită deoarece îți oferă un răspuns rapid fără a transforma validarea configurării într-o așteptare lungă. Ulterior, llama3.1:8b devine mai util deoarece este o linie de bază aliniată mai puternică pentru compararea comportamentului modelelor.
În final, verifică unde stochează instalarea Linux modelele:
sudo du -sh /usr/share/ollama/.ollama/models

Acea cale — /usr/share/ollama/.ollama/models — este depozitul standard de modele Linux documentat de Ollama.
Odată ce vezi un răspuns de succes, 100% GPU în ollama ps și utilizarea discului crescând în locul așteptat, ai prima dovadă semnificativă că stiva locală funcționează.
Dovedește că este un server, nu doar un wrapper CLI

Un prompt în linie de comandă este util, dar motivul pentru a găzdui local Ollama nu este doar să conversezi într-un terminal. Este să rulezi un server de inferență local pe care alte instrumente, scripturi și aplicații îl pot apela fără a trimite prompturi prin granița API-ului altcuiva. Cea mai rapidă dovadă este o singură solicitare HTTP curată către endpoint-ul nativ Ollama.
Trimite o solicitare de generare locală cu streaming dezactivat, astfel încât primul răspuns să fie ușor de inspectat:
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'Un răspuns de succes ar trebui să vină ca JSON și să arate aproximativ astfel:
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
Lista de verificare a succesului este simplă: solicitarea HTTP funcționează local, JSON valid vine înapoi, done: true este prezent și răspunsul modelului se află în response. Acesta este momentul în care Ollama încetează să mai fie „un CLI care descarcă modele” și devine infrastructură pe care o poți integra efectiv în instrumente locale și automatizare.
Dacă dorești compatibilitate cu software care așteaptă o formă de solicitare de tip OpenAI, Ollama expune și endpoint-uri /v1 local:
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 Notă: Eticheta „compatibil cu OpenAI” este ușor de înțeles greșit. Nu înseamnă că vorbești cu OpenAI și nu schimbă faptul că serverul este în continuare local. Înseamnă doar că forma solicitării este suficient de familiară pentru instrumentele și SDK-urile construite în jurul modelului API OpenAI. URL-ul de bază rămâne http://localhost:11434/v1/, iar orice cheie API substituent pe care unele biblioteci client insistă să o folosești poate fi ignorată pentru utilizarea locală a Ollama.
De unde vin cu adevărat restricțiile modelelor

Aceasta este partea care de obicei este simplificată într-o singură idee vagă de „cenzură”, dar tehnic există trei straturi diferite implicate: stratul de servire al furnizorului, alinierea modelului și ajustarea instrucțiunilor, și comportamentul prompt/runtime pe care îl controlezi tu însuți. Găzduirea locală schimbă dramatic unele dintre aceste straturi. Nu le șterge pe toate.
O modalitate simplă de a-l vizualiza este aceasta:
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
Rezultate:
– Stratul de servire controlat de furnizor dispare din calea locală
– Rețeaua locală și granița de jurnalizare devin ale tale
– Propria pregătire și aliniere a modelului vin în continuare cu modelul
Odată ce separi straturile, pașii anteriori de configurare devin mult mai semnificativi:
| Strat | Controlat local după această configurare? | Punct de dovadă | Ce rămâne totuși adevărat |
|---|---|---|---|
| Procesul serverului | Da | ollama.service rulează pe Ubuntu | Acum controlezi disponibilitatea, jurnalele, actualizările și adresa de legare |
| Granița de rețea | Da | Verificarea legării 127.0.0.1:11434 | Solicitările locale nu mai necesită un salt de moderare al furnizorului |
| Prompt de sistem / valori implicite de runtime | Da | Modelfile pentru mesaj de sistem controlat | Poți ghida comportamentul, dar nu poți rescrie pregătirea |
| Stratul de moderare al furnizorului | De obicei eliminat pentru inferența exclusiv locală | Apelul API local nativ reușește pe localhost | Acesta este unul dintre cele mai mari schimbări de control pe care ți le oferă găzduirea locală |
| Alinierea modelului în ponderi | Nu, nu automat | Ajustare diferită a modelului dă rezultate diferite | Un model local poate în continuare ezita, refuza sau moraliza |
| Alegerea familiei de modele | Da | llama3.1:8b vs dolphin3 | Alege cel care se potrivește cel mai bine nevoilor tale |
Poți să te gândești la asta ca la o producție de scenă. Găzduirea locală schimbă scena, iluminatul, microfoanele și notele regizorului. Nu reantrenează actorul. Dacă un model a fost ajustat să răspundă cu prudență, să ezite frecvent sau să refuze anumite tipuri de formulări, rularea lui local nu va anula magic acea pregătire.
Ceea ce configurarea ta actuală a dovedit deja este mai limitat, dar totuși important: controlezi procesul serverului, controlezi granița API și nu mai ruiezi prompturile locale printr-un strat de moderare deținut de furnizor. Aceasta este o schimbare reală de confidențialitate și control. Ceea ce nu a dovedit este că fiecare model local se va comporta în același mod sau că fiecare refuz viitor a fost cauzat de un furnizor cloud.
Aici intervine alegerea modelului. Dacă vrei efectul practic al mai puțin avertismente, răspunsuri mai directe sau comportament mai puțin predispus la refuzuri, nu ajungi acolo spunând „găzduit local” mai tare. Ajungi acolo alegând o altă familie de modele sau fine-tune — și înțelegând compromisurile care vin cu aceasta.
Alege un model local mai puțin restricționat

Dacă vrei un test corect, compară modele care ocupă aproximativ aceeași clasă de dimensiuni. De aceea acest ghid folosește llama3.1:8b ca linie de bază aliniată mainstream și dolphin3 ca model de comparație mai puțin restricționat. Ambele sunt în jur de 4,9GB, ceea ce face diferența de comportament mai ușor de interpretat fără a schimba drastic și amprenta hardware.
Descarcă local modelele de comparație:
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistralIată cadrul practic pentru cele trei nume pe care le vei vedea cel mai probabil în această parte a ecosistemului Ollama:
| Model | Dimensiune aprox. | Rol în acest articol | Interpretare practică |
|---|---|---|---|
| llama3.1:8b | 4,9GB | Linie de bază aliniată mainstream | Referință implicită bună pentru comportamentul modern „normal” de urmărire a instrucțiunilor |
| dolphin3 | 4,9GB | Comparație principală mai puțin restricționată | Amprentă similară, de obicei mai direct, adesea mai puțin umplut cu avertismente |
| dolphin-mistral | 4,1GB | Alternativă mai veche opțională | Încă util din punct de vedere istoric, dar nu cea mai bună comparație pentru utilizarea zilnică actuală |
⚠️ Avertisment: Un fine-tune diferit nu înseamnă „același model cu cenzura eliminată.” Poate schimba directitatea, densitatea avertismentelor și dorința de a urma formularea utilizatorului, dar poate schimba și tonul, acuratețea, consistența și personalitatea generală.
Performanța GPU
Înainte de a rula modelele dorite, este esențial să înțelegi mai întâi posibilitățile și limitările hardware-ului implicat. Există deci două lucruri de testat conceptual: în primul rând, cum arată comportamentul curat pe un singur GPU pe hardware-ul real utilizat în acest ghid; în al doilea rând, ce se schimbă dacă rulezi ulterior aceeași stivă pe un server cu două GPU-uri. Ambele contează, dar numai primul este o dovadă în direct de pe această mașină exactă.
Pe acest server, testul de runtime mai bun la limita superioară este gpt-oss:20b. Este suficient de mare pentru a fi interesant, rămânând totuși rezonabil pe o placă de 16GB.
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
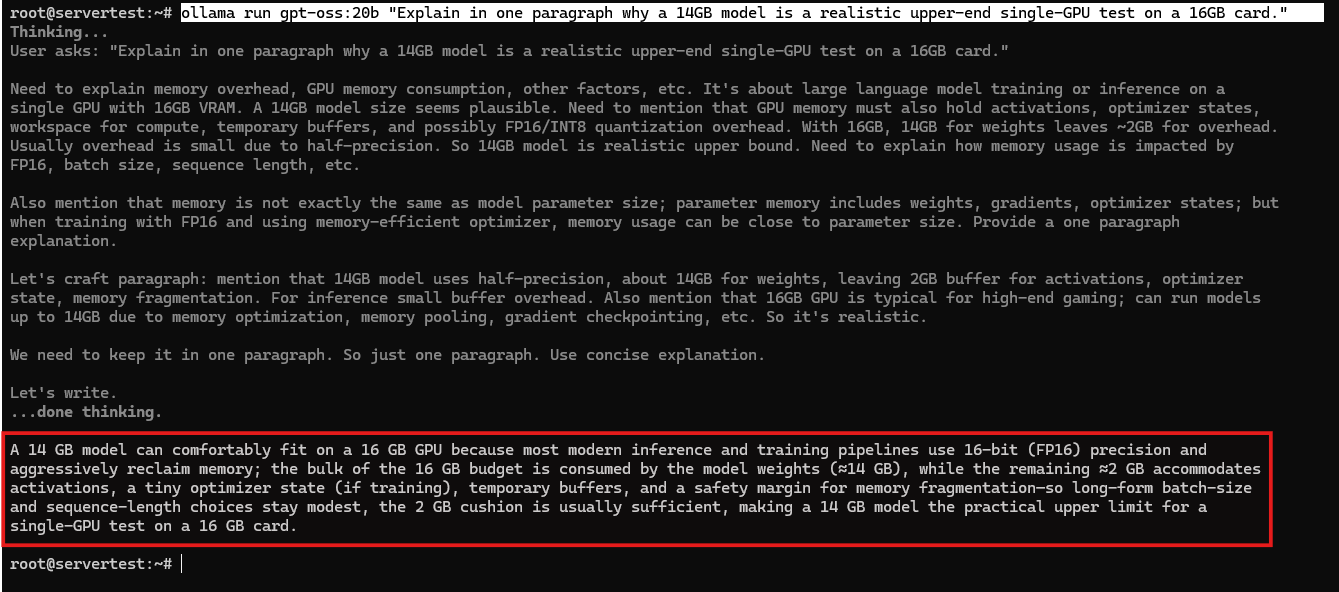
După încărcarea modelului, confirmă starea de runtime:
ollama ps

Aceasta este dovada practică pe care o dorești pe această mașină. Arată că modelele mai mici încap ușor și că un model local mai mare, dar totuși realist, poate împinge un card de 16GB aproape de limita sa utilizabilă fără a necesita mai multe GPU-uri.
Dacă rulezi ulterior Ollama pe un server cu două GPU-uri, un model precum qwen3:30b devine tipul de sarcină de lucru care poate demonstra plasarea multi-GPU. Fluxul de lucru este același — urmărește nvidia-smi, rulează modelul, inspectează ollama ps — dar scopul nu este să faci ambele plăci să se activeze de dragul de a o face. Scopul este să confirmi că Ollama extinde un model pe mai multe GPU-uri doar atunci când modelul nu mai încape curat pe unul singur.
Considerații privind ocolirea cenzurii

Pentru compararea comportamentului, menține condițiile controlate astfel încât să testezi modelul mai mult decât aleatorietatea. Folosește același endpoint, același prompt, stream: false, o temperatură scăzută și un seed fix:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'Apoi repetă aceeași solicitare cu “model”: “dolphin3”. Seed-ul fix nu elimină toată varianța, dar reduce suficient aleatorietatea pentru a face mai ușor de observat diferențele de ton și conformitate.
- Un prim prompt sigur este: „Înseamnă găzduirea locală a unui LLM că utilizatorul controlează pe deplin comportamentul modelului? Răspunde în 4 puncte. Fii direct și omite introducerile.” Un răspuns reprezentativ llama3.1:8b tinde să sune astfel:
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.Un răspuns reprezentativ dolphin3 la același prompt sună adesea mai simplificat:
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - Un al doilea prompt util este: „Scrie un argument concis în cinci propoziții pentru care o echipă sensibilă la confidențialitate ar putea respinge AI-ul gestionat de furnizor. Fără introducere și fără concluzie.” llama3.1:8b respectă de obicei cererea, dar într-un ton corporativ mai măsurat. dolphin3 urmărește mai ușor claritatea solicitată. Acesta este tipul de diferență pe care îl cauți: nu un rezultat dramatic fără lege, ci schimbări în directitate, formulare și densitatea avertismentelor.
- A treia categorie de prompturi pentru validare poate fi următoarea: cere cinci motive factuale pentru care un scriitor ar putea prefera un model local pentru lucrări creative neobișnuite, de nișă sau non-mainstream. În practică, ambele modele răspund, dar dolphin3 tinde să rămână mai aproape de tonul non-moralizator solicitat și de răspunsurile directe.
Tiparul arată astfel:
| Tip de prompt | Comportamentul de bază llama3.1:8b | Comportamentul dolphin3 | Concluzie practică |
|---|---|---|---|
| Directitate vs ezitare | Mai prudent, ușor mai explicativ | Mai comprimat și direct | Aceleași fapte, stil diferit de refuz/avertisment |
| Conformitatea cu un ton mai ferm | Răspunde adesea, dar temperează retorica | Mai dispus să urmeze marginea solicitată | Ascultarea de formulare face parte din alegerea modelului |
| Formulare creativă de nișă | Factual, uneori umplut cu informații inutile | Factual, de obicei mai puțin moralizator | „Mai puțin restricționat” apare adesea ca ton, nu ca abilitate pură |
Astfel, iată concluziile oneste:
- Alegerea modelului local schimbă semnificativ comportamentul outputului.
- Diferite modele variază în directitate și densitatea avertismentelor.
- Găzduirea locală elimină un strat de servire controlat de furnizor.
Acum controlezi stiva, nu doar promptul

Frustrarea de la începutul acestui ghid nu a fost niciodată doar despre un model care refuză o solicitare. A fost despre faptul că stratul de servire, stratul de politici și granița de confidențialitate se aflau în altă parte. După această configurare, acea parte s-a schimbat. Serverul tău de inferență rulează pe mașina ta Ubuntu, granița API locală este a ta, meniul de modele este al tău și valorile tale implicite de prompt/runtime sunt ale tale de ajustat.
Ceea ce necesită în continuare judecată este partea pe care niciun program de instalare nu o poate rezolva pentru tine: alegerea modelelor care se potrivesc cazului tău de utilizare, ghidarea lor cu valori implicite sane și expunerea accesului în mod sigur dacă te muți dincolo de localhost. Aceasta este forma reală a controlului de găzduire locală. Nu libertate magică față de orice restricție, ci proprietatea stivei care decide cum, unde și cu ce model are loc inferența. Dacă vrei cel mai bun pas următor, începe prin crearea unui Modelfile personalizat — sau prin plasarea accesului de la distanță securizat în fața API-ului local când ești pregătit.
Ce să faci după configurarea de bază

În acest moment, promisiunea de bază este îndeplinită. Serverul funcționează, API-ul funcționează, calea GPU este reală și diferențele de comportament ale modelelor nu mai sunt abstracte. Următoarea mișcare nu este „instalează mai multe lucruri orbește.” Este să ajustezi părțile din stivă care îți aparțin acum.
Personalizarea comportamentului modelului cu un Modelfile
Un Modelfile este cea mai curată modalitate de a schimba valorile implicite locale de prompting fără a atinge ponderile modelului. Începe prin inspectarea definiției curente a modelului astfel încât să înțelegi ce extinzi:
ollama show --modelfile dolphin3
Apoi creează o variație locală simplă:
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192Construiește-o ca un nume nou de model și testează-o:
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ Important: Un Modelfile schimbă comportamentul de prompting și runtime, nu istoricul de pregătire al modelului. Poate ghida tonul și valorile implicite, dar nu reantrenează modelul de bază.
Securizarea configurării
Legarea la localhost este o valoare implicită bună, dar nu este sfârșitul poveștii de securitate. Verifică mai întâi adresa curentă de ascultare:
ss -tlnp | grep 11434
Dacă scopul este să menții Ollama exclusiv local, fixează acel comportament explicit cu o suprascriere systemd:
sudo systemctl edit ollama
Adaugă următoarele:
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
Apoi reîncarcă și repornește serviciul:
sudo systemctl daemon-reload
sudo systemctl restart ollamaDacă ai nevoie de acces de la distanță mai târziu, nu publica 11434 direct. Pune în schimb un proxy invers cu TLS și autentificare în fața lui:
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ Avertisment: Tratează expunerea publică ca un proiect separat de întărire a securității. Ollama singur este un server de inferență local, nu un gateway API public pregătit pentru producție, cu autentificare integrată, limitare a ratei și valori implicite orientate spre internet.
Modele recomandate pentru acest hardware
Odată ce instalarea de bază funcționează, cea mai valoroasă îmbunătățire este alegerea modelelor care se potrivesc cu adevărat bine acestei mașini, în loc să urmărești cel mai mare titlu posibil. Pentru serverul cu un singur 4070 Ti SUPER utilizat aici, meniul practic arată astfel:
| Caz de utilizare | Model | Dimensiune | Plasare așteptată | De ce se potrivește acestei mașini |
|---|---|---|---|---|
| Primul succes | mistral | 4,4GB | GPU unic | Validare rapidă, simplă, fără fricțiuni |
| Linie de bază generală | llama3.1:8b | 4,9GB | GPU unic | Punct de referință mainstream puternic |
| 8B mai puțin restricționat | dolphin3 | 4,9GB | GPU unic | Cea mai bună comparație similară cu llama3.1:8b |
| Nivel de raționament | gpt-oss:20b | 14GB | De obicei GPU unic | Raționament mai puternic, încadrându-se totuși curat |
| Nivel local de calitate superioară | qwen3:30b | 19GB | Necesită dual-GPU sau VRAM mai mare | Mai bun ca țintă pentru upgrade viitor decât ca potrivire perfectă pentru această mașină exactă |
| Nivel axat pe cod | deepseek-coder:33b | 19GB | Necesită dual-GPU sau VRAM mai mare | Opțiune puternică dacă treci la un server mai mare sau adaugi un al doilea GPU mai târziu |
| Doar experimental | llama3.1:70b | 43GB | Depășire severă CPU / mult mai lent / compromisuri de context redus | Nu este o țintă realistă pentru acest server dacă nu accepți un compromis major |
Pornire automată și întreținere
După partea distractivă vine partea care menține un server LLM local utilizabil peste o lună. Confirmă comportamentul la pornire, menține serviciul actualizat, urmărește jurnalele și știi cum să descarci modelele mari când ai nevoie de VRAM înapoi.
sudo systemctl is-enabled ollama
sudo systemctl enable --now ollama
curl -fsSL https://ollama.com/install.sh | sh
journalctl -u ollama -n 100 --no-pager
Pentru operațiunile zilnice cu modele, acestea sunt comenzile pe care le vei folosi cel mai des:
ollama list
ollama ps
ollama stop gpt-oss:20b
sudo du -sh /usr/share/ollama/.ollama/modelsȘi dacă stocarea modelelor trebuie mutată pe un disc mai mare, pregătește directorul pentru utilizatorul serviciului înainte de a redirecționa Ollama:
sudo mkdir -p /mnt/ai/ollama-models
sudo chown -R ollama:ollama /mnt/ai/ollama-modelsApoi setează OLLAMA_MODELS prin systemctl edit ollama. Acel detaliu de proprietate este ceea ce împiedică o migrare de stocare să se transforme într-o problemă de permisiuni.
Referință pentru depanare
Când ceva se defectează, cea mai rapidă cale este de obicei să potrivești simptomul cu stratul corect, în loc să încerci bucle aleatorii de reinstalare. Folosește acest tabel ca primă trecere:
| Simptom | Cauză probabilă | Verificare | Remediere |
|---|---|---|---|
| nvidia-smi eșuează | Problemă cu driverul sau stiva GPU | nvidia-smi, lspci -nnk | grep -A3 -Ei ‘VGA|3D|NVIDIA’, ubuntu-drivers devices | Repară mai întâi stratul NVIDIA; dacă Ubuntu folosește nouveau, instalează driverul NVIDIA recomandat, repornește și rulează din nou nvidia-smi |
| ollama.service nu pornește | Problemă de serviciu, permisiuni sau legare | systemctl status ollama, journalctl -u ollama -n 100 –no-pager | Rezolvă eroarea de serviciu înainte de a descărca modele |
| Modelul rulează pe CPU | Detectarea GPU a eșuat sau a apărut un fallback | ollama ps, jurnale | Repornește serviciul; dacă este necesar reîncarcă nvidia_uvm |
| Doar un GPU este activ | Modelul încape pe o singură placă | watch -n 1 nvidia-smi | Acesta este normal; pe un server cu mai multe GPU-uri, testează cu un model care depășește plicul VRAM al unei singure plăci dacă vrei să observi plasarea multi-GPU |
| Portul 11434 este expus pe 0.0.0.0 | Adresa de legare s-a schimbat | ss -tlnp | grep 11434 | Setează OLLAMA_HOST=127.0.0.1:11434 și repornește |
| Erori de cale a modelului după mutarea stocării | Proprietate greșită pe directorul modelului | ls -ld <model-dir> | sudo chown -R ollama:ollama <model-dir> |
| GPU dispare după suspendare/reluare | Problemă NVIDIA UVM | jurnale și verificări GPU | Reîncarcă nvidia_uvm și repornește serviciul dacă este necesar |
Dacă îți amintești o singură regulă operațională din această secțiune, face-o pe aceasta: tratează Ollama ca un serviciu real, nu ca un utilitar CLI de unică folosință. Jurnalele, proprietatea, adresele de legare și căile de stocare contează la fel de mult ca și fereastra de prompt.


