Verwendung der Scan-Befehle in Redis unter Linux
Redis, ein Open-Source-Speicher für Datenstrukturen im Arbeitsspeicher, ist bekannt für seine Geschwindigkeit und Vielseitigkeit als Key-Value-Datenbank. Eine seiner leistungsstarken Funktionen ist die Möglichkeit, mit scan Befehlen inkrementell durch Datensätze zu iterieren. Dies ist besonders bei großen Datenmengen nützlich, da es eine effiziente Datenabfrage ermöglicht, ohne den Server zu überlasten. Für Benutzer eines dedizierten Linux-Servers kann die Verwendung von scan Befehlen in Redis die Leistung der Datenverarbeitung verbessern, indem sie eine präzise, ressourcenoptimierte Verarbeitung von Datensätzen ermöglicht. In diesem Artikel wird untersucht, wie scan Befehle in Redis in einer Linux-Umgebung effektiv eingesetzt werden können. Es werden detaillierte Beispiele und Best Practices für die Verwaltung und den Abruf von Daten in großem Umfang vorgestellt.
Was sind scan Befehle?
Die scan Befehle in Redis bieten eine Möglichkeit, über Schlüssel, Sets, Hashes und sortierte Sets in einer nicht-blockierenden Weise zu iterieren. Im Gegensatz zum KEYS-Befehl, der bei großen Datenmengen gefährlich sein kann, weil er alle übereinstimmenden Schlüssel auf einmal zurückgibt, geben scan Befehle jeweils nur eine kleine Anzahl von Elementen zurück. Dies minimiert die Auswirkungen auf die Leistung und ermöglicht eine inkrementelle Iteration.
Schlüssel scan Befehle
- SCAN: Iteriert durch die Schlüssel im Schlüsselraum.
- SSCAN: Iteriert durch die Elemente in einer Menge.
- HSCAN: Iteriert durch Felder und Werte in einem Hash.
- ZSCAN: Iteriert durch Mitglieder und Werte in einer sortierten Menge.
Grundsyntax der scan Befehle
Jeder Scan-Befehl hat eine ähnliche Syntax:
- cursor: Eine ganze Zahl, die die Position angibt, an der der Scanvorgang beginnen soll. Um eine neue Suche zu starten, verwenden Sie 0.
- MATCH pattern: (optional) Ein Muster zum Filtern der zurückgegebenen Schlüssel. Unterstützt glob-style Muster.
- COUNT Anzahl: (optional) Ein Hinweis an Redis, wie viele Elemente in jeder Iteration zurückgegeben werden sollen.
Installation von Redis unter Linux
Für CentOS/RHEL, verwenden Sie:
Nach der Installation starten Sie den Redis-Server:
Verbinden mit Redis
Öffnen Sie Ihr Terminal und verbinden Sie sich mit Ihrer Redis-Instanz über die Redis-CLI:
Sie können nun Redis-Befehle in der CLI ausführen.
Verwendung des SCAN-Befehls
Beispiel 1: Grundlegender SCAN
Um alle Schlüssel in der Redis-Datenbank abzurufen, können Sie verwenden:
SCAN 0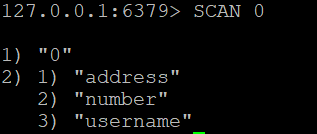
Dieser Befehl gibt einen Cursor und eine Liste der Schlüssel zurück.
Beispiel 2: Verwendung von MATCH zum Filtern von Schlüsseln
Wenn Sie nach Schlüsseln suchen möchten, die einem bestimmten Muster entsprechen, wie z. B. Schlüssel, die mit “user:” beginnen, können Sie MATCH verwenden:
Dieser Befehl gibt nur die Schlüssel zurück, die mit “user:” beginnen.
Beispiel 3: Angeben von COUNT
Um anzudeuten, wie viele Schlüssel Redis in jeder Iteration zurückgeben soll, können Sie eine Anzahl angeben:
Damit wird versucht, etwa 10 Schlüssel zurückzugeben. Beachten Sie, dass die tatsächlich zurückgegebene Anzahl geringer sein kann.
Beispiel 4: Iteration durch alle Schlüssel
Um alle Schlüssel in mehreren Iterationen zu durchlaufen, müssen Sie den zurückgegebenen Cursor verfolgen. Hier ist ein einfaches Beispiel für ein Shell-Skript:
cursor=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Verarbeitet das Ergebnis nach Bedarf
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Aktualisieren des Cursors
if [[ "$cursor" == "0" ]]; then
break # Anhalten, wenn der Cursor wieder auf 0 steht
fi
doneVerwendung des SSCAN-Befehls
Der SSCAN-Befehl wird verwendet, um durch die Elemente einer Menge zu iterieren. Die Syntax ist ähnlich wie bei SCAN:
Beispiel für SSCAN
Schritt 1: Ein Set erstellen und Elemente hinzufügen
Erstellen wir eine Menge namens myset und fügen wir ihr einige Elemente hinzu:
SADD myset "Apfel"
SADD Myset "Banane"
SADD myset "Kirsche"
SADD Myset "Dattel"
SADD myset "Holunder"Schritt 2: Verwenden Sie den SSCAN-Befehl
Da wir nun eine Menge mit dem Namen myset haben, können wir den Befehl SSCAN verwenden, um die Elemente dieser Menge zu durchlaufen.
- Grundlegender SSCAN-Befehl:Angenommen, Sie haben eine Menge namens “myset”. Um seine Elemente zu durchsuchen:
SSCAN myset 0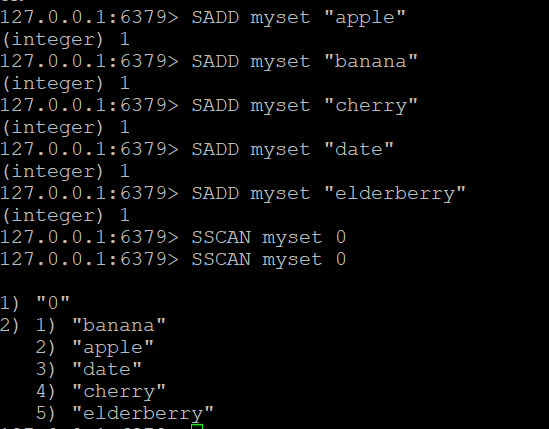
- MATCH verwenden:Um die Elemente in einer Menge anhand eines Musters zu filtern und einige Elemente hinzuzufügen, die das Wort “Mango” und andere Variationen enthalten::
SSCAN myset 0 MATCH mango:*

- Iterieren durch eine Menge: Sie können eine Schleife verwenden, um durch eine Menge zu iterieren:
#!/bin/bash
cursor=0
echo "Scannen durch myset:"
while true; do
# Scannen der Menge
result=$(redis-cli SSCAN myset $cursor)
# Druckt die von SSCAN zurückgegebenen Elemente
echo "$result"
# Aktualisieren des Cursors für die nächste Iteration
cursor=$(echo "$Ergebnis" | awk 'NR==1{print $1}')
# Die Schleife unterbrechen, wenn der Cursor wieder auf 0 steht
if [[ "$cursor" == "0" ]]; then
break
fi
doneAusführen des Skripts
- Speichern Sie das Skript als scan_myset.sh.
- Machen Sie es ausführbar:
- Führen Sie das Skript aus:
./scan_myset.sh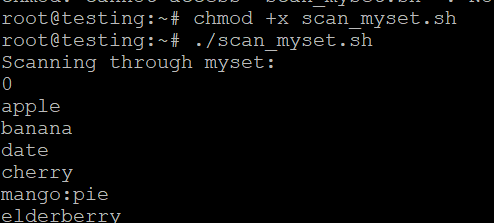

Verwendung der HSCAN- und ZSCAN-Befehle
HSCAN-Befehl
Der HSCAN-Befehl iteriert durch Felder und Werte in einem Hash:
Der HSCAN-Befehl wird verwendet, um Felder und Werte in einem Hash zu durchlaufen.
Schritt 1: Einen Hash erstellen und Felder hinzufügen
- Erstellen Sie einen Hash mit dem Namen myhash und fügen Sie ihm einige Felder hinzu:
Schritt 2: HSCAN verwenden, um durch die Hash zu iterieren
- Verwenden Sie den HSCAN-Befehl, um durch die Felder in myhash zu iterieren:
HSCAN myhash 0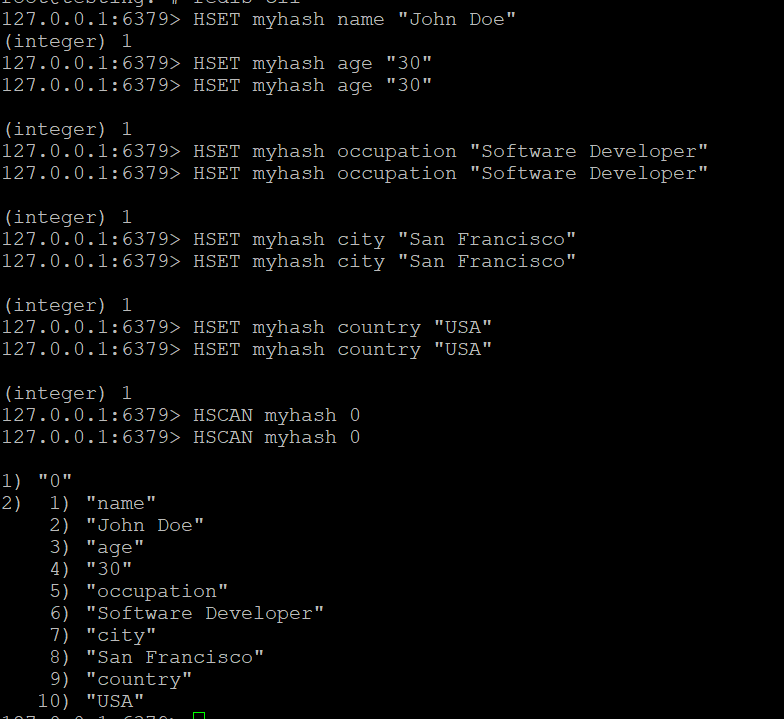
ZSCAN-Befehl
ZSCAN ist ein Redis-Befehl, mit dem die Mitglieder einer sortierten Menge inkrementell durchlaufen werden können. Er ermöglicht es Ihnen, Mitglieder zusammen mit ihren zugehörigen Bewertungen auf eine effiziente und nicht blockierende Weise abzurufen. Dieser Befehl ist besonders nützlich für die Arbeit mit großen sortierten Mengen, bei denen das Abrufen aller Mitglieder auf einmal nicht praktikabel ist.
Der ZSCAN-Befehl iteriert durch die Mitglieder und Punktzahlen in einer sortierten Menge:
Schritt 1: Eine sortierte Menge erstellen und Mitglieder hinzufügen
Erstellen wir eine sortierte Menge namens mysortedset und fügen wir einige Mitglieder mit Bewertungen hinzu:
ZADD mysortedset 1 "Apfel"
ZADD mysortedset 2 "Banane"
ZADD mysortedset 3 "Kirsche"Grundlegender ZSCAN-Befehl:
Um das Scannen des sortierten Satzes zu starten, verwenden Sie:
ZSCAN mysortedset 0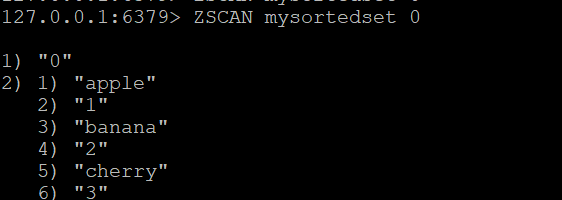
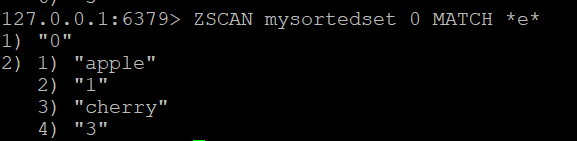
Schritt 2: MATCH zum Filtern von Mitgliedern verwenden (optional)
Wenn Sie die von ZSCAN zurückgegebenen Mitglieder filtern möchten, können Sie die Option MATCH verwenden. Um zum Beispiel Mitglieder zu finden, die den Buchstaben “e” enthalten, können Sie MATCH ausführen:
ZSCAN mysortedset 0 MATCH *e*