28.03.2025
Comment se connecter à votre serveur dédié GPU
la connexion à un serveur dédié GPU d’AlexHost est un processus composé de plusieurs étapes : du choix du bon tarif à la mise en place et au démarrage du travail. Vous trouverez ci-dessous les principales étapes pour réussir à vous connecter et à utiliser le serveur
Choisir le bon tarif
AlexHost propose deux tarifs pour les serveurs dédiés au GPU 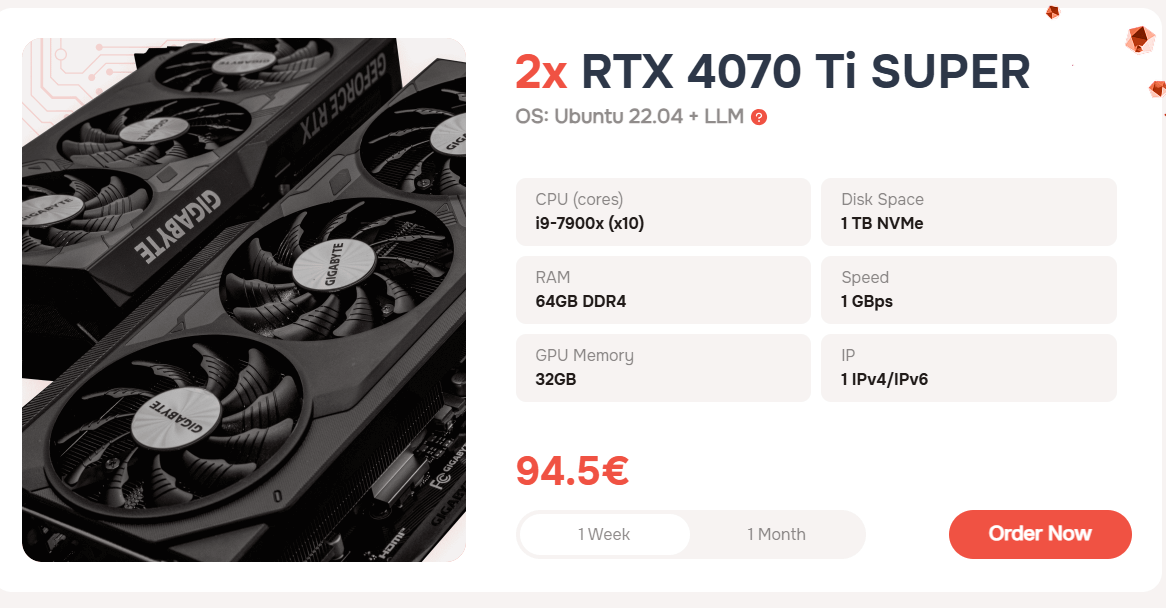
Les serveurs dédiés sont fournis avec deux cartes vidéo puissantes et modernes 2x RTX 4070 Ti SUPER. Un autre élément important est qu’AlexHost fournit un ensemble complet d’outils et de cadres préinstallés spécialement conçus pour rationaliser le déploiement et l’utilisation de grands modèles de langage (LLM), vous permettant de commencer à travailler avec des solutions d’IA immédiatement. Cela vous aidera à obtenir un serveur avec un outil d’IA déployable immédiatement.
- Interface utilisateur d’Oobabooga Text Gen
- PyTorch (CUDA 12.4 + cuDNN)
- SD Webui A1111
- Ubuntu 22.04 VM : Bureau GNOME + RDPBureau XFCE + RDPBureau Plasma RDPKDE + RDP
- En outre : A la demande, nous pouvons installer n’importe quel système d’exploitation
Comment se connecter à votre serveur GPU
Une fois le paiement effectué, vous recevrez un accès au serveur et des informations d’identification à votre adresse e-mail. Nous sommes également prêts à vous fournir des instructions sur la façon dont vous pouvez vous connecter à votre serveur dédié GPU. Les instructions sont très simples, il suffit de suivre les étapes suivantes, qui sont décrites ci-dessous.
Ainsi, après avoir commandé avec succès un serveur GPU, vous pouvez aller sur votre compte et le sélectionner dans la liste des services activés. Ensuite, ouvrez-le en cliquant sur le service sélectionné.
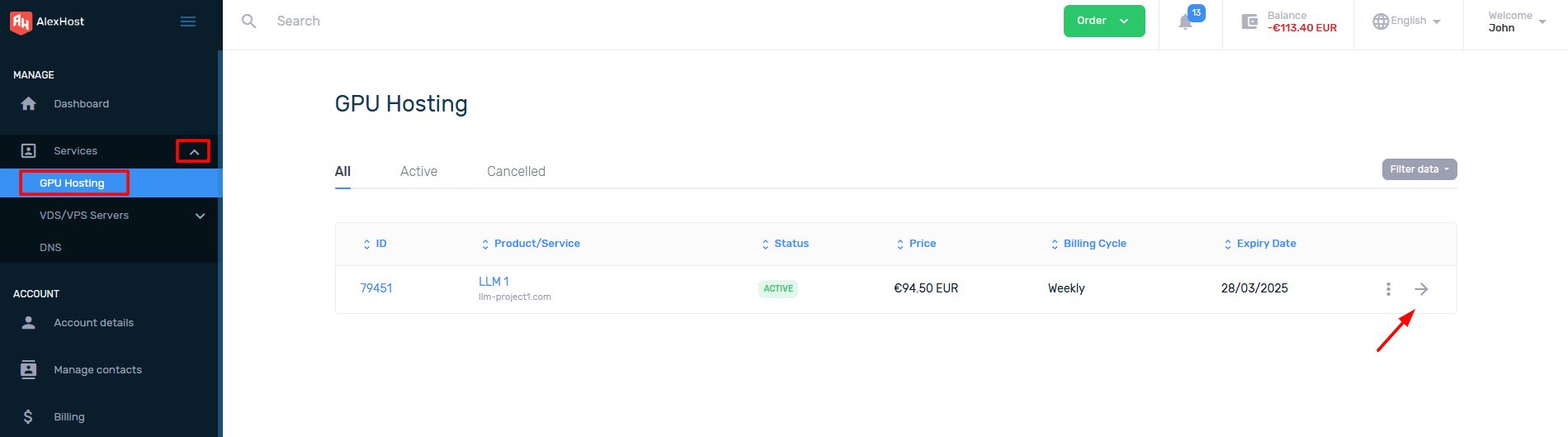
Pour voir les identifiants de connexion à DCIManager, vous devez aller à la section Détails de connexion
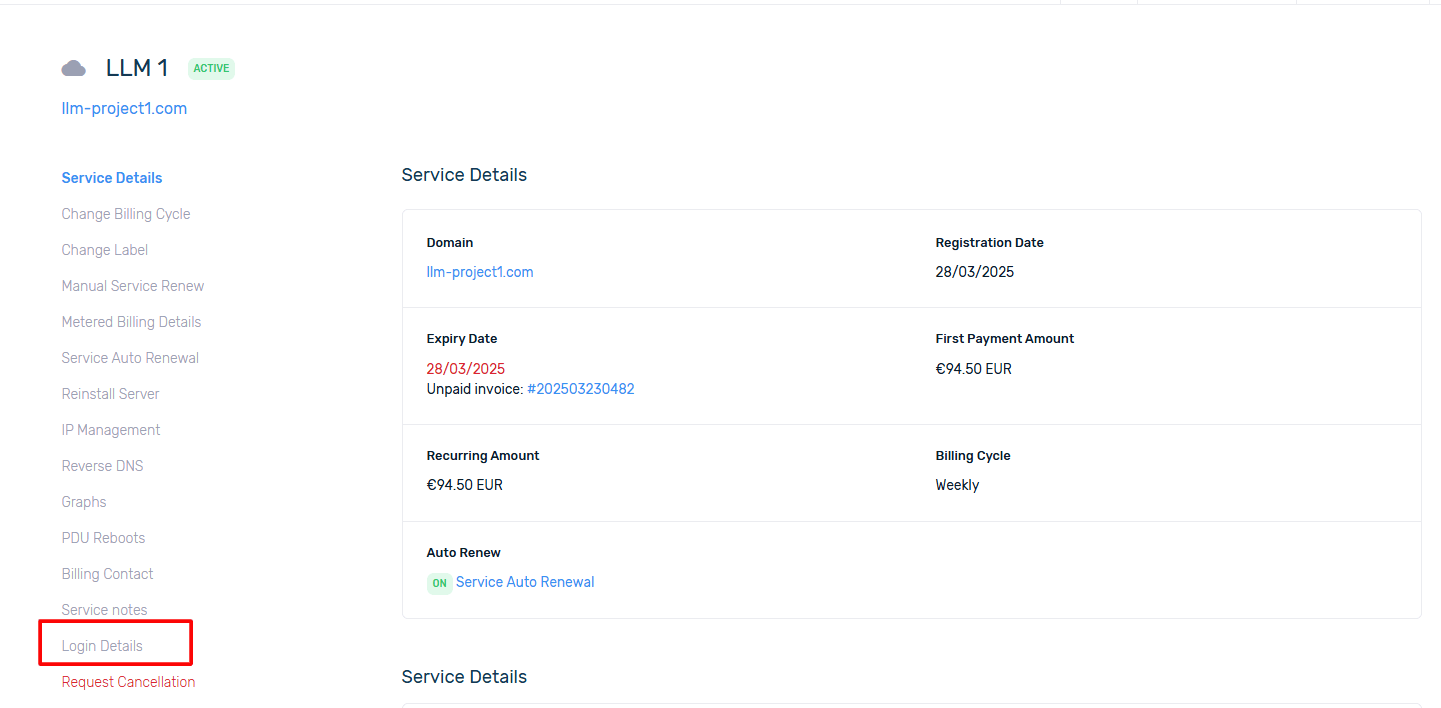
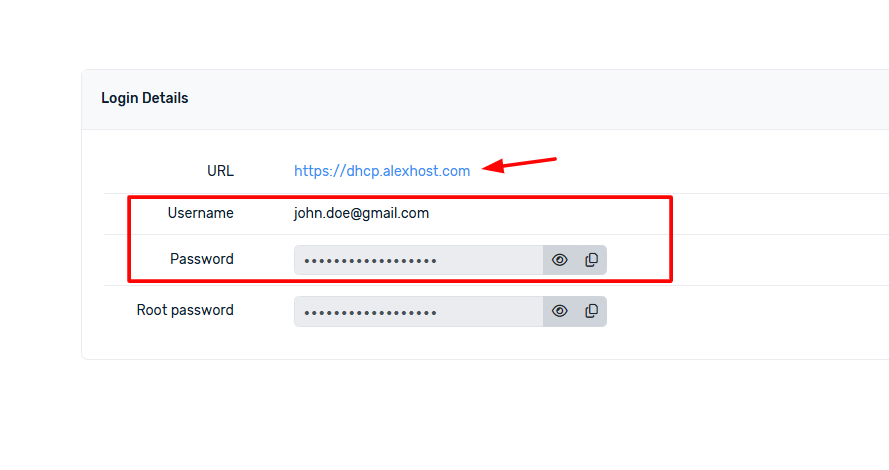
Vous pourrez suivre le lien fourni dans votre compte et y voir le nom d’utilisateur et le mot de passe correspondant.
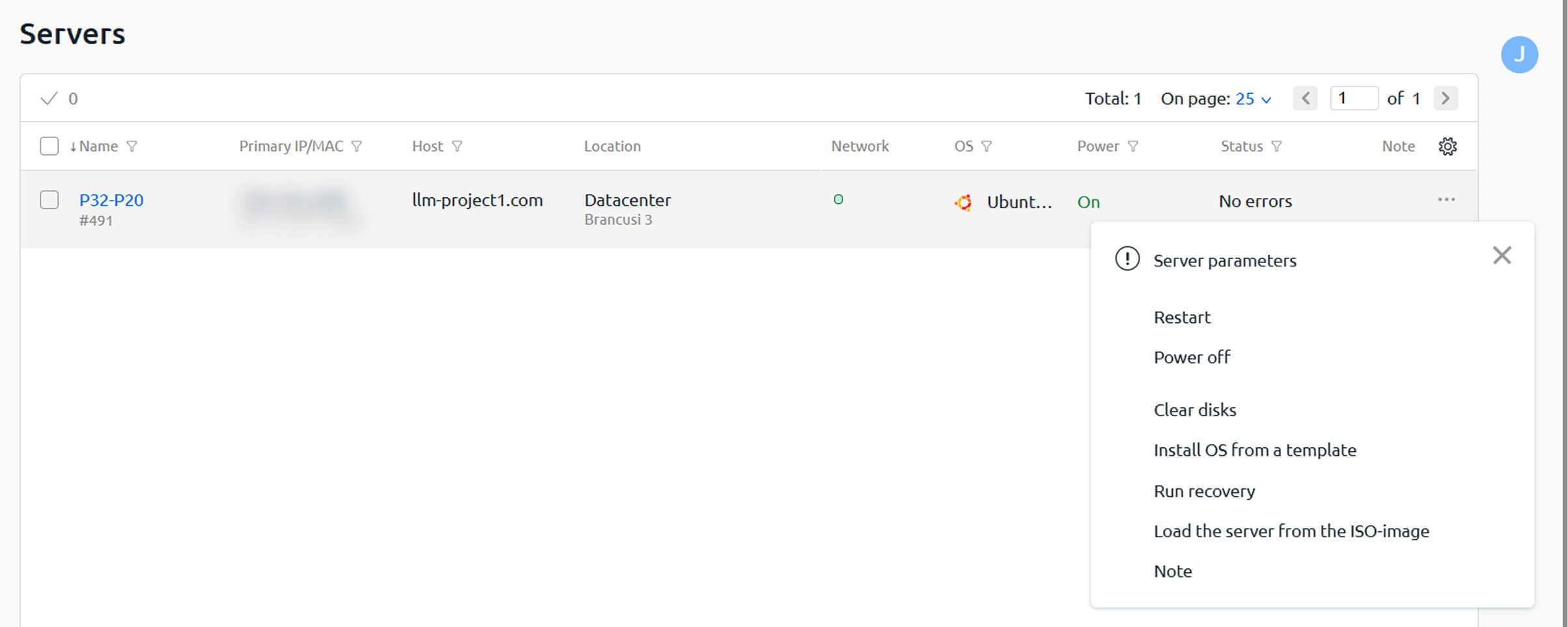
Après avoir sélectionné les trois points, vous devez cliquer sur Installer le système d’exploitation à partir d’un modèle pour afficher les modèles de système d’exploitation et de LLM disponibles
Vous pouvez installer n’importe quel système d’exploitation disponible dans la liste des modèles sur votre serveur GPU. Actuellement, les cadres et les outils permettant de travailler avec de grands modèles de langage (LLM) ne sont pris en charge que sur Ubuntu 22.04. Lorsque ce système d’exploitation est sélectionné, les scripts d’installation correspondants pour les cadres LLM sont disponibles pour sélection pendant l’installation.
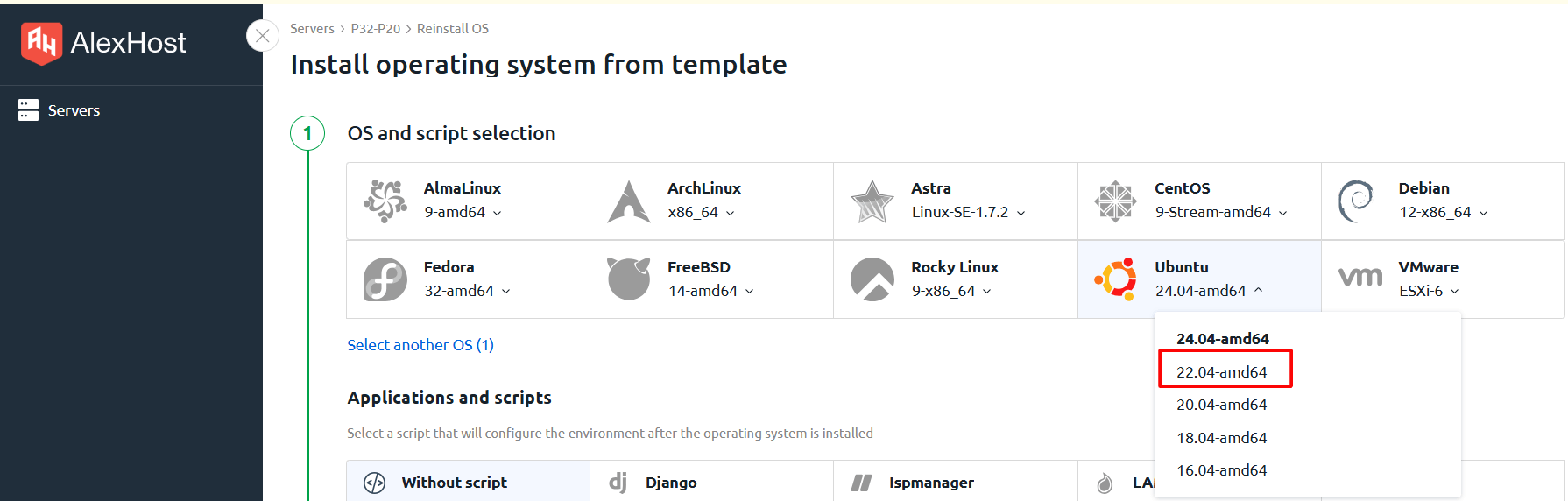
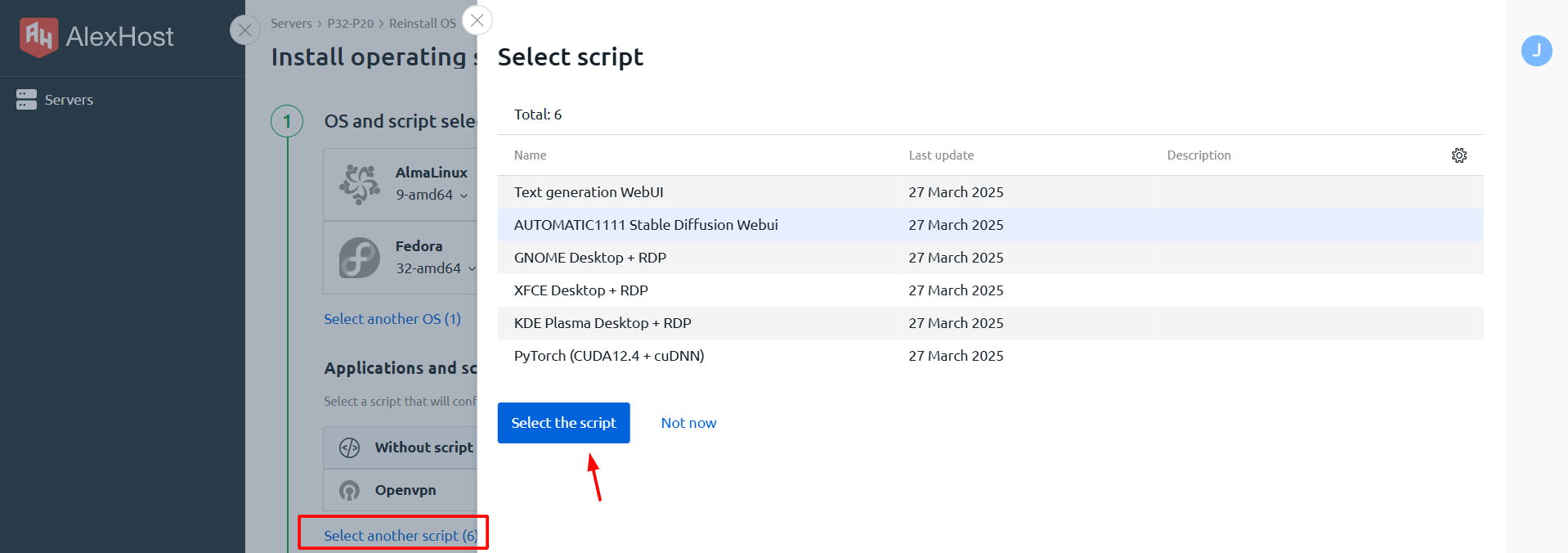
En sélectionnant l’option Sélectionner un autre script, vous aurez accès à l’installation de tous les modèles LLM disponibles. Jetons un coup d’œil rapide à chacun d’entre eux :
- Génération de texte WebUI est une interface web pour travailler avec des modèles de génération de texte tels que GPT, LLaMA, Mistral et d’autres. Elle vous permet de charger des modèles, de configurer des paramètres et d’interagir avec les LLM de texte.
- AUTOMATIC1111 Stable Diffusion WebUI est l’une des interfaces web les plus populaires pour générer des images à l’aide du modèle de diffusion stable. Elle fournit une interface graphique pratique dans laquelle vous pouvez charger des modèles, configurer les paramètres de génération d’images, utiliser des plugins et des extensions supplémentaires.
- GNOME / XFCE / KDE Plasma Desktop + RDP sont divers environnements graphiques pour la connexion à distance au serveur via RDP (Remote Desktop Protocol). Ils ne sont pas directement liés à LLM, mais peuvent être utilisés pour gérer et travailler avec le serveur sur lequel les modèles d’IA sont exécutés.
- PyTorch (CUDA12.4 + cuDNN) est une bibliothèque permettant de travailler avec les réseaux neuronaux et l’apprentissage automatique. Elle prend en charge l’accélération GPU (via CUDA) et est utilisée pour entraîner et exécuter des LLM (par exemple GPT, LLaMA) et des modèles de génération d’images (Stable Diffusion).
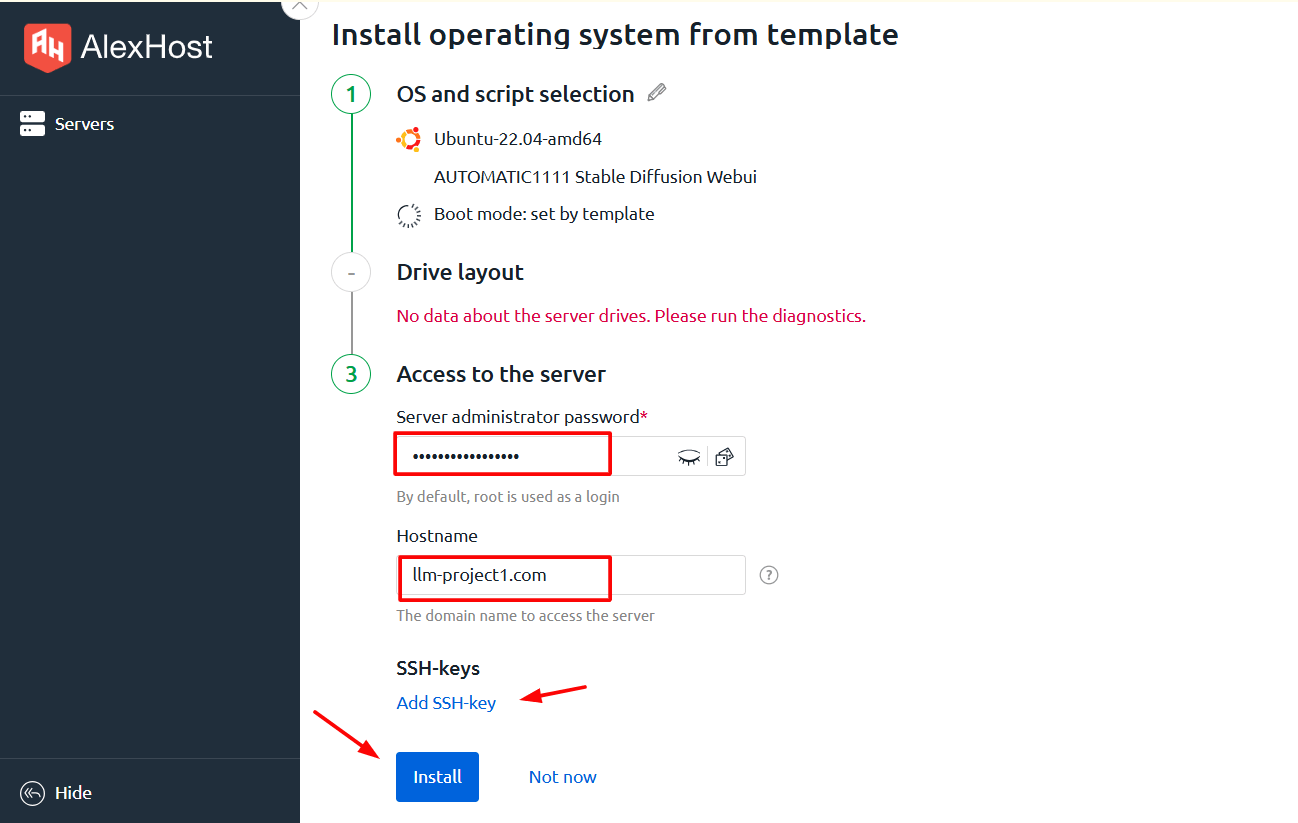
La dernière étape consiste à choisir un mot de passe et un nom d’hôte. Après avoir rempli ces champs, vous pouvez continuer l’installation.
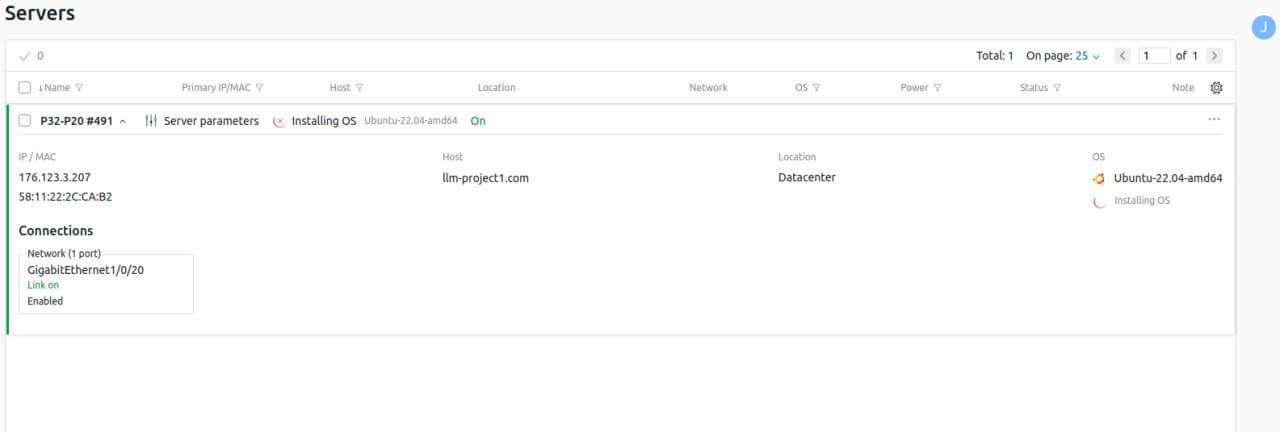
Une installation réussie ressemble exactement à ceci. Veuillez noter que le processus d’installation peut durer jusqu’à 30 minutes.