Utilizarea comenzilor Scan în Redis pe Linux
Redis, o platformă open-source de structuri de date în memorie, este cunoscută pentru viteza și versatilitatea sa ca bază de date cheie-valoare. Una dintre caracteristicile sale puternice este capacitatea de a parcurge incremental seturile de date utilizând comenzi scan. Acest lucru este deosebit de util atunci când aveți de-a face cu seturi mari de date, deoarece permite recuperarea eficientă a datelor fără a copleși serverul. Pentru utilizatorii de pe un server Linux dedicat, utilizarea comenzilor scan în Redis poate îmbunătăți performanța gestionării datelor, permițând procesarea precisă și optimizată a seturilor de date din punct de vedere al resurselor. În acest articol, vom explora modul de utilizare eficientă a comenzilor scan în Redis în cadrul unui mediu Linux, oferind exemple detaliate și cele mai bune practici pentru gestionarea și recuperarea datelor la scară…
Ce sunt comenzile de scan?
Comenzile de scan din Redis oferă o modalitate de a itera peste chei, seturi, hașuri și seturi sortate într-un mod neblocat. Spre deosebire de comanda KEYS, care poate fi periculoasă pentru seturile mari de date, deoarece returnează toate cheile potrivite deodată, comenzile scan returnează un număr mic de elemente odată. Acest lucru minimizează impactul asupra performanței și permite iterația incrementală.
Comenzi scan a cheilor
- SCAN: Iteră prin cheile din spațiul cheilor.
- SSCAN: Iteră prin elementele unui set.
- HSCAN: Trece prin câmpuri și valori într-un hash.
- ZSCAN: Iteră prin membri și scoruri într-un set sortat.
Sintaxa de bază a comenzilor scan
Fiecare comandă scan are o sintaxă similară:
- cursor: Un număr întreg care reprezintă poziția de la care începe scan. Pentru a începe o nouă scan, utilizați 0.
- MATCH pattern: (opțional) Un model pentru filtrarea cheilor returnate. Suportă modele de tip glob.
- COUNT count: (opțional) Un indiciu pentru Redis cu privire la câte elemente să returneze în fiecare iterație.
Instalarea Redis pe Linux
Pentru CentOS/RHEL, utilizați:
Odată instalat, porniți serverul Redis:
Conectarea la Redis
Deschideți terminalul și conectați-vă la instanța Redis utilizând Redis CLI:
Acum puteți executa comenzi Redis în CLI.
Utilizarea comenzii SCAN
Exemplul 1: SCAN de bază
Pentru a extrage toate cheile din baza de date Redis, puteți utiliza:
SCAN 0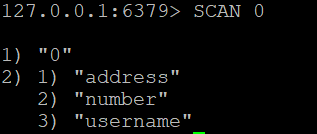
Această comandă va returna un cursor și o listă de taste.
Exemplul 2: Utilizarea MATCH pentru filtrarea tastelor
Dacă doriți să găsiți taste care corespund unui anumit model, cum ar fi taste care încep cu “user:”, puteți utiliza
Această comandă returnează numai cheile care încep cu “user:”.
Exemplul 3: Specificarea COUNT
Pentru a indica câte chei Redis ar trebui să returneze în fiecare iterație, puteți specifica un număr:
Aceasta va încerca să returneze aproximativ 10 chei. Rețineți că numărul real returnat poate fi mai mic decât acesta.
Exemplul 4: Iterarea prin toate cheile
Pentru a itera prin toate tastele în mai multe iterații, trebuie să țineți evidența cursorului returnat. Iată un exemplu simplu de script shell:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Procesează rezultatul după cum este necesar
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Actualizați cursorul
if [[ "$cursor" == "0" ]]; then
break # Oprește când cursorul revine la 0
fi
doneUtilizarea comenzii SSCAN
Comanda SSCAN este utilizată pentru a itera prin elementele unui set. Sintaxa sa este similară cu SCAN:
Exemplu de SSCAN
Pasul 1: Crearea unui set și adăugarea de elemente
Să creăm un set numit myset și să îi adăugăm câteva elemente:
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "data"
SADD myset "elderberry"Pasul 2: Utilizați comanda SSCAN
Acum că avem un set numit myset, putem utiliza comanda SSCAN pentru a parcurge elementele acestuia.
- Comanda de bază SSCAN: Să presupunem că aveți un set numit “myset”. Pentru a parcurge elementele acestuia:
SSCAN myset 0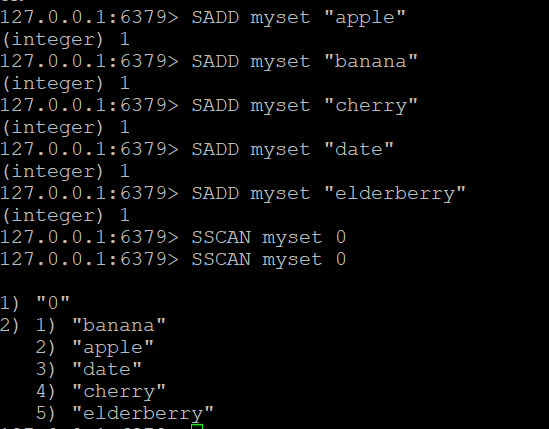
- Utilizarea MATCH: Pentru a filtra elementele dintr-un set pe baza unui model și a adăuga unele elemente care includ cuvântul “mango” și alte variante::
SSCAN myset 0 MATCH mango:*

- Iterarea printr-un set: Puteți utiliza o buclă pentru a itera printr-un set :
#!/bin/bash
cursor=0
echo "Scan prin myset:"
while true; do
# Scanează setul
result=$(redis-cli SSCAN myset $cursor)
# Tipăriți elementele returnate de SSCAN
echo "$rezultat"
# Actualizați cursorul pentru următoarea iterație
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Întrerupe bucla dacă cursorul revine la 0
if [[ "$cursor" == "0" ]]; then
pauză
fi
doneRularea scriptului
- Salvați scriptul ca scan_myset.sh.
- Faceți-l executabil:
- Rulați scriptul:
./scan_myset.sh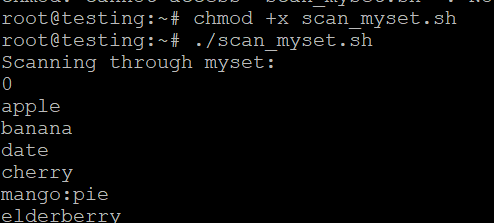

Utilizarea comenzilor HSCAN și ZSCAN
Comanda HSCAN
Comanda HSCAN itera prin câmpurile și valorile dintr-un hash:
Comanda HSCAN este utilizată pentru a parcurge câmpurile și valorile dintr-un hash.
Pasul 1: Crearea unui Hash și adăugarea de câmpuri
- Creați un hash numit myhash și adăugați câteva câmpuri la acesta:
Pasul 2: Utilizați HSCAN pentru a itera prin hash
- Utilizați comanda HSCAN pentru a trece prin câmpurile din myhash:
HSCAN myhash 0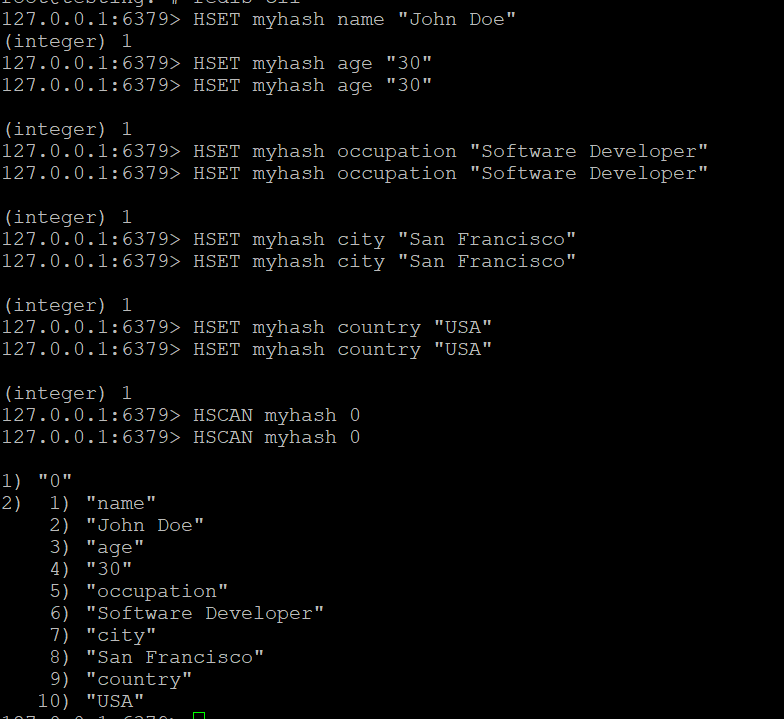
Comanda ZSCAN
ZSCAN este o comandă Redis utilizată pentru a trece prin membrii unui set sortat în mod incremental. Aceasta vă permite să recuperați membrii împreună cu scorurile asociate acestora într-un mod eficient și neblocat. Această comandă este deosebit de utilă pentru lucrul cu seturi sortate mari, în cazul în care recuperarea tuturor membrilor dintr-o dată nu este practică.
Comanda ZSCAN itera prin membrii și scorurile unui set sortat:
Pasul 1: Crearea unui set sortat și adăugarea de membri
Să creăm un set sortat numit mysortedset și să adăugăm câțiva membri cu scoruri:
ZADD mysortedset 1 "măr"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "cherry"Comanda de bază ZSCAN:
Pentru a începe scanarea setului sortat, utilizați:
ZSCAN mysortedset 0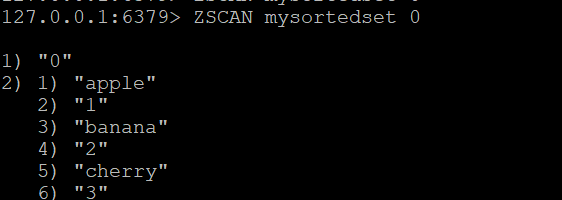
Pasul 2: Utilizarea MATCH pentru filtrarea membrilor (opțional)
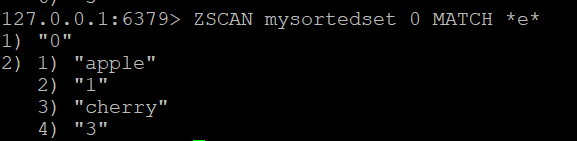
Dacă doriți să filtrați membrii returnați de ZSCAN, puteți utiliza opțiunea MATCH. De exemplu, pentru a găsi membri care conțin litera “e”, puteți rula:
ZSCAN mysortedset 0 MATCH *e*