Русский
Русский English
English  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  Polski
Polski  Indonesia
Indonesia  中文 (中国)
中文 (中国) 





Использование команд сканирования в Redis в Linux
Redis, хранилище структур данных in-memory с открытым исходным кодом, известно своей скоростью и универсальностью в качестве базы данных ключ-значение. Одной из его мощных особенностей является возможность инкрементного итерационного просмотра наборов данных с помощью команд сканирования. Это особенно полезно при работе с большими массивами данных, так как позволяет эффективно извлекать данные, не перегружая сервер. Для пользователей выделенных серверов Linux использование команд сканирования в Redis может повысить производительность работы с данными, обеспечивая точную, оптимизированную по ресурсам обработку наборов данных. В этой статье мы рассмотрим, как эффективно использовать команды сканирования в Redis в среде Linux, предложим подробные примеры и лучшие практики для управления и получения данных в масштабе
Что такое команды сканирования?
Команды сканирования в Redis позволяют выполнять неблокируемый итерационный поиск по ключам, наборам, хэшам и отсортированным наборам. В отличие от команды KEYS, которая может быть опасна для больших наборов данных, поскольку возвращает все совпадающие ключи сразу, команды сканирования возвращают небольшое количество элементов за один раз. Это минимизирует влияние на производительность и позволяет выполнять инкрементную итерацию
Команды сканирования ключей
- SCAN: Итерация по ключам в пространстве ключей.
- SSCAN: Итерация по элементам в наборе.
- HSCAN: итерация по полям и значениям в хэше.
- ZSCAN: итерация по членам и оценкам в отсортированном множестве.
Основной синтаксис команд сканирования
Каждая команда сканирования имеет схожий синтаксис
- курсор: Целое число, обозначающее позицию, с которой нужно начать сканирование. Чтобы начать новое сканирование, используйте 0.
- MATCH pattern: (необязательно) Шаблон для фильтрации возвращаемых ключей. Поддерживаются шаблоны в стиле glob.
- COUNT count: (необязательно) Подсказка для Redis о том, сколько элементов возвращать в каждой итерации.
Установка Redis в Linux
Для CentOS/RHEL используйте
После установки запустите сервер Redis
Подключение к Redis
Откройте терминал и подключитесь к экземпляру Redis с помощью Redis CLI
Теперь вы можете выполнять команды Redis в CLI
Использование команды SCAN
Пример 1: Базовый SCAN
Чтобы получить все ключи в базе данных Redis, вы можете использовать команду
SCAN 0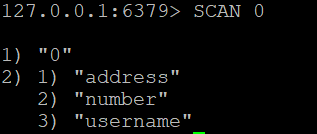
Эта команда вернет курсор и список ключей
Пример 2: Использование MATCH для фильтрации ключей
Если вы хотите найти ключи, соответствующие определенному шаблону, например ключи, начинающиеся с “user:”, вы можете использовать
Эта команда возвращает только те ключи, которые начинаются с “user:”
Пример 3: Указание COUNT
Чтобы указать, сколько ключей Redis должен возвращать в каждой итерации, вы можете указать count
Это позволит вернуть примерно 10 ключей. Обратите внимание, что реальное число может быть меньше этого
Пример 4: Итерация по всем ключам
Чтобы перебрать все ключи за несколько итераций, необходимо следить за возвращаемым курсором. Вот пример простого сценария оболочки:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Process the result as needed
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Update the cursor
if [[ "$cursor" == "0" ]]; then
break # Stop when the cursor is back to 0
fi
doneИспользование команды SSCAN
Команда SSCAN используется для перебора элементов в наборе. Ее синтаксис аналогичен синтаксису SCAN
Пример SSCAN
Шаг 1: Создание набора и добавление элементов
Давайте создадим набор под названием myset и добавим в него несколько элементов
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"Шаг 2: Использование команды SSCAN
Теперь, когда у нас есть набор с именем myset, мы можем использовать команду SSCAN для перебора его элементов
- Основная команда SSCAN:Предположим, у вас есть набор с именем “myset”. Чтобы просканировать его элементы
SSCAN myset 0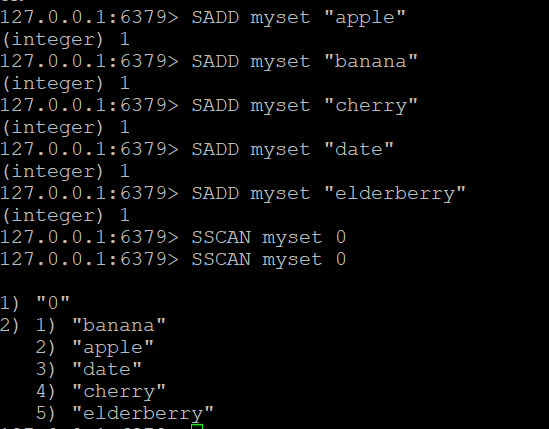
- Использование MATCH:Чтобы отфильтровать элементы набора на основе шаблона и добавить некоторые элементы, включающие слово “манго” и другие вариации:
SSCAN myset 0 MATCH mango:*
- Итерация по множеству:Вы можете использовать цикл для итерации по множеству:
#!/bin/bash
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor)
# Print the elements returned by SSCAN
echo "$result"
# Update the cursor for the next iteration
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Break the loop if cursor is back to 0
if [[ "$cursor" == "0" ]]; then
break
fi
doneЗапуск скрипта
- Сохраните скрипт под именем scan_myset.sh.
- Сделайте его исполняемым
- Запустите скрипт
./scan_myset.sh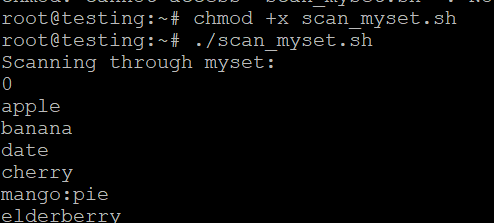
Использование команд HSCAN и ZSCAN
Команда HSCAN
Команда HSCAN выполняет итерацию по полям и значениям в хэше
Команда HSCAN используется для итерации полей и значений в хэше
Шаг 1: Создание хэша и добавление полей
- Создайте хэш с именем myhash и добавьте в него несколько полей:
Шаг 2: Используйте HSCAN для итерации по хэшу
- Используйте команду HSCAN для итерации по полям в myhash:
HSCAN myhash 0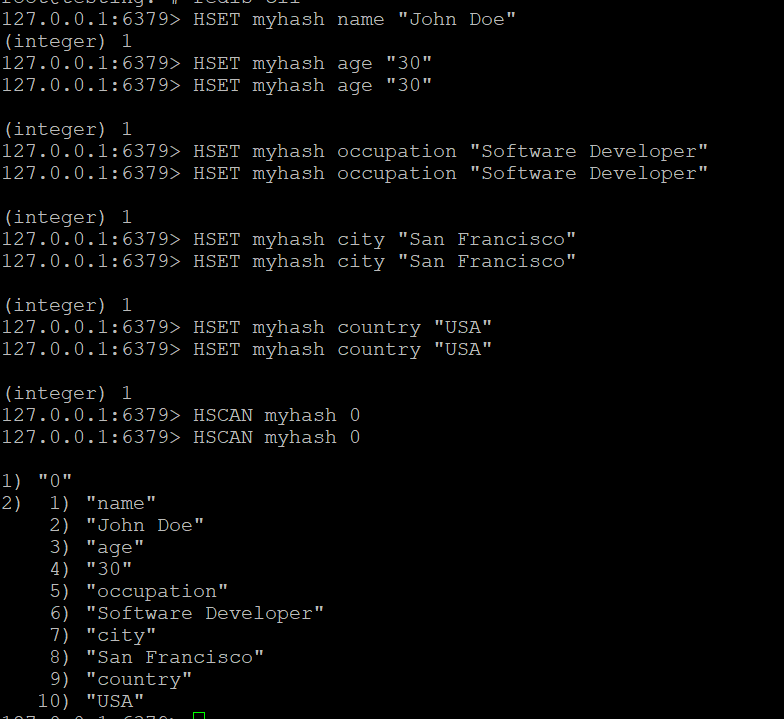
Команда ZSCAN
ZSCAN – это команда Redis, используемая для поэтапного перебора членов отсортированного набора. Она позволяет эффективно и неблокируемо извлекать члены набора вместе с их ассоциированными оценками. Эта команда особенно полезна при работе с большими отсортированными наборами, когда получение всех членов сразу может быть нецелесообразным. Команда ZSCAN выполняет итерацию по членам и оценкам в отсортированном наборе
Шаг 1: Создание отсортированного множества и добавление членов
Давайте создадим отсортированный набор mysortedset и добавим в него несколько членов с оценками
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"Основная команда ZSCAN:Чтобы начать сканирование отсортированного набора, используйте
ZSCAN mysortedset 0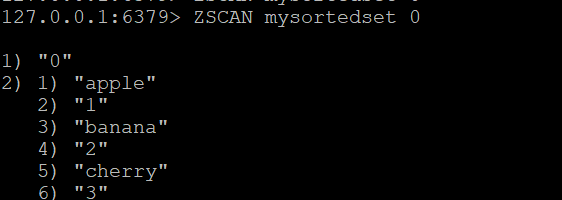
Шаг 2: Использование MATCH для фильтрации членов (необязательно)
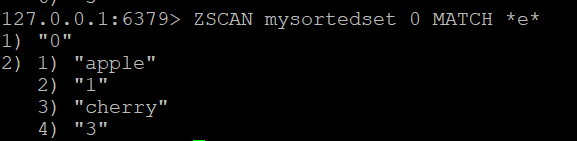
Если вы хотите отфильтровать члены, возвращаемые ZSCAN, вы можете использовать опцию MATCH. Например, чтобы найти членов, содержащих букву “e”, можно выполнить команду
ZSCAN mysortedset 0 MATCH *e*