 Indonesia
Indonesia English
English  Русский
Русский  Română
Română  Deutsch
Deutsch  Français
Français  Türkçe
Türkçe  Español
Español  Português
Português  Українська
Українська  български
български  中文 (中国)
中文 (中国) 




 untuk semua layanan hosting
untuk semua layanan hostingMenggunakan Perintah Redis Scan pada Linux: Panduan Lengkap
Redis adalah penyimpan struktur data in-memory open-source berkinerja tinggi yang banyak digunakan sebagai database key-value, cache, dan message broker. Di antara fitur-fiturnya yang paling powerful — namun sering kurang dimanfaatkan — adalah scan commands, yang memungkinkan Anda untuk melakukan iterasi secara bertahap melalui dataset besar tanpa memblokir server atau menurunkan performa.
Jika Anda menjalankan Redis di server berbasis Linux, menguasai scan commands sangat penting untuk membangun aplikasi yang scalable dan production-ready. Tidak seperti perintah KEYS yang berbahaya, yang mengambil semua kunci yang cocok dalam satu operasi blocking, scan commands mengembalikan data dalam batch kecil yang dapat dikelola — menjadikannya alat yang tepat untuk lingkungan apa pun yang menangani volume data signifikan.
Dalam panduan komprehensif ini, Anda akan mempelajari dengan tepat cara menggunakan SCAN, SSCAN, HSCAN, dan ZSCAN di Redis pada Linux, lengkap dengan contoh dunia nyata, script shell, dan best practices untuk deployment production.
Apa Itu Perintah Redis Scan?
Perintah scan Redis menyediakan mekanisme berbasis kursor yang tidak memblokir untuk melakukan iterasi pada kunci, set, hash, dan sorted set. Setiap perintah mengembalikan subset kecil elemen per panggilan bersama dengan nilai kursor, yang Anda gunakan untuk melanjutkan iterasi dalam panggilan berikutnya. Ketika kursor kembali ke 0, seluruh dataset telah ditraversi.
Pendekatan ini secara fundamental lebih aman dan lebih efisien daripada KEYS, yang memblokir seluruh server Redis sampai selesai memindai — masalah kritis di lingkungan produksi dengan jutaan kunci.
Empat Perintah Scan Inti
| Perintah | Tujuan |
|---|---|
SCAN | Melakukan iterasi pada kunci di seluruh keyspace |
SSCAN | Melakukan iterasi pada elemen dalam sebuah Set |
HSCAN | Melakukan iterasi pada field dan nilai dalam sebuah Hash |
ZSCAN | Melakukan iterasi pada anggota dan skor dalam sebuah Sorted Set |
Sintaks Dasar Perintah Scan
Keempat perintah scan berbagi struktur sintaks yang konsisten:
SCAN cursor [MATCH pattern] [COUNT count]
SSCAN key cursor [MATCH pattern] [COUNT count]
HSCAN key cursor [MATCH pattern] [COUNT count]
ZSCAN key cursor [MATCH pattern] [COUNT count]Parameter Dijelaskan
cursor— Sebuah integer yang mewakili posisi saat ini dalam iterasi. Selalu mulai dengan0untuk memulai scan baru. Redis mengembalikan cursor baru dengan setiap respons; gunakan di panggilan berikutnya untuk melanjutkan.MATCH pattern*(opsional)* — Memfilter hasil menggunakan pencocokan pola gaya glob (misalnya,user:*,*session*). Catatan: penyaringan terjadi *setelah* pengambilan, jadi kecocokan kepadatan rendah mungkin memerlukan banyak iterasi.COUNT count*(opsional)* — Sebuah petunjuk kepada Redis yang menyarankan berapa banyak elemen yang akan dikembalikan per iterasi. Ini bukan batas keras; Redis dapat mengembalikan lebih banyak atau lebih sedikit. Default adalah10.
Menginstal Redis di Linux
Sebelum menggunakan perintah scan, Anda perlu menginstal dan menjalankan Redis di server Linux Anda. Baik Anda berada di lingkungan produksi dengan lalu lintas tinggi atau mesin pengembangan, proses instalasi sangat mudah.
> Tip: Untuk beban kerja produksi yang memerlukan Redis dalam skala besar, pertimbangkan untuk menerapkan pada paket VPS Hosting atau Dedicated Server untuk memastikan Anda memiliki memori, CPU, dan sumber daya I/O yang dibutuhkan Redis.
Menginstal Redis di Debian/Ubuntu
sudo apt update
sudo apt install redis-server -yMenginstal Redis di CentOS/RHEL
sudo yum install redis -y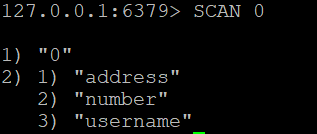
Memulai Layanan Redis
sudo systemctl start redis
sudo systemctl enable redisMemverifikasi Instalasi
sudo systemctl status redisAnda harus melihat active (running) dalam output. Sekarang hubungkan ke Redis CLI:
redis-cliSetelah berada di dalam CLI, uji koneksi:
127.0.0.1:6379> PING
PONGAnda siap untuk mulai menggunakan perintah scan.
Menggunakan Perintah SCAN
Perintah SCAN mengulangi semua kunci dalam keyspace Redis. Ini adalah pengganti tujuan umum untuk perintah KEYS di lingkungan produksi.
Contoh 1: SCAN Dasar
Untuk mulai memindai semua kunci dalam database, mulai dengan kursor 0:
SCAN 0Contoh output:
1) "14"
2) 1) "session:abc123"
2) "user:1001"
3) "product:55"Elemen pertama (14) adalah kursor berikutnya. Gunakan dalam panggilan SCAN Anda berikutnya. Ketika kursor yang dikembalikan adalah 0, iterasi lengkap selesai.
Contoh 2: Memfilter Kunci dengan MATCH
Untuk mengambil hanya kunci yang cocok dengan pola tertentu — misalnya, semua kunci dengan awalan user::
SCAN 0 MATCH user:*Ini mengembalikan hanya kunci yang namanya dimulai dengan user:. Terus ulangi sampai kursor mengembalikan 0 untuk memastikan Anda telah memindai seluruh keyspace.
Contoh 3: Mengontrol Ukuran Batch dengan COUNT
Untuk menyarankan agar Redis mengembalikan sekitar 100 kunci per iterasi:
SCAN 0 COUNT 100Ingat: COUNT adalah *petunjuk*, bukan jaminan. Redis dapat mengembalikan hasil sedikit lebih banyak atau lebih sedikit tergantung pada struktur data internal.
Contoh 4: Iterasi Keyspace Lengkap dengan Skrip Shell
Dalam skenario dunia nyata, Anda perlu melakukan loop melalui seluruh keyspace secara terprogram. Berikut adalah skrip Bash siap produksi yang mengulangi semua kunci yang cocok dengan pola:
#!/bin/bash
cursor=0
echo "Starting full keyspace scan..."
while true; do
# Execute SCAN and capture the result
result=$(redis-cli SCAN $cursor MATCH user:* COUNT 100)
# Extract the new cursor (first line of output)
cursor=$(echo "$result" | head -n 1)
# Extract and display the keys (remaining lines)
keys=$(echo "$result" | tail -n +2)
echo "Keys found:"
echo "$keys"
# Break the loop when cursor returns to 0
if [[ "$cursor" == "0" ]]; then
echo "Scan complete."
break
fi
doneUntuk menjalankan skrip ini:
chmod +x scan_keys.sh
./scan_keys.sh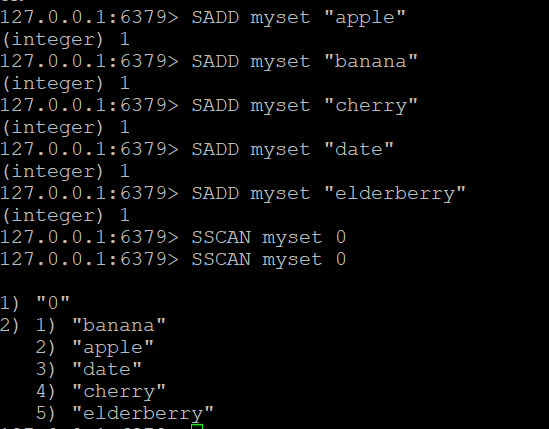

Menggunakan Perintah SSCAN
SSCAN digunakan untuk secara bertahap melakukan iterasi melalui anggota Redis Set. Ini mengikuti pola berbasis kursor yang sama dengan SCAN.
Langkah 1: Buat Set dan Tambahkan Anggota
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"
SADD myset "mango"
SADD myset "mango:tropical"
SADD myset "mango:dried"Langkah 2: SSCAN Dasar
Pindai semua elemen dalam myset mulai dari kursor 0:
SSCAN myset 0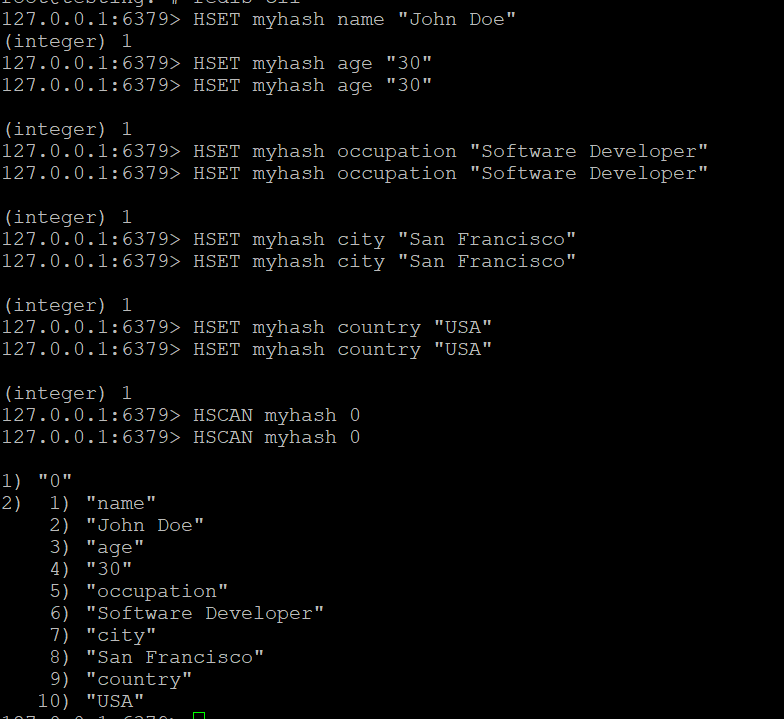
Langkah 3: Filter Elemen dengan MATCH
Untuk mengambil hanya elemen yang cocok dengan pola mango:*:
SSCAN myset 0 MATCH mango:*Langkah 4: Melakukan Iterasi Melalui Set dengan Shell Script
#!/bin/bash
cursor=0
echo "Scanning through myset:"
while true; do
# Scan the set
result=$(redis-cli SSCAN myset $cursor COUNT 10)
# Update cursor
cursor=$(echo "$result" | head -n 1)
# Print elements returned
elements=$(echo "$result" | tail -n +2)
echo "Elements: $elements"
# Stop when cursor returns to 0
if [[ "$cursor" == "0" ]]; then
echo "Set scan complete."
break
fi
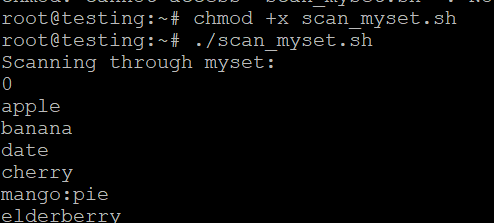
doneSimpan sebagai scan_myset.sh, buat dapat dieksekusi, dan jalankan:
chmod +x scan_myset.sh
./scan_myset.sh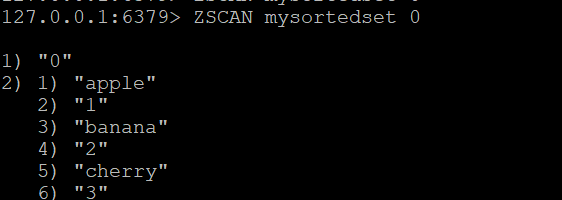
Menggunakan Perintah HSCAN
HSCAN melakukan iterasi melalui fields dan values dari Redis Hash. Ini sangat berguna ketika hash berisi ratusan atau ribuan fields dan Anda perlu memproses mereka tanpa memuat semuanya ke dalam memori sekaligus.
Langkah 1: Buat Hash dan Tambahkan Fields
HSET myhash name "John Doe"
HSET myhash age "30"
HSET myhash occupation "Software Developer"
HSET myhash city "San Francisco"
HSET myhash country "USA"
HSET myhash email "john@example.com"Langkah 2: HSCAN Dasar
HSCAN myhash 0Contoh output:
1) "0"
2) 1) "name"
2) "John Doe"
3) "age"
4) "30"
5) "occupation"
6) "Software Developer"
...Hasil dikembalikan sebagai pasangan field-value yang bergantian.
Langkah 3: Filter Hash Fields dengan MATCH
Untuk mengambil hanya fields yang namanya berisi "city" atau cocok dengan pola:
HSCAN myhash 0 MATCH *city*Langkah 4: Melakukan Iterasi Melalui Hash dengan Shell Script
#!/bin/bash
cursor=0
echo "Scanning hash: myhash"
while true; do
result=$(redis-cli HSCAN myhash $cursor COUNT 10)
cursor=$(echo "$result" | head -n 1)
fields=$(echo "$result" | tail -n +2)
echo "Fields and values:"
echo "$fields"
if [[ "$cursor" == "0" ]]; then
echo "Hash scan complete."
break
fi
doneMenggunakan Perintah ZSCAN
ZSCAN melakukan iterasi melalui anggota dan skor dari Redis Sorted Set. Sorted set biasanya digunakan untuk papan peringkat, antrian prioritas, dan data time-series — semua skenario di mana pemindaian koleksi besar secara efisien sangat penting.
Langkah 1: Buat Sorted Set dan Tambahkan Anggota
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"
ZADD mysortedset 4 "date"
ZADD mysortedset 5 "elderberry"Langkah 2: ZSCAN Dasar
ZSCAN mysortedset 0Contoh output:
1) "0"
2) 1) "apple"
2) "1"
3) "banana"
4) "2"
5) "cherry"
6) "3"Hasil dikembalikan sebagai pasangan anggota-skor yang bergantian.
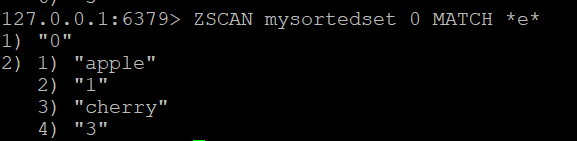
Langkah 3: Filter Anggota dengan MATCH
Untuk menemukan semua anggota yang namanya mengandung huruf "e":
ZSCAN mysortedset 0 MATCH *e*Langkah 4: Skrip Iterasi Sorted Set Lengkap
#!/bin/bash
cursor=0
echo "Scanning sorted set: mysortedset"
while true; do
result=$(redis-cli ZSCAN mysortedset $cursor COUNT 10)
cursor=$(echo "$result" | head -n 1)
members=$(echo "$result" | tail -n +2)
echo "Members and scores:"
echo "$members"
if [[ "$cursor" == "0" ]]; then
echo "Sorted set scan complete."
break
fi
donePerbandingan Perintah Scan: Referensi Cepat
| Fitur | `SCAN` | `SSCAN` | `HSCAN` | `ZSCAN` |
|---|---|---|---|---|
| Target | Semua kunci | Anggota set | Bidang/nilai hash | Anggota/skor set terurut |
| Memerlukan nama kunci | Tidak | Ya | Ya | Ya |
| Mendukung MATCH | Ya | Ya | Ya | Ya |
| Mendukung COUNT | Ya | Ya | Ya | Ya |
| Format output | Nama kunci | String anggota | Pasangan bidang-nilai | Pasangan anggota-skor |
| Pemblokiran | Tidak | Tidak | Tidak | Tidak |
Praktik Terbaik untuk Menggunakan Perintah Redis SCAN di Production
1. Selalu Gunakan SCAN Bukan KEYS di Production
Perintah KEYS adalah single-threaded dan memblokir semua operasi Redis lainnya hingga selesai. Pada database dengan jutaan kunci, ini dapat menyebabkan lonjakan latensi yang parah. Jangan pernah gunakan KEYS di production. SCAN adalah alternatif yang benar dan non-blocking.
2. Sesuaikan COUNT Berdasarkan Ukuran Dataset Anda
Untuk dataset kecil (< 1.000 kunci), default COUNT 10 sudah cukup. Untuk dataset besar, tingkatkan COUNT menjadi 100–1000 untuk mengurangi jumlah round trip sambil menjaga respons individual tetap dapat dikelola.
3. Jangan Andalkan MATCH Saja untuk Efisiensi
Filter MATCH diterapkan *setelah* Redis mengambil elemen secara internal. Jika pola Anda hanya cocok dengan sebagian kecil kunci, Redis masih memindai seluruh dataset secara internal. Gunakan konvensi penamaan kunci (misalnya, awalan konsisten) untuk membuat MATCH lebih efektif.
4. Proses Hasil dalam Batch
Jangan pernah mengumpulkan semua hasil scan di memori sebelum diproses. Sebaliknya, proses setiap batch segera setelah dikembalikan. Ini sangat penting pada server dengan memori terbatas.
5. Tangani Status Cursor dengan Hati-hati
Selalu inisialisasi cursor ke 0 dan perbarui dengan setiap respons. Jika aplikasi Anda crash di tengah-tengah scan, mulai ulang dari 0. Cursor Redis tidak persisten di seluruh restart server.
6. Uji Secara Menyeluruh di Development Terlebih Dahulu
Sebelum menerapkan logika berbasis scan ke production, validasi di lingkungan staging dengan dataset yang representatif. Verifikasi bahwa loop Anda benar-benar berhenti ketika cursor kembali ke 0.
7. Amankan Instans Redis Anda
Redis tidak boleh pernah terbuka ke internet publik tanpa autentikasi. Gunakan requirepass di konfigurasi Redis Anda, ikat ke localhost atau antarmuka jaringan pribadi, dan gunakan aturan firewall untuk membatasi akses.
Memilih Lingkungan Hosting yang Tepat untuk Redis
Performa Redis secara langsung terikat pada RAM yang tersedia, kecepatan CPU, dan latensi jaringan. Memilih infrastruktur hosting yang tepat sama pentingnya dengan menulis perintah Redis yang efisien.
- Pengembangan dan proyek kecil: Shared Web Hosting mungkin cukup untuk penggunaan Redis yang ringan, meskipun instance Redis yang didedikasikan selalu lebih disukai.
- Aplikasi yang berkembang: Paket VPS Hosting memberikan Anda sumber daya yang didedikasikan, akses root, dan kemampuan untuk menyesuaikan konfigurasi Redis (
maxmemory, pengaturan persistensi, dll.) sesuai kebutuhan Anda. - Sistem produksi dengan lalu lintas tinggi: Dedicated Servers menyediakan RAM dan sumber daya CPU maksimal yang dapat digunakan Redis, menghilangkan persaingan sumber daya sepenuhnya.
- Beban kerja AI dan ML menggunakan Redis sebagai vector store: GPU Hosting menawarkan kekuatan komputasi yang diperlukan untuk pembuatan embedding dan pencarian kesamaan bersama Redis.
Untuk aplikasi yang juga memerlukan panel kontrol web untuk manajemen yang lebih mudah, VPS dengan cPanel menyediakan antarmuka yang ramah pengguna bersama kontrol server penuh.
Pemecahan Masalah Umum
SCAN Mengembalikan 0 Elemen Berulang Kali
Ini biasanya berarti pola MATCH Anda tidak cocok dengan kunci apa pun, atau dataset kosong. Verifikasi penamaan kunci Anda dengan DBSIZE untuk memeriksa jumlah kunci total.
127.0.0.1:6379> DBSIZE
(integer) 15420Cursor Tidak Pernah Kembali ke 0
Ini seharusnya tidak terjadi pada instans Redis yang stabil. Jika terjadi, periksa kompatibilitas versi Redis (perintah scan memerlukan Redis 2.8+) atau gangguan koneksi yang mengatur ulang pelacakan kursor Anda.
Skrip Tergantung Tanpa Batas
Pastikan loop Anda membaca kursor dengan benar dari baris pertama output redis-cli. Kesalahan parsing yang selalu menghasilkan kursor bukan nol akan menyebabkan loop tak terbatas.
Kesimpulan
Redis scan commands — SCAN, SSCAN, HSCAN, dan ZSCAN — adalah alat yang sangat penting bagi setiap developer atau system administrator yang bekerja dengan Redis dalam skala besar di Linux. Mereka menyediakan mekanisme berbasis cursor yang aman dan non-blocking untuk iterasi melalui dataset besar tanpa risiko performa yang terkait dengan perintah seperti KEYS.
Dengan menggabungkan scan commands dengan pola MATCH, hints COUNT yang sesuai, dan shell scripts yang terstruktur dengan baik, Anda dapat membangun pipeline pemrosesan data yang efisien dan dapat diskalakan sesuai dengan ukuran dataset Anda. Mengikuti best practices yang diuraikan dalam panduan ini — khususnya seputar keamanan produksi, manajemen memori, dan pemilihan infrastruktur — akan memastikan deployment Redis Anda tetap performan dan andal.
Untuk opsi perintah terbaru dan detail konfigurasi lanjutan, selalu konsultasikan dokumentasi Redis resmi. Dan ketika Anda siap untuk menerapkan Redis di lingkungan Linux tingkat produksi, jelajahi VPS Hosting dan Dedicated Servers AlexHost untuk infrastruktur yang dibangun untuk menangani workload yang menuntut dan memory-intensive.


