Korzystanie z poleceń Scan w Redis w systemie Linux
Redis, open-source’owy magazyn struktur danych w pamięci, jest znany ze swojej szybkości i wszechstronności jako baza danych klucz-wartość. Jedną z jego potężnych funkcji jest możliwość przyrostowego iterowania przez zbiory danych za pomocą poleceń scan. Jest to szczególnie przydatne w przypadku dużych zbiorów danych, ponieważ pozwala na wydajne pobieranie danych bez obciążania serwera. Dla użytkowników na dedykowanym serwerze Linux, korzystanie z poleceń scan w Redis może zwiększyć wydajność obsługi danych, umożliwiając precyzyjne, zoptymalizowane pod kątem zasobów przetwarzanie zbiorów danych. W tym artykule zbadamy, jak skutecznie korzystać z poleceń scan w Redis w środowisku Linux, oferując szczegółowe przykłady i najlepsze praktyki w zakresie zarządzania i pobierania danych na dużą skalę.
Czym są polecenia scan?
Polecenia scan w Redis zapewniają sposób na iterację po kluczach, zestawach, hashach i posortowanych zestawach w sposób nieblokujący. W przeciwieństwie do polecenia KEYS, które może być niebezpieczne dla dużych zbiorów danych, ponieważ zwraca wszystkie pasujące klucze naraz, polecenia scan zwracają niewielką liczbę elementów naraz. Minimalizuje to wpływ na wydajność i pozwala na iterację przyrostową.
Kluczowe polecenia scan
- SCAN: Iteruje przez klucze w przestrzeni kluczy.
- SSCAN: Iteruje przez elementy w zbiorze.
- HSCAN: Iteruje przez pola i wartości w haszu.
- ZSCAN: Iteruje po elementach i wynikach w posortowanym zbiorze.
Podstawowa składnia poleceń scan
Każde polecenie scan ma podobną składnię:
- cursor: Liczba całkowita reprezentująca pozycję, od której należy rozpocząć skanowanie. Aby rozpocząć nowe skanowanie, należy użyć 0.
- MATCH pattern: (opcjonalnie) Wzorzec do filtrowania zwracanych kluczy. Obsługuje wzorce globalne.
- COUNT count: (opcjonalnie) Wskazówka dla Redis dotycząca liczby elementów zwracanych w każdej iteracji.
Instalacja Redis w systemie Linux
Dla CentOS/RHEL, użyj:
Po zainstalowaniu uruchom serwer Redis:
Łączenie się z Redis
Otwórz terminal i połącz się z instancją Redis za pomocą Redis CLI:
Możesz teraz wykonywać polecenia Redis w CLI.
Używanie polecenia SCAN
Przykład 1: Podstawowe SCAN
Aby pobrać wszystkie klucze w bazie danych Redis, można użyć:
SCAN 0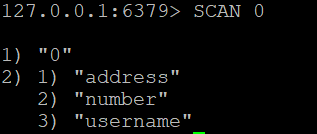
To polecenie zwróci kursor i listę kluczy.
Przykład 2: Używanie MATCH do filtrowania klawiszy
Jeśli chcesz znaleźć klucze pasujące do określonego wzorca, takie jak klucze zaczynające się od “user:”, możesz użyć:
To polecenie zwraca tylko klucze zaczynające się od “user:”.
Przykład 3: Określanie COUNT
Aby wskazać, ile kluczy Redis powinien zwrócić w każdej iteracji, można określić liczbę:
Spowoduje to próbę zwrócenia około 10 kluczy. Należy pamiętać, że rzeczywista liczba zwróconych kluczy może być mniejsza.
Przykład 4: Iteracja po wszystkich kluczach
Aby iterować przez wszystkie klucze w wielu iteracjach, należy śledzić zwracany kursor. Oto prosty przykład skryptu powłoki:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Przetwórz wynik zgodnie z potrzebami
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Zaktualizuj kursor
if [[ "$cursor" == "0" ]]; then
break # Zatrzymaj, gdy kursor powróci do 0
fi
doneUżywanie polecenia SSCAN
Polecenie SSCAN służy do iteracji po elementach zbioru. Jego składnia jest podobna do polecenia SCAN:
Przykład SSCAN
Krok 1: Utwórz zestaw i dodaj elementy
Utwórzmy zestaw o nazwie myset i dodajmy do niego kilka elementów:
SADD myset "apple"
SADD myset "banan"
SADD myset "cherry"
SADD myset "date"
SADD myset "elderberry"Krok 2: Użycie polecenia SSCAN
Teraz, gdy mamy zestaw o nazwie myset, możemy użyć polecenia SSCAN do iteracji po jego elementach.
- Podstawowe polecenie SSCAN: Załóżmy, że masz zestaw o nazwie “myset”. Aby przeskanować jego elementy:
SSCAN myset 0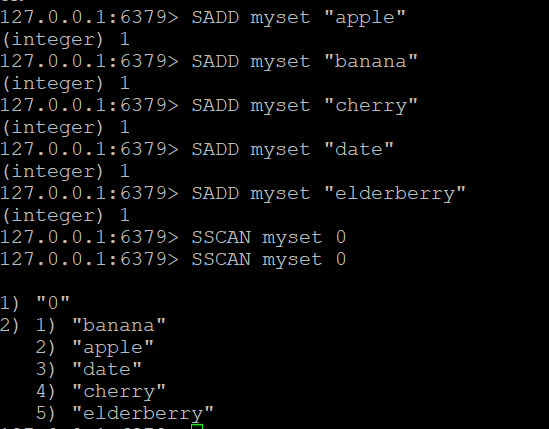
- Używanie MATCH:Aby przefiltrować elementy w zbiorze na podstawie wzorca i dodać elementy zawierające słowo “mango” i inne odmiany::
SSCAN myset 0 MATCH mango:*

- Iteracja po zbiorze:Możesz użyć pętli do iteracji po zbiorze:
#!/bin/bash
cursor=0
echo "Skanowanie przez myset:"
while true; do
# Skanowanie zestawu
result=$(redis-cli SSCAN myset $cursor)
# Wydrukuj elementy zwrócone przez SSCAN
echo "$result"
# Zaktualizuj kursor dla następnej iteracji
cursor=$(echo " $result " | awk 'NR==1{print $1}')
# Przerwij pętlę, jeśli kursor powróci do 0
if [[ "$cursor" == "0" ]]; then
break
fi
doneUruchamianie skryptu
- Zapisz skrypt jako scan_myset.sh.
- Uczyń go wykonywalnym:
- Uruchom skrypt:
./scan_myset.sh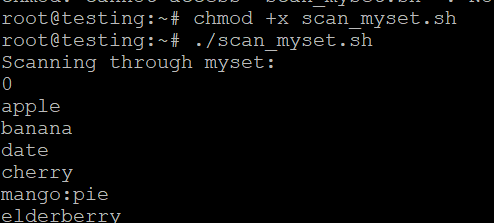

Korzystanie z poleceń HSCAN i ZSCAN
Polecenie HSCAN
Polecenie HSCAN iteruje przez pola i wartości w skrócie:
Polecenie HSCAN służy do iteracji przez pola i wartości w skrócie.
Krok 1: Tworzenie skrótu i dodawanie pól
- Utwórz hasz o nazwie myhash i dodaj do niego kilka pól:
Krok 2: Użyj HSCAN do iteracji przez Hash
- Użyj polecenia HSCAN, aby iterować przez pola w myhash:
HSCAN myhash 0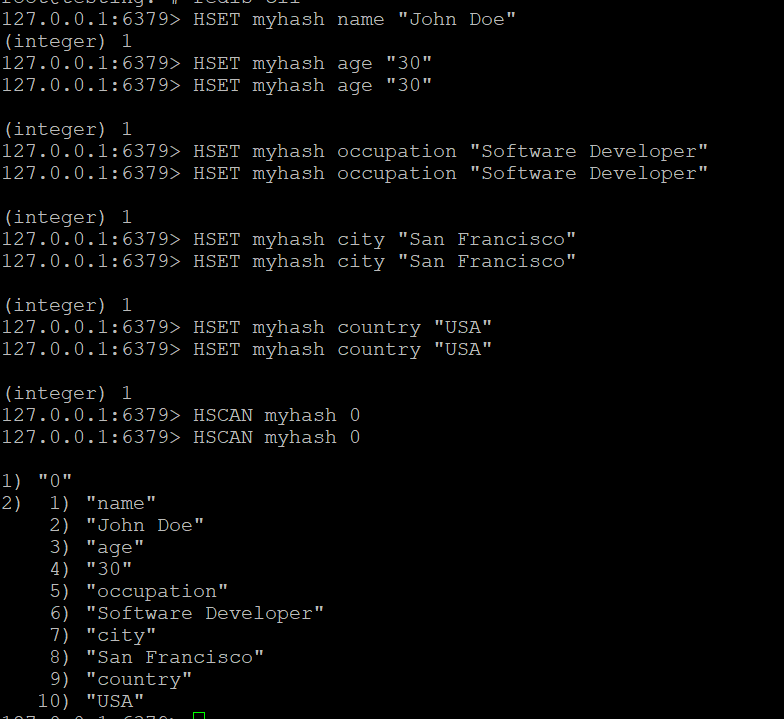
Polecenie ZSCAN
ZSCAN to polecenie Redis używane do iteracji przez elementy posortowanego zbioru przyrostowo. Umożliwia ono pobieranie elementów wraz z powiązanymi z nimi wynikami w sposób wydajny i nieblokujący. Polecenie to jest szczególnie przydatne do pracy z dużymi posortowanymi zbiorami, gdzie pobieranie wszystkich elementów jednocześnie może nie być praktyczne.
Polecenie ZSCAN iteruje po elementach i wynikach w posortowanym zbiorze:
Krok 1: Utwórz posortowany zestaw i dodaj członków
Stwórzmy posortowany zbiór o nazwie mysortedset i dodajmy kilku członków z wynikami:
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banan"
ZADD mysortedset 3 "cherry"Podstawowe polecenie ZSCAN:
Aby rozpocząć skanowanie posortowanego zestawu, użyj:
ZSCAN mysortedset 0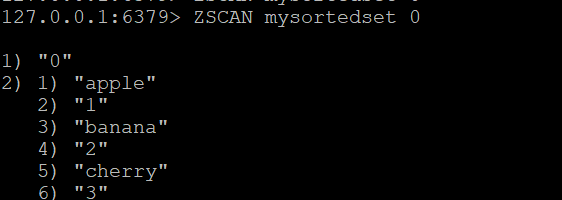
Krok 2: Używanie MATCH do filtrowania elementów (opcjonalnie)
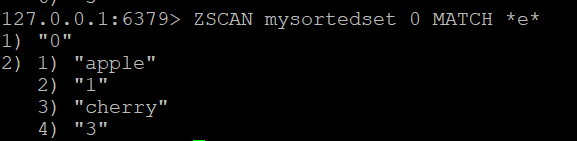
Jeśli chcesz filtrować pręty zwrócone przez ZSCAN, możesz użyć opcji MATCH. Na przykład, aby znaleźć pręty zawierające literę “e”, można uruchomić:
ZSCAN mysortedset 0 MATCH *e*