Използване на командите за Scan в Redis под Linux
Redis, хранилище на структури от данни с отворен код в паметта, е известно със своята скорост и гъвкавост като база данни ключ-стойност. Една от мощните му функции е възможността за инкрементална итерация през набори от данни с помощта на команди за scan. Това е особено полезно при работа с големи масиви от данни, тъй като позволява ефективно извличане на данни, без да се претоварва сървърът. За потребителите на специализиран Linux сървър използването на команди за scan в Redis може да подобри производителността на работата с данни, като позволи прецизна и оптимизирана по отношение на ресурсите обработка на набори от данни. В тази статия ще разгледаме как ефективно да използваме командите за scan в Redis в среда на Linux, като предлагаме подробни примери и най-добри практики за управление и извличане на данни в мащаба на..
Какво представляват командите за scan?
Командите за scan в Redis осигуряват начин за итерация над ключове, множества, хешове и сортирани множества по неблокиращ начин. За разлика от командата KEYS, която може да бъде опасна за големи масиви от данни, тъй като връща всички съвпадащи ключове наведнъж, командите за scan връщат малък брой елементи наведнъж. Това свежда до минимум въздействието върху производителността и позволява инкрементална итерация.
Команди за scan на ключове
- SCAN: Итерира през ключовете в пространството от ключове.
- SSCAN: Итервюира елементи в множество.
- HSCAN: Преминава през полета и стойности в хеш.
- ZSCAN: Итерсира през членове и резултати в сортирано множество.
Основен синтаксис на командите за scan
Всяка команда за scan има подобен синтаксис:
- курсор: Цяло число, което представлява позицията, от която да започне scanто. За да започнете ново scan, използвайте 0.
- MATCH pattern: (незадължително) Модел за филтриране на върнатите ключове. Поддържа шаблони в стил glob.
- COUNT count (брой): (незадължително) Указание към Redis колко елемента да бъдат върнати при всяка итерация.
Инсталиране на Redis в Linux
За CentOS/RHEL използвайте:
След като инсталирате, стартирайте сървъра Redis:
Свързване с Redis
Отворете терминала и се свържете с вашата инстанция на Redis, като използвате Redis CLI:
Сега можете да изпълнявате команди на Redis в CLI.
Използване на командата SCAN
Пример 1: Основен SCAN
За да извлечете всички ключове в базата данни Redis, можете да използвате:
SCAN 0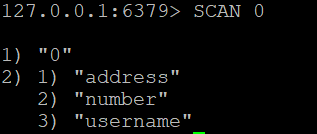
Тази команда ще върне курсор и списък с ключове.
Пример 2: Използване на MATCH за филтриране на клавишите
Ако искате да намерите ключове, които отговарят на определен модел, например ключове, които започват с “user:”, можете да използвате:
Тази команда връща само ключовете, които започват с “user:”.
Пример 3: Задаване на COUNT
За да укажете колко ключа трябва да върне Redis при всяка итерация, можете да зададете брой:
Това ще се опита да върне приблизително 10 ключа. Имайте предвид, че действителният брой върнати ключове може да е по-малък от този.
Пример 4: Итериране през всички ключове
За да преминете през всички клавиши в няколко итерации, трябва да следите върнатия курсор. Ето един прост пример за шел скрипт:
курсор=0
while true; do
result=$(redis-cli SSCAN myset $cursor MATCH apple:*)
echo "$result" # Обработва резултата, както е необходимо
cursor=$(echo "$result" | awk 'NR==1{print $1}') # Актуализиране на курсора
if [[ "$cursor" == "0" ]]; then
break # Спрете, когато курсорът се върне на 0
fi
done
Използване на командата SSCAN
Командата SSCAN се използва за итериране на елементи от дадено множество. Синтаксисът ѝ е подобен на този на SCAN:
Пример за SSCAN
Стъпка 1: Създаване на набор и добавяне на елементи
Нека да създадем множество, наречено myset, и да добавим някои елементи към него:
SADD myset "apple"
SADD myset "banana"
SADD myset "cherry"
SADD myset "date"
SADD myset "бъз"Стъпка 2: Използване на командата SSCAN
Сега, след като имаме набор с име myset, можем да използваме командата SSCAN, за да преминем през неговите елементи.
- Основна команда SSCAN:Да предположим, че имате множество, наречено “myset”. За да прегледате елементите му:
SSCAN myset 0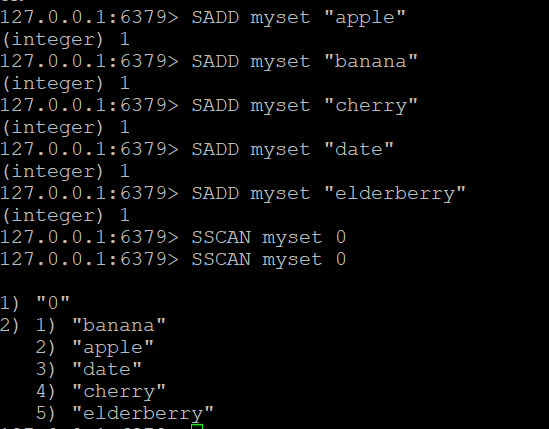
- Използване на MATCH: За да филтрирате елементите в множеството въз основа на шаблон и да добавите някои елементи, които включват думата “манго” и други варианти::
SSCAN myset 0 MATCH mango:*

- Итерация през множество: Можете да използвате цикъл, за да итерирате през множество:
#!/bin/bash
cursor=0
echo "Сканиране през myset:"
while true; do
# Сканиране на набора
result=$(redis-cli SSCAN myset $cursor)
# Отпечатайте елементите, върнати от SSCAN
echo "$result"
# Актуализирайте курсора за следващата итерация
cursor=$(echo "$result" | awk 'NR==1{print $1}')
# Прекъснете цикъла, ако курсорът се върне на 0
if [[ "$cursor" == "0" ]]; then
break
fi
done
Изпълнение на скрипта
- Запишете скрипта като scan_myset.sh.
- Направете го изпълним:
- Изпълнете скрипта:
./scan_myset.sh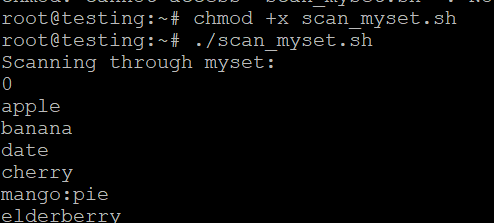

Използване на командите HSCAN и ZSCAN
Команда HSCAN
Командата HSCAN итерира през полетата и стойностите в хеша:
Командата HSCAN се използва за итерация през полета и стойности в хеш.
Стъпка 1: Създаване на хеш и добавяне на полета
- Създайте хеш с име myhash и добавете няколко полета към него:
Стъпка 2: Използвайте HSCAN за итерация през хеша
- Използвайте командата HSCAN, за да преминете през полетата в myhash:
HSCAN myhash 0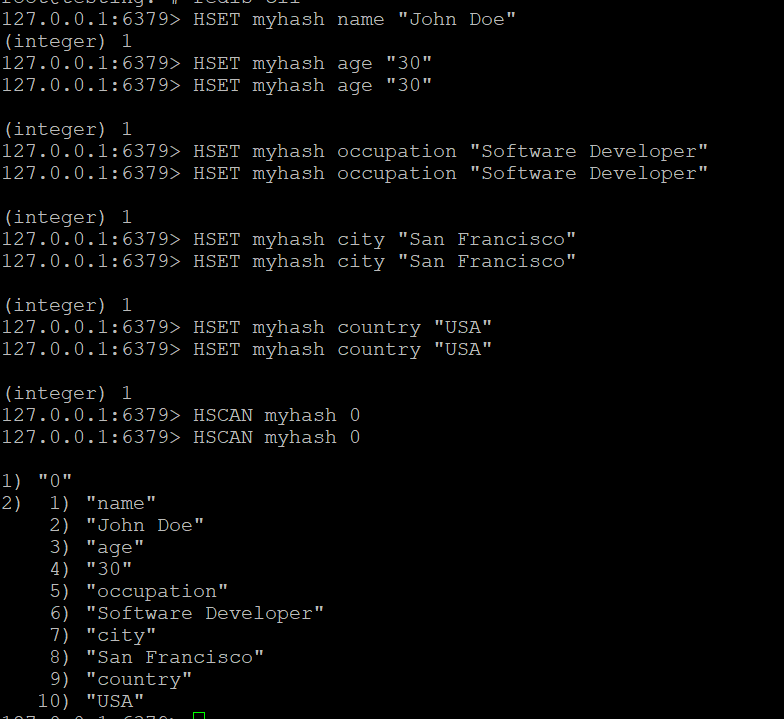
Команда ZSCAN
ZSCAN е команда на Redis, която се използва за инкрементално преминаване през членовете на сортирано множество. Тя ви позволява да извличате членовете заедно със свързаните с тях оценки по ефективен и неблокиращ начин. Тази команда е особено полезна за работа с големи сортирани множества, при които извличането на всички членове наведнъж може да не е практично.
Командата ZSCAN итерира през членовете и точките в сортирано множество:
Стъпка 1: Създаване на сортирано множество и добавяне на членове
Нека да създадем сортирано множество, наречено mysortedset , и да добавим някои членове с оценки:
ZADD mysortedset 1 "apple"
ZADD mysortedset 2 "banana"
ZADD mysortedset 3 "череша"Основна команда ZSCAN:
За да започнете scanто на сортирания набор, използвайте:
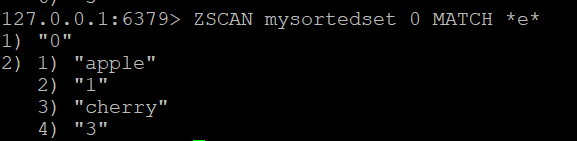
ZSCAN mysortedset 0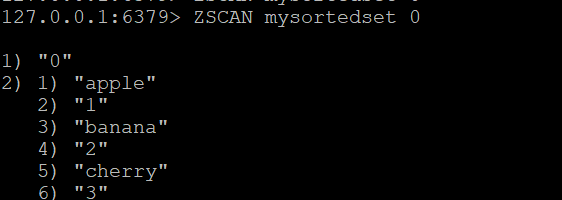
Стъпка 2: Използване на MATCH за филтриране на членовете (по избор)
Ако искате да филтрирате членовете, върнати от ZSCAN, можете да използвате опцията MATCH. Например, за да намерите членове, които съдържат буквата “д”, можете да изпълните:
ZSCAN mysortedset 0 MATCH *e*