 Français
Français English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 




 sur tous les services d'hébergement
sur tous les services d'hébergementHébergez Ollama sur un serveur LLM et prenez le contrôle sur la censure de l’IA
Mots-clés
Avant de plonger dans la configuration, voici les termes susceptibles de dérouter les lecteurs dans ce guide. Ce glossaire rapide clarifie le vocabulaire de Linux, GPU et des modèles locaux dès le départ.
| Mot-clé | Brève explication |
|---|---|
| 🤖 LLM | Grand modèle de langage ; un modèle d’IA qui génère du texte à partir de prompts. |
| 🦙 Ollama | Un exécuteur et serveur de modèles locaux pour télécharger, servir et appeler des LLM sur votre propre machine. |
| 🖥️ GPU | Le processeur graphique utilisé ici pour accélérer l’inférence du modèle. |
| 💾 VRAM | La mémoire du GPU ; c’est l’une des principales limites quant à la taille d’un modèle pouvant tenir sur une carte. |
| ⚡ Inférence | L’acte d’exécuter un modèle pour générer une réponse. |
| 🔄 systemd | Le gestionnaire de services Linux utilisé pour démarrer, arrêter, redémarrer et activer des services tels qu’Ollama. |
| 🧩 Pilote NVIDIA | La couche logicielle qui permet à Ubuntu de communiquer correctement avec le GPU NVIDIA pour les charges de travail de calcul. |
| 🚫 nouveau | Un pilote graphique Linux open source qui peut empêcher une configuration de calcul NVIDIA correcte s’il est utilisé à la place du pilote NVIDIA officiel. |
| 📊 nvidia-smi | L’outil en ligne de commande de NVIDIA pour vérifier la visibilité du GPU, l’utilisation de la VRAM et l’état du pilote. |
| 🔌 API endpoint | Une URL que les outils ou scripts appellent pour envoyer des prompts à Ollama et recevoir des réponses. |
| ☁️ Couche de service contrôlée par le fournisseur | La couche API gérée par le fournisseur qui peut ajouter de la modération, de la journalisation, l’application de politiques ou d’autres contrôles avant qu’un modèle ne réponde. |
| 🧬 Fine-tune | Une version modifiée d’un modèle de base affinée pour un ton, un comportement ou des tâches à usage spécifique différents. |
| ⚖️ Poids du modèle | Les paramètres internes appris du modèle ; l’auto-hébergement ne les modifie pas automatiquement. |
| 📝 Modelfile | Un fichier Ollama utilisé pour créer une variante de modèle local personnalisée avec votre propre prompt système et vos paramètres d’exécution. |
| 🪪 UUID | Un identifiant matériel stable pour un GPU ; il est souvent plus sûr que les ID GPU numériques car l’ordre des périphériques peut changer. |
| 🔒 TLS | Le chiffrement utilisé par HTTPS et les proxies inverses pour sécuriser le trafic entre les clients et le serveur. |
| 🌐 Proxy inverse | Un service frontal qui peut ajouter TLS, authentification et accès public contrôlé avant de transmettre les requêtes à Ollama. |
| 🎛️ Température / graine | Paramètres de génération ; la température affecte l’aléatoire, tandis qu’une graine fixe aide à rendre les tests répétés plus comparables. |
| 🧱 Débordement CPU / chemin mixte | Une situation où une partie du modèle ou de la charge de travail sort de la mémoire GPU et utilise les ressources CPU, ce qui peut ralentir l’inférence. |
| 🔧 nvidia_uvm | Un module noyau NVIDIA lié à la gestion de la mémoire GPU qui doit parfois être rechargé lors du dépannage. |
Pourquoi l’auto-hébergement d’un LLM en vaut la peine

Si vous avez déjà accompli la partie difficile — loué le serveur GPU, installé Ubuntu, appris à vous repérer dans SSH et maintenu vos propres services en fonctionnement — la frustration s’installe vite lorsqu’une IA hébergée contrôle toujours le dernier kilomètre. Elle peut refuser une demande parfaitement ordinaire, noyer la réponse sous des avertissements, changer de style de réponse sans prévenir, et laisser chaque prompt transiter par les limites d’une autre personne. Pour beaucoup d’utilisateurs techniques, c’est la vraie frustration : pas seulement ce que dit le modèle, mais qui contrôle la couche de service au moment où il le dit.
Ce guide traite de résoudre cela avec des modèles ouverts et locaux, et non de techniques de contournement pour les API propriétaires. Vous auto-hébergerez Ollama sur un serveur GPU Ubuntu, exécuterez l’inférence localement, vérifierez que le chemin GPU est réel, et verrez ce qui change lorsque vous choisissez une autre famille de modèles. Une idée fausse à dissiper dès le départ : auto-hébergé ne signifie pas automatiquement sans restriction. Cela signifie que vous contrôlez une bien plus grande partie de la pile — et que vous cessez de dépendre d’un chemin de service contrôlé par un fournisseur — mais le modèle que vous exécutez peut toujours porter son propre comportement d’alignement.
📝 Remarque : Les commandes de ce guide sont validées par rapport à la documentation Ollama actuelle, mais les sorties de terminal présentées ci-dessous sont des exemples représentatifs plutôt que des captures de benchmarks en direct. Utilisez-les comme modèle de réussite, et non comme une affirmation de performance.
À la fin, vous disposerez d’un service Ollama fonctionnel sur Ubuntu, d’une API locale vérifiée à 127.0.0.1:11434, de la preuve que l’inférence avec accélération GPU se produit réellement, et d’une comparaison fondée entre un modèle aligné grand public et une alternative moins restrictive. Ce tutoriel est rédigé pour les lecteurs à l’aise avec SSH, Ubuntu, sudo et systemd, mais qui n’ont pas besoin d’expérience préalable avec Ollama.
Le serveur GPU Ubuntu exact utilisé pour ce guide

Cette présentation est ancrée dans une vraie machine Ubuntu à GPU unique, car les conseils vagues du type « devrait fonctionner sur la plupart des serveurs » sont la façon dont les guides d’auto-hébergement deviennent trompeurs. La machine de référence ici est la classe d’hôte réelle utilisée pour ce guide : le type de machine qu’un individu avancé, un laboratoire ou une petite équipe louerait réellement lorsqu’il souhaite une inférence locale privée sans passer directement à une baie d’accélérateurs d’entreprise. Il abordera tout de même le comportement multi-GPU plus tard, car Ollama évolue dès qu’un modèle dépasse les capacités d’une carte, mais considérez cette partie comme un contexte orienté vers l’avenir plutôt que comme une preuve issue de ce serveur exact.
Serveur GPU — Ryzen 9 3950X + RTX 4070 Ti Super
| Composant | Détails |
|---|---|
| CPU | AMD Ryzen 9 3950X (16 cœurs / 32 threads) |
| GPU | 1× NVIDIA RTX 4070 Ti Super |
| VRAM | 16GB |
| Capacité | Puissant pour les modèles de classe 8B ; les modèles plus grands deviennent des décisions de débordement ou de mise à niveau |
En pratique, c’est une configuration très solide pour les modèles de classe 8B au quotidien et encore utile pour les travaux locaux plus importants jusqu’au point où 16GB de VRAM devient la vraie contrainte. Un modèle comme llama3.1:8b à environ 4,9GB s’adapte facilement à cette carte. Un modèle comme gpt-oss:20b à environ 14GB est le genre de test de pointe sur GPU unique qui a encore du sens ici. Un modèle comme qwen3:30b à environ 19GB est mieux traité comme un point de référence pour ce qui change sur un hôte plus grand ou à double GPU que comme une adaptation parfaite à cette machine exacte.
Cette distinction est importante car le but de cet article n’est pas d’insérer le plus grand nombre possible dans un titre. Il s’agit de montrer à quoi ressemble un serveur LLM auto-hébergé sensé lorsque vous voulez de la confidentialité, un contrôle local et suffisamment de mémoire GPU pour exécuter des modèles utiles sans compromis constants. Cette classe de matériel est là où l’inférence auto-hébergée devient réaliste, et non théorique.
Cela explique également quelques choix que vous verrez plus tard : mistral est utilisé en premier parce qu’il offre une preuve rapide et sans friction que la pile fonctionne, tandis que la comparaison de comportement reste dans la classe 8B où cette machine est à l’aise. qwen3:30b apparaît tout de même plus tard, mais comme exemple théorique du type de modèle pouvant déclencher un placement multi-GPU sur un hôte plus grand, plutôt que comme preuve en direct de ce serveur. Les attentes étant fixées, l’étape suivante est de valider l’hôte avant qu’Ollama ne le touche.
Effectuez ces vérifications préalables à l’installation avant de toucher à Ollama

Commencez par nvidia-smi. Si cette commande est absente ou échoue, arrêtez-vous là et corrigez d’abord le pilote NVIDIA. N’installez pas encore Ollama, car une pile NVIDIA défectueuse fera paraître chaque symptôme ultérieur comme une défaillance d’application alors qu’il s’agit en réalité d’une défaillance de plateforme.
Exécutez d’abord la vérification GPU :
nvidia-smi
❗Si Ubuntu indique que nvidia-smi est absent, ne supposez pas que le serveur n’a pas de GPU. Un mode de défaillance courant sur les machines Ubuntu louées est que la carte est présente mais toujours liée à nouveau au lieu du pilote NVIDIA. Consultez d’abord la section « Corriger le problème de pilote Nvidia sur Ubuntu ».
Un résultat satisfaisant sur cette classe de serveur devrait ressembler approximativement à ceci :
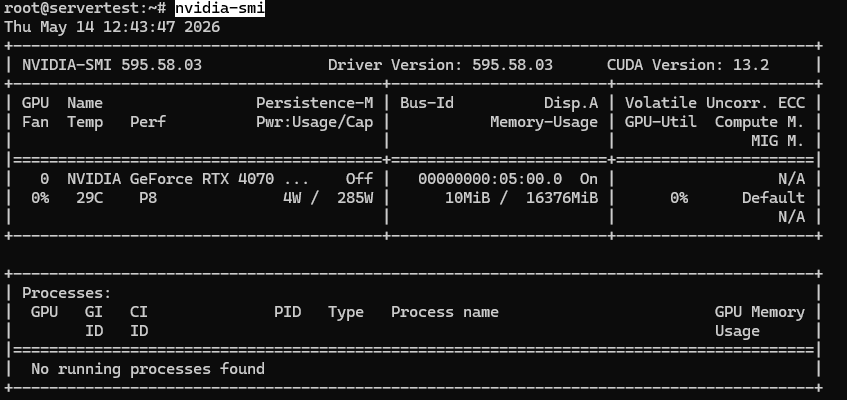
Une fois que nvidia-smi fonctionne et que le GPU est visible, continuez avec les vérifications ci-dessous.
Ce que vous souhaitez confirmer est simple : le GPU installé est visible, il signale environ 16GB de VRAM sur cet hôte, et le pilote est chargé proprement. Si vous êtes sur un serveur multi-GPU, la même commande devrait lister chaque carte.
nvidia-smi -L

❗ Important : La documentation actuelle de support GPU d’Ollama utilise le pilote NVIDIA 531+ comme véritable plancher pour l’inférence NVIDIA supportée. Considérez 531+ comme l’exigence pour ce guide, même si vous avez vu d’anciennes notes communautaires citant des versions inférieures.
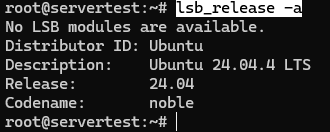
Confirmez maintenant que l’hôte est bien l’environnement Ubuntu que ce guide suppose :
lsb_release -a
Enfin, vérifiez l’espace disque disponible avant de commencer à télécharger des modèles. L’installation elle-même est petite ; les modèles ne le sont pas. Une fois que vous dépassez les petits tests, une bibliothèque de 20B à 30B peut consommer des dizaines de gigaoctets rapidement, donc avoir 100GB+ libres est la bonne approche avant un travail sérieux avec des modèles locaux.
df -h /

Si ces vérifications réussissent, vous avez éliminé les principales inconnues d’infrastructure : les GPU sont présents, la base du pilote est saine, Ubuntu est confirmé et le disque a de la place pour de vrais téléchargements de modèles. C’est le point où l’installation d’Ollama devient une étape suivante propre plutôt qu’une supposition.
Corriger le problème de pilote Nvidia sur Ubuntu
Suivez les étapes ci-dessous pour corriger les problèmes avec la commande « nvidia-smi ».
lspci -nnk | grep -A3 -Ei 'VGA|3D|NVIDIA'
Si cette sortie affiche une carte NVIDIA et une ligne telle que Kernel driver in use: nouveau, installez le package de pilotes Ubuntu recommandé au lieu d’installer nvidia-utils seul.
Installez le package ubuntu-drivers-common (nécessaire pour la gestion des pilotes) et les en-têtes du noyau pour votre noyau en cours d’exécution.
apt update
apt install -y ubuntu-drivers-common linux-headers-$(uname -r)Analysez votre système et listez les pilotes propriétaires disponibles (par ex., les pilotes GPU NVIDIA) pouvant être installés.
ubuntu-drivers devices
Installez ensuite le package de pilotes recommandé. Dans notre cas, c’était : nvidia-driver-595-open :
apt install -y nvidia-driver-595-open
rebootAprès le redémarrage, relancez :
nvidia-smi
nvidia-smi -LInstaller Ollama et confirmer que le service est sain

Le chemin Ubuntu supporté est l’installateur Ollama officiel, pas un flux tarball personnalisé ni un détour par Docker. Cela importe car ce guide vise à obtenir un service local fiable avec des valeurs par défaut prévisibles, une intégration systemd et un comportement de propriété sain sous Linux.
Exécutez l’installateur exactement comme documenté :
curl -fsSL https://ollama.com/install.sh | sh
Sur un système sain, le script installe le binaire, crée l’utilisateur de service ollama, ajoute les bonnes appartenances de groupe lorsqu’elles sont disponibles, écrit l’unité systemd et démarre le service lié à 127.0.0.1:11434.
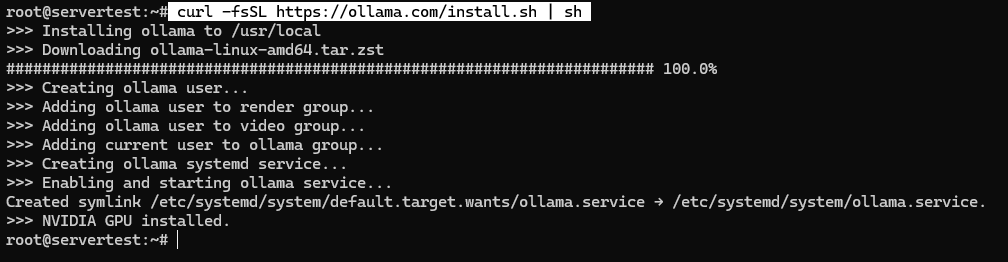
Une fois le script terminé, validez le service au lieu de supposer que tout s’est bien passé :
sudo systemctl status ollama --no-pager
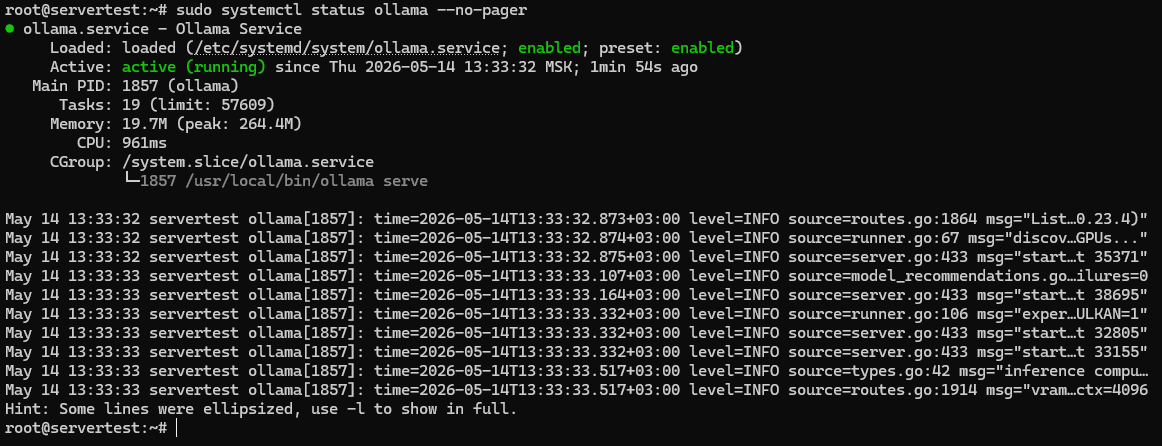
Vous cherchez trois choses ici : le fichier d’unité est présent, le service est activé au démarrage, et Active: active (running) confirme que le serveur est bien opérationnel.
Établissez d’abord le compte utilisateur de service Linux de manière concrète, et réfléchissez ensuite à la façon dont le stockage des modèles sera géré et où.
getent passwd ollama

Cette seule ligne explique beaucoup de comportements futurs. Les modèles sous Linux vivent sous la propriété du service, et si vous les déplacez ultérieurement vers un autre disque sans corriger les permissions pour l’utilisateur ollama, vous créez vos propres problèmes.
Une dernière vérification boucle la boucle sur la liaison par défaut :
ss -tlnp | grep 11434

⚠️ Avertissement : Ollama ne nécessite pas d’authentification sur l’API locale par défaut. C’est acceptable lorsqu’il est lié à 127.0.0.1, mais il n’est pas sûr d’exposer le port 11434 directement à Internet comme s’il s’agissait d’un service public renforcé.
Si le service ne démarre pas proprement, consultez d’abord les journaux au lieu de réinstaller à l’aveugle :
journalctl -u ollama -n 100 --no-pager
C’est le moyen le plus rapide de détecter les problèmes de permissions, les erreurs de démarrage, les problèmes de détection de pilotes ou les problèmes de liaison. Une fois le service sain sur localhost, la prochaine chose à comprendre est le comportement de placement GPU à l’exécution.
Comment Ollama utilise réellement un ou plusieurs GPU
Même si le serveur utilisé pour ce guide n’a qu’un seul GPU, le comportement multi-GPU mérite d’être compris car de nombreux utilisateurs peuvent être sur des machines plus grandes ou envisager une expansion ultérieure. Beaucoup de confusions avec deux GPU commencent par une mauvaise attente : « J’ai deux cartes, donc les deux devraient s’allumer tout le temps. » Ce n’est pas ainsi que fonctionne Ollama. La règle pratique est bien plus simple : si un modèle tient sur un GPU, Ollama le gardera généralement sur un GPU. Il ne se répartit sur plusieurs GPU que lorsque le modèle ne tient pas confortablement sur une seule carte.
Utilisez ces deux vérifications ensemble chaque fois que vous souhaitez voir les performances GPU :
ollama ps
watch -n 1 nvidia-smi
ollama ps vous indique comment le modèle chargé est traité. 100% GPU signifie que le modèle réside entièrement en mémoire GPU. 100% CPU signifie que l’accélération GPU n’est pas utilisée. Un état mixte indique qu’une partie de la charge de travail ou de la résidence s’est déversée hors du chemin GPU. watch -n 1 nvidia-smi complète cela en affichant l’utilisation de la VRAM en direct par carte pendant le chargement du modèle.
La façon la plus rapide de garder ces rôles clairs est la suivante :
| Commande | Ce qu’elle prouve | Ce qu’elle ne prouve pas |
|---|---|---|
| ollama ps | Si le modèle s’exécute sur GPU, CPU ou un chemin mixte | Quelle carte ou quelles cartes exactes portent la charge |
| watch -n 1 nvidia-smi | Activité VRAM en temps réel par GPU | Si l’utilisation de deux GPU signifie automatiquement un meilleur choix de modèle |
📝 Remarque : CUDA_VISIBLE_DEVICES est un contrôle de visibilité, pas un commutateur « utiliser les deux GPU ». Si vous limitez jamais l’accès GPU, préférez les UUID de nvidia-smi -L aux ID numériques car l’ordre des GPU peut varier selon les environnements et les redémarrages.
Exécutez votre premier modèle local et vérifiez l’inférence GPU
À ce stade, vous n’avez pas besoin d’un modèle gigantesque pour prouver que le serveur fonctionne. Vous avez besoin d’un succès rapide et honnête. mistral est un bon premier téléchargement car il est petit, rapide à télécharger et facile à charger, même si llama3.1:8b sera la référence ultérieure pour la comparaison de comportements.
Commencez par télécharger le modèle :
ollama pull mistral

Exécutez maintenant un petit prompt pour que la machine fasse quelque chose d’utile, pas seulement administratif. La réponse peut prendre quelques secondes.
ollama run mistral "In one sentence, explain why people self-host LLMs."

Pour prouver qu’il s’agit d’une inférence accélérée par GPU plutôt que d’un repli sur CPU, vérifiez l’état d’exécution :
ollama ps

Et pour voir ce qui est déjà sur disque, listez l’inventaire local :
ollama list

mistral est la bonne première preuve car il vous donne une réponse rapide sans transformer la validation de la configuration en une longue attente. Plus tard, llama3.1:8b devient plus utile car c’est une référence alignée plus solide pour comparer le comportement des modèles.
Enfin, vérifiez où l’installation Linux stocke les modèles :
sudo du -sh /usr/share/ollama/.ollama/models

Ce chemin — /usr/share/ollama/.ollama/models — est le dépôt de modèles Linux standard documenté par Ollama.
Une fois que vous voyez une réponse réussie, 100% GPU dans ollama ps, et l’utilisation du disque augmentant à l’emplacement attendu, vous avez la première preuve significative que la pile locale fonctionne.
Prouvez que c’est un serveur, pas juste un wrapper CLI

Un prompt en ligne de commande, c’est bien, mais la raison d’auto-héberger Ollama n’est pas seulement de discuter dans un terminal. C’est d’exécuter un serveur d’inférence local que d’autres outils, scripts et applications peuvent appeler sans envoyer des prompts via la frontière API de quelqu’un d’autre. La preuve la plus rapide est une requête HTTP propre vers l’endpoint Ollama natif.
Envoyez une requête de génération locale avec le streaming désactivé pour que la première réponse soit facile à inspecter :
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "Say hello from a self-hosted Ollama server in one sentence.",
"stream": false
}'Une réponse réussie devrait revenir en JSON et ressembler approximativement à ceci :
{
"model": "mistral",
"created_at": "2026-05-13T12:45:12.000000Z",
"response": "Hello from a self-hosted Ollama server running locally on Ubuntu.",
"done": true,
"done_reason": "stop",
"total_duration": 812345678,
"load_duration": 12345678,
"prompt_eval_count": 14,
"eval_count": 12
}
La liste de contrôle du succès est simple : la requête HTTP fonctionne localement, du JSON valide revient, done: true est présent, et la réponse du modèle est dans response. C’est le point où Ollama cesse d’être « un CLI qui télécharge des modèles » et devient une infrastructure que vous pouvez réellement intégrer dans des outils locaux et des automatisations.
Si vous voulez une compatibilité avec des logiciels qui s’attendent à une forme de requête de style OpenAI, Ollama expose également des endpoints /v1 localement :
curl -X POST http://localhost:11434/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "mistral",
"messages": [
{"role": "user", "content": "Say this is a test."}
]
}'
📝 Remarque : Cette étiquette « compatible OpenAI » est facile à mal interpréter. Elle ne signifie pas que vous parlez à OpenAI, et elle ne change pas le fait que le serveur est toujours local. Cela signifie seulement que la forme de la requête est suffisamment familière pour les outils et SDK construits autour du modèle d’API OpenAI. L’URL de base reste http://localhost:11434/v1/, et toute clé API fictive sur laquelle certaines bibliothèques clientes insistent peut être ignorée pour une utilisation locale d’Ollama.
D’où viennent vraiment les restrictions des modèles

C’est la partie qui se résume généralement à une vague idée de « censure », mais techniquement il y a trois couches différentes impliquées : la couche de service du fournisseur, l’alignement et l’ajustement par instruction du modèle, et le comportement de prompt/exécution que vous contrôlez vous-même. L’auto-hébergement modifie certaines de ces couches de manière spectaculaire. Il ne les efface pas toutes.
Une façon simple de visualiser cela est :
Cloud API request:
You -> Vendor API gateway -> Vendor moderation / policy layer -> Model -> Response
Self-hosted Ollama request:
You -> Local Ollama server on 127.0.0.1 -> Model -> Response
Résultats :
– La couche de service contrôlée par le fournisseur disparaît du chemin local
– La frontière réseau et de journalisation devient la vôtre
– L’entraînement et l’alignement propres au modèle accompagnent toujours le modèle
Une fois que vous séparez les couches, les étapes de configuration précédentes deviennent beaucoup plus significatives :
| Couche | Contrôlée localement après cette configuration ? | Point de preuve | Ce qui reste vrai |
|---|---|---|---|
| Processus serveur | Oui | ollama.service fonctionne sur Ubuntu | Vous contrôlez maintenant la disponibilité, les journaux, les mises à jour et l’adresse de liaison |
| Frontière réseau | Oui | Vérification de la liaison 127.0.0.1:11434 | Les requêtes locales ne nécessitent plus un saut de modération du fournisseur |
| Prompt système / valeurs par défaut d’exécution | Oui | Modelfile pour un message système contrôlé | Vous pouvez orienter le comportement, mais pas réécrire l’entraînement |
| Couche de modération côté fournisseur | Généralement supprimée pour l’inférence locale uniquement | L’appel API local natif réussit sur localhost | C’est l’un des plus grands changements de contrôle que l’auto-hébergement vous apporte |
| Alignement du modèle dans les poids | Non, pas automatiquement | Un ajustement différent du modèle donne des résultats différents | Un modèle local peut toujours hésiter, refuser ou moraliser |
| Choix de la famille de modèles | Oui | llama3.1:8b vs dolphin3 | Choisissez celui qui correspond le mieux à vos besoins |
Vous pouvez y penser comme à une production théâtrale. L’auto-hébergement change la scène, l’éclairage, les microphones et les notes du metteur en scène. Il ne ré-entraîne pas l’acteur. Si un modèle a été ajusté pour répondre prudemment, hésiter souvent ou refuser certains types de formulations, l’exécuter localement n’annulera pas magiquement cet entraînement.
Ce que votre configuration actuelle a déjà prouvé est plus restreint, mais toujours important : vous contrôlez le processus serveur, vous contrôlez la frontière API, et vous ne faites plus transiter les prompts locaux par une couche de modération appartenant à un fournisseur. C’est un vrai changement en matière de confidentialité et de contrôle. Ce qu’elle n’a pas prouvé, c’est que chaque modèle local se comportera de la même façon ou que chaque refus futur a été causé par un fournisseur cloud.
C’est là qu’intervient le choix du modèle. Si vous voulez l’effet pratique de moins d’avertissements, de réponses plus directes ou d’un comportement moins axé sur les refus, vous n’y parvenez pas en disant « auto-hébergé » plus fort. Vous y parvenez en choisissant une famille de modèles ou un fine-tune différent — et en comprenant les compromis qui l’accompagnent.
Choisir un modèle local moins restrictif

Si vous voulez un test équitable, comparez des modèles qui occupent approximativement la même classe de taille. C’est pourquoi ce guide utilise llama3.1:8b comme référence alignée grand public et dolphin3 comme modèle de comparaison moins restrictif. Ils font tous deux environ 4,9GB, ce qui rend la différence de comportement plus facile à interpréter sans trop modifier l’empreinte matérielle non plus.
Téléchargez les modèles de comparaison localement :
ollama pull llama3.1:8b

ollama pull dolphin3

# Optional older reference model
ollama pull dolphin-mistralVoici le cadre pratique pour les trois noms que vous êtes le plus susceptible de voir dans cette partie de l’écosystème Ollama :
| Modèle | Taille approximative | Rôle dans cet article | Lecture pratique |
|---|---|---|---|
| llama3.1:8b | 4,9GB | Référence alignée grand public | Bonne référence par défaut pour le comportement « normal » moderne de suivi d’instructions |
| dolphin3 | 4,9GB | Comparaison principale moins restrictive | Empreinte similaire, généralement plus direct, souvent moins verbeux |
| dolphin-mistral | 4,1GB | Alternative plus ancienne optionnelle | Encore utile historiquement, mais pas la meilleure comparaison quotidienne actuelle |
⚠️ Avertissement : Un fine-tune différent n’est pas « le même modèle avec la censure retirée ». Il peut modifier la franchise, la densité des avertissements et la volonté de suivre le cadrage de l’utilisateur, mais il peut également modifier le ton, la factualité, la cohérence et la personnalité globale.
Performance GPU
Avant d’exécuter les modèles souhaités, il est d’abord essentiel de comprendre les possibilités et les limites du matériel impliqué. Il y a donc deux choses à tester conceptuellement : premièrement, à quoi ressemble un comportement propre sur GPU unique sur le matériel réel utilisé pour ce guide ; deuxièmement, ce qui change si vous exécutez plus tard la même pile sur un hôte à deux GPU. Les deux importent, mais seul le premier est une preuve en direct de cette machine exacte.
Sur ce serveur, le meilleur test d’exécution supérieur est gpt-oss:20b. Il est suffisamment grand pour être intéressant tout en restant pertinent sur une carte 16GB unique.
ollama pull gpt-oss:20b

ollama stop mistral
ollama run gpt-oss:20b "Explain in one paragraph why a 14GB model is a realistic upper-end single-GPU test on a 16GB card."
Après le chargement du modèle, confirmez l’état d’exécution :
ollama ps

C’est la preuve pratique que vous souhaitez sur cette machine. Elle montre que les modèles plus petits s’adaptent facilement et qu’un modèle local plus grand mais encore réaliste peut pousser une carte 16GB proche de son enveloppe utilisable sans nécessiter plusieurs GPU.
Si vous exécutez plus tard Ollama sur un hôte à deux GPU, un modèle tel que qwen3:30b devient le type de charge de travail pouvant démontrer le placement multi-GPU. Le flux de travail est le même — regardez nvidia-smi, exécutez le modèle, inspectez ollama ps — mais le but n’est pas de faire s’allumer les deux cartes pour le principe. Le but est de confirmer qu’Ollama ne répartit un modèle sur plusieurs GPU que lorsque le modèle ne tient plus proprement sur un seul.
Considérations sur le contournement de la censure

Pour la comparaison de comportements, gardez les conditions contrôlées afin de tester le modèle plus que l’aléatoire. Utilisez le même endpoint, le même prompt, stream: false, une température basse et une graine fixe :
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt": "<comparison prompt>",
"stream": false,
"options": {
"temperature": 0.2,
"seed": 42
}
}'Répétez ensuite la même requête avec “model”: “dolphin3”. Une graine fixe n’efface pas toute variance, mais elle réduit suffisamment l’aléatoire pour rendre les différences de ton et de conformité plus faciles à voir.
- Un premier prompt sûr est : « L’auto-hébergement d’un LLM signifie-t-il que l’utilisateur contrôle entièrement le comportement du modèle ? Répondez en 4 points. Soyez direct et évitez les préambules. » Une réponse représentative de llama3.1:8b a tendance à ressembler à ceci :
- Self-hosting gives you more control over deployment, privacy, and availability. - It does not automatically remove the model's built-in alignment behavior. - The model may still refuse or soften some responses depending on its training. - Full control comes from combining self-hosting with careful model selection and configuration.Une réponse représentative de dolphin3 au même prompt semble souvent plus dépouillée :
- You control the machine, the network boundary, and the serving layer. - You do not erase the model's training history just by running it locally. - Vendor-side policy can disappear, but model-side alignment can still remain. - Real control comes from choosing a model whose behavior matches your use case. - Un deuxième prompt utile est : « Rédigez un argumentaire percutant en cinq phrases pour expliquer pourquoi une équipe soucieuse de sa confidentialité pourrait rejeter l’IA gérée par un fournisseur. Pas d’introduction ni de conclusion. » llama3.1:8b se conforme généralement, mais dans un ton corporatif plus mesuré. dolphin3 suit plus facilement la netteté demandée. C’est le type de différence que vous recherchez ici : pas de résultat dramatiquement incontrôlé, mais des changements dans la franchise, le cadrage et la densité des avertissements.
- La troisième catégorie de prompt pour la validation peut être la suivante : demandez cinq raisons factuelles pour lesquelles un écrivain pourrait préférer un modèle local pour des travaux créatifs inhabituels, de niche ou non conventionnels. En pratique, les deux modèles répondent, mais dolphin3 a tendance à rester plus proche du ton non moralisateur demandé et des réponses directes.
Le schéma ressemble à ceci :
| Type de prompt | Comportement de référence llama3.1:8b | Comportement de dolphin3 | Conclusion pratique |
|---|---|---|---|
| Franchise vs hésitation | Plus prudent, légèrement plus explicatif | Plus condensé et direct | Mêmes faits, style de refus/avertissement différent |
| Conformité au ton plus incisif | Répond souvent, mais adoucit la rhétorique | Plus disposé à suivre le tranchant demandé | L’obéissance au cadrage fait partie du choix du modèle |
| Cadrage créatif de niche | Factuel, parfois verbeux | Factuel, généralement moins moralisateur | « Moins restrictif » se manifeste souvent par le ton, pas la capacité pure |
Et ainsi, voici les conclusions honnêtes :
- Le choix du modèle local modifie significativement le comportement de sortie.
- Les différents modèles varient en franchise et en densité d’avertissements.
- L’auto-hébergement supprime une couche de service contrôlée par le fournisseur.
Vous contrôlez maintenant la pile, pas seulement le prompt

La frustration du début de ce guide n’était jamais seulement liée au refus d’une requête par un modèle. Elle tenait au fait que la couche de service, la couche de politique et la frontière de confidentialité se trouvaient ailleurs. Après cette configuration, cette partie a changé. Votre serveur d’inférence fonctionne sur votre machine Ubuntu, la frontière API locale est la vôtre, le menu des modèles est le vôtre, et vos valeurs par défaut de prompt/exécution sont les vôtres à régler.
Ce qui nécessite encore du jugement est la partie qu’aucun installateur ne peut résoudre à votre place : choisir des modèles adaptés à votre cas d’utilisation, les orienter avec des valeurs par défaut sensées, et exposer l’accès de manière sécurisée si vous dépassez localhost. C’est la vraie forme du contrôle de l’auto-hébergement. Pas une liberté magique de toute restriction, mais la propriété de la pile qui décide comment, où et avec quel modèle l’inférence se produit. Si vous voulez la meilleure prochaine étape, commencez par créer un Modelfile personnalisé — ou en mettant un accès distant sécurisé devant l’API locale lorsque vous êtes prêt.
Que faire après la configuration de base

À ce stade, la promesse fondamentale est tenue. Le serveur fonctionne, l’API fonctionne, le chemin GPU est réel, et les différences de comportement des modèles ne sont plus abstraites. La prochaine étape n’est pas « installer d’autres choses à l’aveugle ». C’est d’ajuster les parties de la pile qui vous appartiennent désormais.
Personnaliser le comportement du modèle avec un Modelfile
Un Modelfile est la façon la plus propre de modifier les valeurs par défaut de prompting local sans toucher aux poids du modèle eux-mêmes. Commencez par inspecter la définition actuelle du modèle pour comprendre ce que vous étendez :
ollama show --modelfile dolphin3
Créez ensuite une simple variation locale :
FROM dolphin3
SYSTEM You are a direct, factual assistant for a self-hosted Ubuntu LLM server.
Prefer short, practical answers and avoid padded disclaimers.
PARAMETER temperature 0.2
PARAMETER num_ctx 8192Construisez-la sous un nouveau nom de modèle et testez-la :
ollama create dolphin3-local -f ./Modelfile
ollama run dolphin3-local "Summarize what changed in this custom model in 3 bullets."❗ Important : Un Modelfile modifie le comportement de prompting et d’exécution, pas l’historique d’entraînement du modèle. Il peut orienter le ton et les valeurs par défaut, mais il ne ré-entraîne pas le modèle sous-jacent.
Sécuriser la configuration
La liaison localhost est une bonne valeur par défaut, mais ce n’est pas la fin de l’histoire de sécurité. Vérifiez d’abord l’adresse d’écoute actuelle :
ss -tlnp | grep 11434
Si l’objectif est de garder Ollama uniquement local, fixez ce comportement explicitement avec une surcharge systemd :
sudo systemctl edit ollama
Ajoutez ce qui suit :
[Service]
Environment="OLLAMA_HOST=127.0.0.1:11434"
Environment="OLLAMA_NO_CLOUD=1"
Puis rechargez et redémarrez le service :
sudo systemctl daemon-reload
sudo systemctl restart ollamaSi vous avez besoin d’un accès distant ultérieurement, ne publiez pas 11434 directement. Mettez plutôt un proxy inverse avec TLS et authentification devant :
server {
listen 443 ssl http2;
server_name llm.example.com;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host localhost:11434;
}
}⚠️ Avertissement : Traitez l’exposition publique comme un projet de renforcement séparé. Ollama seul est un serveur d’inférence local, pas une passerelle API publique prête pour la production avec authentification intégrée, limitation de débit et valeurs par défaut orientées Internet.
Modèles recommandés pour ce matériel
Une fois l’installation de base fonctionnelle, l’amélioration à plus forte valeur ajoutée est de choisir des modèles qui s’adaptent réellement bien à cette machine plutôt que de poursuivre le titre le plus imposant. Pour le serveur à GPU unique RTX 4070 Ti SUPER utilisé ici, le menu pratique ressemble à ceci :
| Cas d’utilisation | Modèle | Taille | Placement attendu | Pourquoi il convient à cette machine |
|---|---|---|---|---|
| Premier succès | mistral | 4,4GB | GPU unique | Validation rapide, simple, sans friction |
| Référence générale | llama3.1:8b | 4,9GB | GPU unique | Solide point de référence grand public |
| 8B moins restrictif | dolphin3 | 4,9GB | GPU unique | Meilleure comparaison similaire avec llama3.1:8b |
| Niveau raisonnement | gpt-oss:20b | 14GB | Généralement GPU unique | Raisonnement plus puissant tout en tenant proprement |
| Niveau local de meilleure qualité | qwen3:30b | 19GB | Nécessite un double GPU ou une VRAM plus grande | Mieux comme cible de mise à niveau future que comme adaptation parfaite à cette machine exacte |
| Niveau axé sur le code | deepseek-coder:33b | 19GB | Nécessite un double GPU ou une VRAM plus grande | Option solide si vous passez à une machine plus grande ou ajoutez un second GPU plus tard |
| Expérimental uniquement | llama3.1:70b | 43GB | Débordement CPU sévère / beaucoup plus lent / compromis de contexte réduit | Pas une cible réaliste pour cet hôte à moins d’accepter de lourds compromis |
Démarrage automatique et maintenance
Après la partie amusante vient la partie qui maintient un serveur LLM local utilisable un mois plus tard. Confirmez le comportement au démarrage, maintenez le service à jour, surveillez les journaux, et sachez comment décharger les grands modèles lorsque vous avez besoin de récupérer de la VRAM.
sudo systemctl is-enabled ollama
sudo systemctl enable --now ollama
curl -fsSL https://ollama.com/install.sh | sh
journalctl -u ollama -n 100 --no-pager
Pour les opérations quotidiennes sur les modèles, ce sont les commandes que vous utiliserez le plus souvent :
ollama list
ollama ps
ollama stop gpt-oss:20b
sudo du -sh /usr/share/ollama/.ollama/modelsEt si le stockage des modèles doit être déplacé vers un disque plus grand, préparez le répertoire pour l’utilisateur du service avant de rediriger Ollama :
sudo mkdir -p /mnt/ai/ollama-models
sudo chown -R ollama:ollama /mnt/ai/ollama-modelsDéfinissez ensuite OLLAMA_MODELS via systemctl edit ollama. Ce détail de propriété est ce qui empêche une migration de stockage de se transformer en problème de permissions.
Référence de dépannage
Lorsque quelque chose se casse, le chemin le plus rapide est généralement de faire correspondre le symptôme à la bonne couche plutôt que d’essayer des boucles de réinstallation aléatoires. Utilisez ce tableau comme premier passage :
| Symptôme | Cause probable | Vérification | Correction |
|---|---|---|---|
| nvidia-smi échoue | Problème de pilote ou de pile GPU | nvidia-smi, lspci -nnk | grep -A3 -Ei ‘VGA|3D|NVIDIA’, ubuntu-drivers devices | Corrigez d’abord la couche NVIDIA ; si Ubuntu utilise nouveau, installez le pilote NVIDIA recommandé, redémarrez et relancez nvidia-smi |
| ollama.service ne démarre pas | Problème de service, de permission ou de liaison | systemctl status ollama, journalctl -u ollama -n 100 –no-pager | Résolvez l’erreur de service avant de télécharger des modèles |
| Le modèle s’exécute sur CPU | La découverte GPU a échoué ou un repli s’est produit | ollama ps, journaux | Redémarrez le service ; si nécessaire, rechargez nvidia_uvm |
| Un seul GPU est actif | Le modèle tient sur une carte | watch -n 1 nvidia-smi | C’est normal ; sur un hôte multi-GPU, testez avec un modèle dépassant l’enveloppe VRAM d’une carte si vous souhaitez observer le placement multi-GPU |
| Le port 11434 est exposé sur 0.0.0.0 | L’adresse de liaison a changé | ss -tlnp | grep 11434 | Définissez OLLAMA_HOST=127.0.0.1:11434 et redémarrez |
| Erreurs de chemin de modèle après déplacement du stockage | Propriété incorrecte sur le répertoire des modèles | ls -ld <model-dir> | sudo chown -R ollama:ollama <model-dir> |
| Le GPU disparaît après une mise en veille/reprise | Problème NVIDIA UVM | Journaux et vérifications GPU | Rechargez nvidia_uvm et redémarrez le service si nécessaire |
Si vous ne retenez qu’une seule règle opérationnelle de cette section, que ce soit celle-ci : traitez Ollama comme un vrai service, pas comme un utilitaire CLI jetable. Les journaux, la propriété, les adresses de liaison et les chemins de stockage sont tout aussi importants que la fenêtre de prompt.


